 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Epistemic Friction in Dialogue
Jun 12, 2025Recent developments in aligning Large Language Models (LLMs) with human preferences have significantly enhanced their utility in human-AI collaborative scenarios. However, such approaches often neglect the critical role of "epistemic friction," or the inherent resistance encountered when updating beliefs in response to new, conflicting, or ambiguous information. In this paper, we define dynamic epistemic friction as the resistance to epistemic integration, characterized by the misalignment between an agent's current belief state and new propositions supported by external evidence. We position this within the framework of Dynamic Epistemic Logic (Van Benthem and Pacuit, 2011), where friction emerges as nontrivial belief-revision during the interaction. We then present analyses from a situated collaborative task that demonstrate how this model of epistemic friction can effectively predict belief updates in dialogues, and we subsequently discuss how the model of belief alignment as a measure of epistemic resistance or friction can naturally be made more sophisticated to accommodate the complexities of real-world dialogue scenarios.
TRACE: Real-Time Multimodal Common Ground Tracking in Situated Collaborative Dialogues
Mar 12, 2025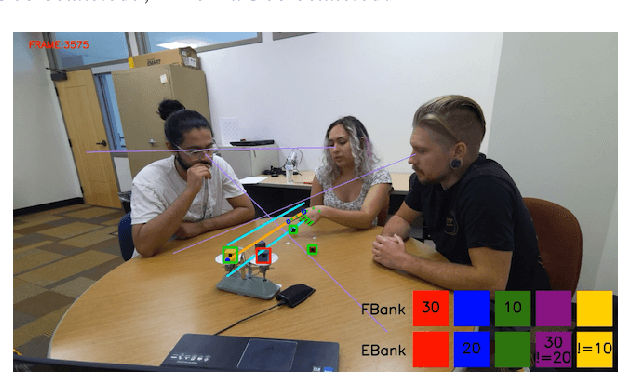

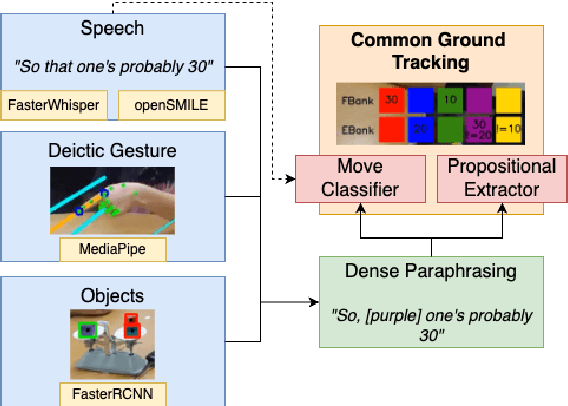
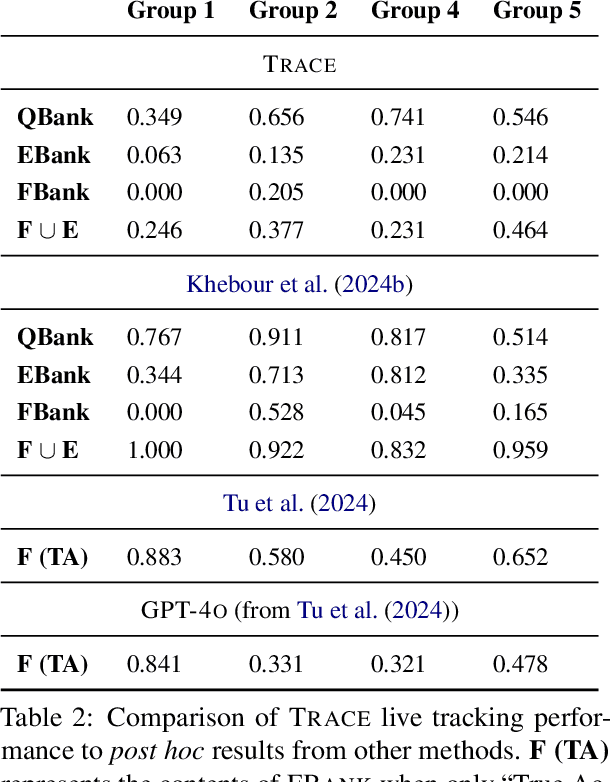
We present TRACE, a novel system for live *common ground* tracking in situated collaborative tasks. With a focus on fast, real-time performance, TRACE tracks the speech, actions, gestures, and visual attention of participants, uses these multimodal inputs to determine the set of task-relevant propositions that have been raised as the dialogue progresses, and tracks the group's epistemic position and beliefs toward them as the task unfolds. Amid increased interest in AI systems that can mediate collaborations, TRACE represents an important step forward for agents that can engage with multiparty, multimodal discourse.
Speech Is Not Enough: Interpreting Nonverbal Indicators of Common Knowledge and Engagement
Dec 08, 2024

Our goal is to develop an AI Partner that can provide support for group problem solving and social dynamics. In multi-party working group environments, multimodal analytics is crucial for identifying non-verbal interactions of group members. In conjunction with their verbal participation, this creates an holistic understanding of collaboration and engagement that provides necessary context for the AI Partner. In this demo, we illustrate our present capabilities at detecting and tracking nonverbal behavior in student task-oriented interactions in the classroom, and the implications for tracking common ground and engagement.
Linguistically Conditioned Semantic Textual Similarity
Jun 06, 2024
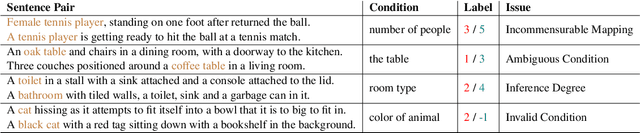
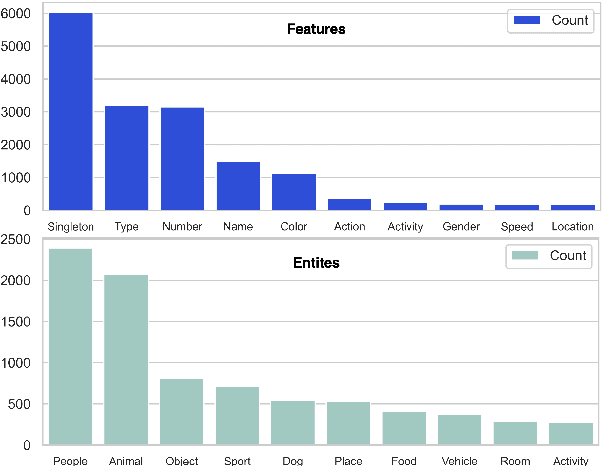

Semantic textual similarity (STS) is a fundamental NLP task that measures the semantic similarity between a pair of sentences. In order to reduce the inherent ambiguity posed from the sentences, a recent work called Conditional STS (C-STS) has been proposed to measure the sentences' similarity conditioned on a certain aspect. Despite the popularity of C-STS, we find that the current C-STS dataset suffers from various issues that could impede proper evaluation on this task. In this paper, we reannotate the C-STS validation set and observe an annotator discrepancy on 55% of the instances resulting from the annotation errors in the original label, ill-defined conditions, and the lack of clarity in the task definition. After a thorough dataset analysis, we improve the C-STS task by leveraging the models' capability to understand the conditions under a QA task setting. With the generated answers, we present an automatic error identification pipeline that is able to identify annotation errors from the C-STS data with over 80% F1 score. We also propose a new method that largely improves the performance over baselines on the C-STS data by training the models with the answers. Finally we discuss the conditionality annotation based on the typed-feature structure (TFS) of entity types. We show in examples that the TFS is able to provide a linguistic foundation for constructing C-STS data with new conditions.
Computational Thought Experiments for a More Rigorous Philosophy and Science of the Mind
May 15, 2024We offer philosophical motivations for a method we call Virtual World Cognitive Science (VW CogSci), in which researchers use virtual embodied agents that are embedded in virtual worlds to explore questions in the field of Cognitive Science. We focus on questions about mental and linguistic representation and the ways that such computational modeling can add rigor to philosophical thought experiments, as well as the terminology used in the scientific study of such representations. We find that this method forces researchers to take a god's-eye view when describing dynamical relationships between entities in minds and entities in an environment in a way that eliminates the need for problematic talk of belief and concept types, such as the belief that cats are silly, and the concept CAT, while preserving belief and concept tokens in individual cognizers' minds. We conclude with some further key advantages of VW CogSci for the scientific study of mental and linguistic representation and for Cognitive Science more broadly.
ChainNet: Structured Metaphor and Metonymy in WordNet
Mar 29, 2024



The senses of a word exhibit rich internal structure. In a typical lexicon, this structure is overlooked: a word's senses are encoded as a list without inter-sense relations. We present ChainNet, a lexical resource which for the first time explicitly identifies these structures. ChainNet expresses how senses in the Open English Wordnet are derived from one another: every nominal sense of a word is either connected to another sense by metaphor or metonymy, or is disconnected in the case of homonymy. Because WordNet senses are linked to resources which capture information about their meaning, ChainNet represents the first dataset of grounded metaphor and metonymy.
Common Ground Tracking in Multimodal Dialogue
Mar 26, 2024



Within Dialogue Modeling research in AI and NLP, considerable attention has been spent on ``dialogue state tracking'' (DST), which is the ability to update the representations of the speaker's needs at each turn in the dialogue by taking into account the past dialogue moves and history. Less studied but just as important to dialogue modeling, however, is ``common ground tracking'' (CGT), which identifies the shared belief space held by all of the participants in a task-oriented dialogue: the task-relevant propositions all participants accept as true. In this paper we present a method for automatically identifying the current set of shared beliefs and ``questions under discussion'' (QUDs) of a group with a shared goal. We annotate a dataset of multimodal interactions in a shared physical space with speech transcriptions, prosodic features, gestures, actions, and facets of collaboration, and operationalize these features for use in a deep neural model to predict moves toward construction of common ground. Model outputs cascade into a set of formal closure rules derived from situated evidence and belief axioms and update operations. We empirically assess the contribution of each feature type toward successful construction of common ground relative to ground truth, establishing a benchmark in this novel, challenging task.
An Abstract Specification of VoxML as an Annotation Language
May 22, 2023



VoxML is a modeling language used to map natural language expressions into real-time visualizations using commonsense semantic knowledge of objects and events. Its utility has been demonstrated in embodied simulation environments and in agent-object interactions in situated multimodal human-agent collaboration and communication. It introduces the notion of object affordance (both Gibsonian and Telic) from HRI and robotics, as well as the concept of habitat (an object's context of use) for interactions between a rational agent and an object. This paper aims to specify VoxML as an annotation language in general abstract terms. It then shows how it works on annotating linguistic data that express visually perceptible human-object interactions. The annotation structures thus generated will be interpreted against the enriched minimal model created by VoxML as a modeling language while supporting the modeling purposes of VoxML linguistically.
Causal schema induction for knowledge discovery
Mar 27, 2023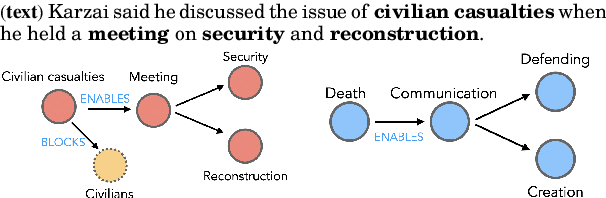


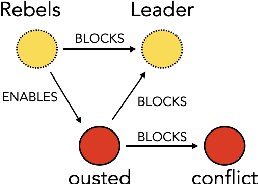
Making sense of familiar yet new situations typically involves making generalizations about causal schemas, stories that help humans reason about event sequences. Reasoning about events includes identifying cause and effect relations shared across event instances, a process we refer to as causal schema induction. Statistical schema induction systems may leverage structural knowledge encoded in discourse or the causal graphs associated with event meaning, however resources to study such causal structure are few in number and limited in size. In this work, we investigate how to apply schema induction models to the task of knowledge discovery for enhanced search of English-language news texts. To tackle the problem of data scarcity, we present Torquestra, a manually curated dataset of text-graph-schema units integrating temporal, event, and causal structures. We benchmark our dataset on three knowledge discovery tasks, building and evaluating models for each. Results show that systems that harness causal structure are effective at identifying texts sharing similar causal meaning components rather than relying on lexical cues alone. We make our dataset and models available for research purposes.
Representing Inferences and their Lexicalization
Dec 14, 2021

We have recently begun a project to develop a more effective and efficient way to marshal inferences from background knowledge to facilitate deep natural language understanding. The meaning of a word is taken to be the entities, predications, presuppositions, and potential inferences that it adds to an ongoing situation. As words compose, the minimal model in the situation evolves to limit and direct inference. At this point we have developed our computational architecture and implemented it on real text. Our focus has been on proving the feasibility of our design.
* 20 pages, 1 figure