 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Partial Information Puzzles: Examining Common Ground Construction Under Epistemic Asymmetry
Mar 05, 2026Establishing common ground, a shared set of beliefs and mutually recognized facts, is fundamental to collaboration, yet remains a challenge for current AI systems, especially in multimodal, multiparty settings, where the collaborators bring different information to the table. We introduce the Distributed Partial Information Puzzle (DPIP), a collaborative construction task that elicits rich multimodal communication under epistemic asymmetry. We present a multimodal dataset of these interactions, annotated and temporally aligned across speech, gesture, and action modalities to support reasoning over propositional content and belief dynamics. We then evaluate two paradigms for modeling common ground (CG): (1) state-of-the-art large language models (LLMs), prompted to infer shared beliefs from multimodal updates, and (2) an axiomatic pipeline grounded in Dynamic Epistemic Logic (DEL) that incrementally performs the same task. Results on the annotated DPIP data indicate that it poses a challenge to modern LLMs' abilities to track both task progression and belief state.
The Impact of Background Speech on Interruption Detection in Collaborative Groups
Jul 09, 2025Interruption plays a crucial role in collaborative learning, shaping group interactions and influencing knowledge construction. AI-driven support can assist teachers in monitoring these interactions. However, most previous work on interruption detection and interpretation has been conducted in single-conversation environments with relatively clean audio. AI agents deployed in classrooms for collaborative learning within small groups will need to contend with multiple concurrent conversations -- in this context, overlapping speech will be ubiquitous, and interruptions will need to be identified in other ways. In this work, we analyze interruption detection in single-conversation and multi-group dialogue settings. We then create a state-of-the-art method for interruption identification that is robust to overlapping speech, and thus could be deployed in classrooms. Further, our work highlights meaningful linguistic and prosodic information about how interruptions manifest in collaborative group interactions. Our investigation also paves the way for future works to account for the influence of overlapping speech from multiple groups when tracking group dialog.
TRACE: Real-Time Multimodal Common Ground Tracking in Situated Collaborative Dialogues
Mar 12, 2025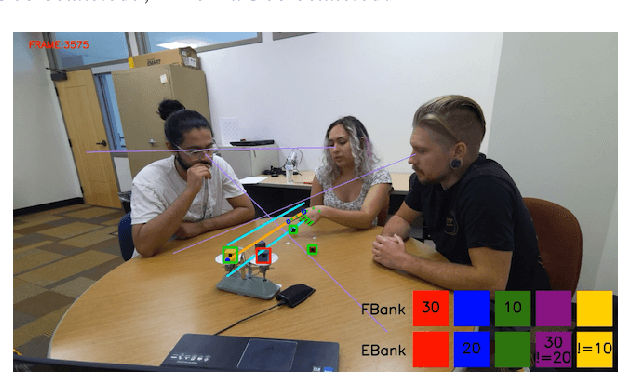

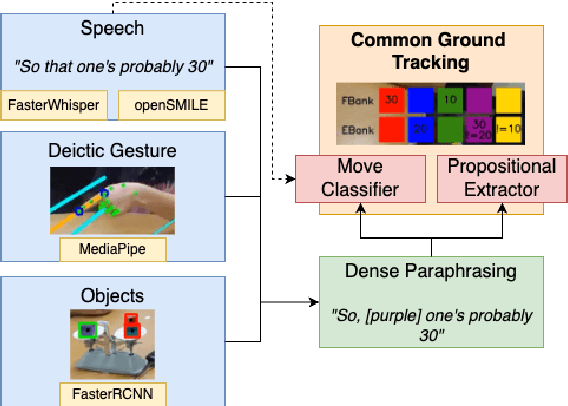
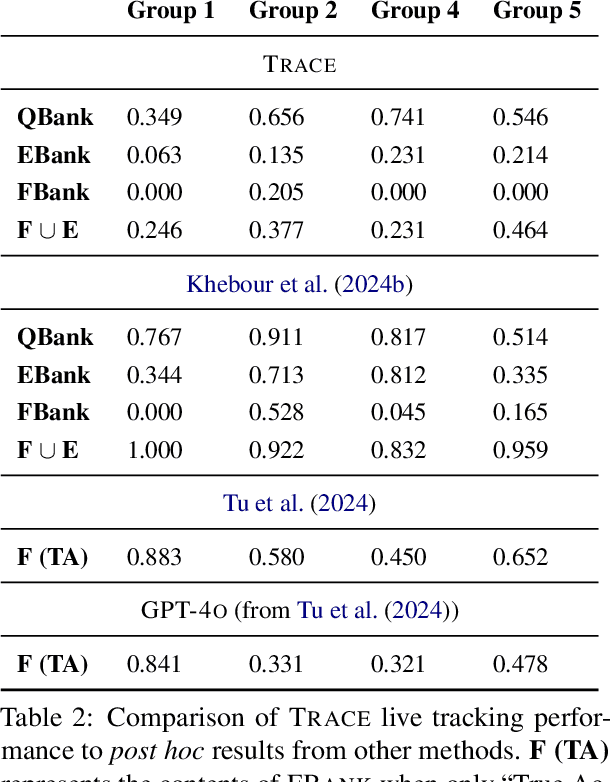
We present TRACE, a novel system for live *common ground* tracking in situated collaborative tasks. With a focus on fast, real-time performance, TRACE tracks the speech, actions, gestures, and visual attention of participants, uses these multimodal inputs to determine the set of task-relevant propositions that have been raised as the dialogue progresses, and tracks the group's epistemic position and beliefs toward them as the task unfolds. Amid increased interest in AI systems that can mediate collaborations, TRACE represents an important step forward for agents that can engage with multiparty, multimodal discourse.
Speech Is Not Enough: Interpreting Nonverbal Indicators of Common Knowledge and Engagement
Dec 08, 2024

Our goal is to develop an AI Partner that can provide support for group problem solving and social dynamics. In multi-party working group environments, multimodal analytics is crucial for identifying non-verbal interactions of group members. In conjunction with their verbal participation, this creates an holistic understanding of collaboration and engagement that provides necessary context for the AI Partner. In this demo, we illustrate our present capabilities at detecting and tracking nonverbal behavior in student task-oriented interactions in the classroom, and the implications for tracking common ground and engagement.
Any Other Thoughts, Hedgehog? Linking Deliberation Chains in Collaborative Dialogues
Oct 25, 2024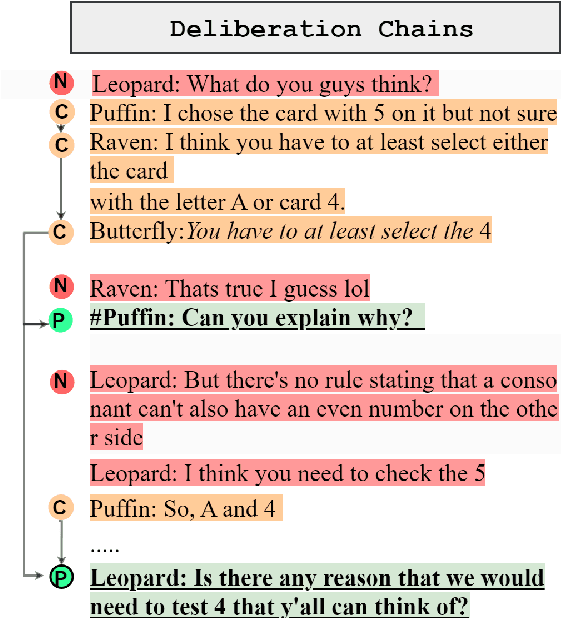
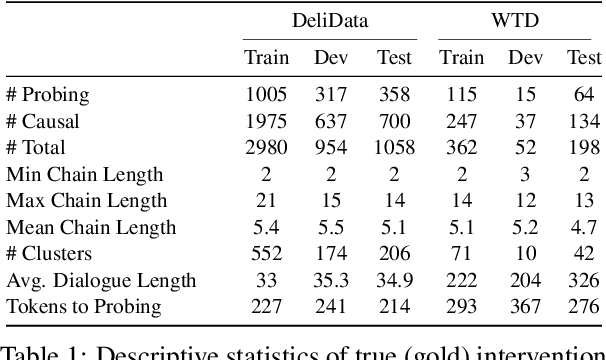

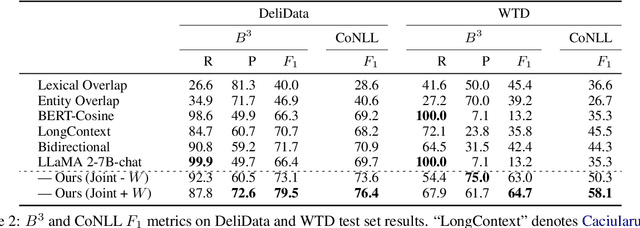
Question-asking in collaborative dialogue has long been established as key to knowledge construction, both in internal and collaborative problem solving. In this work, we examine probing questions in collaborative dialogues: questions that explicitly elicit responses from the speaker's interlocutors. Specifically, we focus on modeling the causal relations that lead directly from utterances earlier in the dialogue to the emergence of the probing question. We model these relations using a novel graph-based framework of deliberation chains, and reframe the problem of constructing such chains as a coreference-style clustering problem. Our framework jointly models probing and causal utterances and the links between them, and we evaluate on two challenging collaborative task datasets: the Weights Task and DeliData. Our results demonstrate the effectiveness of our theoretically-grounded approach compared to both baselines and stronger coreference approaches, and establish a standard of performance in this novel task.
Common Ground Tracking in Multimodal Dialogue
Mar 26, 2024



Within Dialogue Modeling research in AI and NLP, considerable attention has been spent on ``dialogue state tracking'' (DST), which is the ability to update the representations of the speaker's needs at each turn in the dialogue by taking into account the past dialogue moves and history. Less studied but just as important to dialogue modeling, however, is ``common ground tracking'' (CGT), which identifies the shared belief space held by all of the participants in a task-oriented dialogue: the task-relevant propositions all participants accept as true. In this paper we present a method for automatically identifying the current set of shared beliefs and ``questions under discussion'' (QUDs) of a group with a shared goal. We annotate a dataset of multimodal interactions in a shared physical space with speech transcriptions, prosodic features, gestures, actions, and facets of collaboration, and operationalize these features for use in a deep neural model to predict moves toward construction of common ground. Model outputs cascade into a set of formal closure rules derived from situated evidence and belief axioms and update operations. We empirically assess the contribution of each feature type toward successful construction of common ground relative to ground truth, establishing a benchmark in this novel, challenging task.
How Good is Automatic Segmentation as a Multimodal Discourse Annotation Aid?
May 27, 2023


Collaborative problem solving (CPS) in teams is tightly coupled with the creation of shared meaning between participants in a situated, collaborative task. In this work, we assess the quality of different utterance segmentation techniques as an aid in annotating CPS. We (1) manually transcribe utterances in a dataset of triads collaboratively solving a problem involving dialogue and physical object manipulation, (2) annotate collaborative moves according to these gold-standard transcripts, and then (3) apply these annotations to utterances that have been automatically segmented using toolkits from Google and OpenAI's Whisper. We show that the oracle utterances have minimal correspondence to automatically segmented speech, and that automatically segmented speech using different segmentation methods is also inconsistent. We also show that annotating automatically segmented speech has distinct implications compared with annotating oracle utterances--since most annotation schemes are designed for oracle cases, when annotating automatically-segmented utterances, annotators must invoke other information to make arbitrary judgments which other annotators may not replicate. We conclude with a discussion of how future annotation specs can account for these needs.