 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBLUEPRINT Rebuilding a Legacy: Multimodal Retrieval for Complex Engineering Drawings and Documents
Feb 12, 2026Decades of engineering drawings and technical records remain locked in legacy archives with inconsistent or missing metadata, making retrieval difficult and often manual. We present Blueprint, a layout-aware multimodal retrieval system designed for large-scale engineering repositories. Blueprint detects canonical drawing regions, applies region-restricted VLM-based OCR, normalizes identifiers (e.g., DWG, part, facility), and fuses lexical and dense retrieval with a lightweight region-level reranker. Deployed on ~770k unlabeled files, it automatically produces structured metadata suitable for cross-facility search. We evaluate Blueprint on a 5k-file benchmark with 350 expert-curated queries using pooled, graded (0/1/2) relevance judgments. Blueprint delivers a 10.1% absolute gain in Success@3 and an 18.9% relative improvement in nDCG@3 over the strongest vision-language baseline}, consistently outperforming across vision, text, and multimodal intents. Oracle ablations reveal substantial headroom under perfect region detection and OCR. We release all queries, runs, annotations, and code to facilitate reproducible evaluation on legacy engineering archives.
On the Role of Domain Experts in Creating Effective Tutoring Systems
Oct 01, 2025The role that highly curated knowledge, provided by domain experts, could play in creating effective tutoring systems is often overlooked within the AI for education community. In this paper, we highlight this topic by discussing two ways such highly curated expert knowledge could help in creating novel educational systems. First, we will look at how one could use explainable AI (XAI) techniques to automatically create lessons. Most existing XAI methods are primarily aimed at debugging AI systems. However, we will discuss how one could use expert specified rules about solving specific problems along with novel XAI techniques to automatically generate lessons that could be provided to learners. Secondly, we will see how an expert specified curriculum for learning a target concept can help develop adaptive tutoring systems, that can not only provide a better learning experience, but could also allow us to use more efficient algorithms to create these systems. Finally, we will highlight the importance of such methods using a case study of creating a tutoring system for pollinator identification, where such knowledge could easily be elicited from experts.
The Impact of Background Speech on Interruption Detection in Collaborative Groups
Jul 09, 2025Interruption plays a crucial role in collaborative learning, shaping group interactions and influencing knowledge construction. AI-driven support can assist teachers in monitoring these interactions. However, most previous work on interruption detection and interpretation has been conducted in single-conversation environments with relatively clean audio. AI agents deployed in classrooms for collaborative learning within small groups will need to contend with multiple concurrent conversations -- in this context, overlapping speech will be ubiquitous, and interruptions will need to be identified in other ways. In this work, we analyze interruption detection in single-conversation and multi-group dialogue settings. We then create a state-of-the-art method for interruption identification that is robust to overlapping speech, and thus could be deployed in classrooms. Further, our work highlights meaningful linguistic and prosodic information about how interruptions manifest in collaborative group interactions. Our investigation also paves the way for future works to account for the influence of overlapping speech from multiple groups when tracking group dialog.
Any Other Thoughts, Hedgehog? Linking Deliberation Chains in Collaborative Dialogues
Oct 25, 2024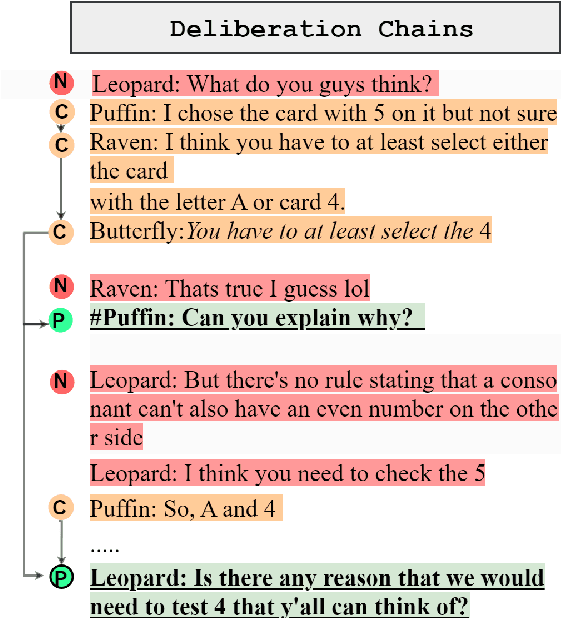

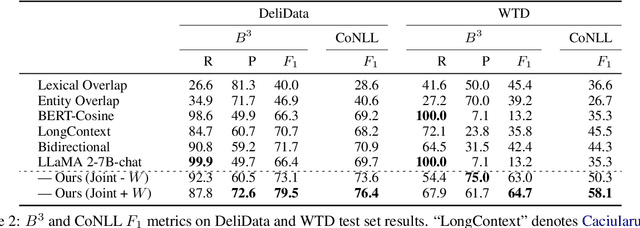
Question-asking in collaborative dialogue has long been established as key to knowledge construction, both in internal and collaborative problem solving. In this work, we examine probing questions in collaborative dialogues: questions that explicitly elicit responses from the speaker's interlocutors. Specifically, we focus on modeling the causal relations that lead directly from utterances earlier in the dialogue to the emergence of the probing question. We model these relations using a novel graph-based framework of deliberation chains, and reframe the problem of constructing such chains as a coreference-style clustering problem. Our framework jointly models probing and causal utterances and the links between them, and we evaluate on two challenging collaborative task datasets: the Weights Task and DeliData. Our results demonstrate the effectiveness of our theoretically-grounded approach compared to both baselines and stronger coreference approaches, and establish a standard of performance in this novel task.
Multimodal Cross-Document Event Coreference Resolution Using Linear Semantic Transfer and Mixed-Modality Ensembles
Apr 13, 2024



Event coreference resolution (ECR) is the task of determining whether distinct mentions of events within a multi-document corpus are actually linked to the same underlying occurrence. Images of the events can help facilitate resolution when language is ambiguous. Here, we propose a multimodal cross-document event coreference resolution method that integrates visual and textual cues with a simple linear map between vision and language models. As existing ECR benchmark datasets rarely provide images for all event mentions, we augment the popular ECB+ dataset with event-centric images scraped from the internet and generated using image diffusion models. We establish three methods that incorporate images and text for coreference: 1) a standard fused model with finetuning, 2) a novel linear mapping method without finetuning and 3) an ensembling approach based on splitting mention pairs by semantic and discourse-level difficulty. We evaluate on 2 datasets: the augmented ECB+, and AIDA Phase 1. Our ensemble systems using cross-modal linear mapping establish an upper limit (91.9 CoNLL F1) on ECB+ ECR performance given the preprocessing assumptions used, and establish a novel baseline on AIDA Phase 1. Our results demonstrate the utility of multimodal information in ECR for certain challenging coreference problems, and highlight a need for more multimodal resources in the coreference resolution space.
Common Ground Tracking in Multimodal Dialogue
Mar 26, 2024



Within Dialogue Modeling research in AI and NLP, considerable attention has been spent on ``dialogue state tracking'' (DST), which is the ability to update the representations of the speaker's needs at each turn in the dialogue by taking into account the past dialogue moves and history. Less studied but just as important to dialogue modeling, however, is ``common ground tracking'' (CGT), which identifies the shared belief space held by all of the participants in a task-oriented dialogue: the task-relevant propositions all participants accept as true. In this paper we present a method for automatically identifying the current set of shared beliefs and ``questions under discussion'' (QUDs) of a group with a shared goal. We annotate a dataset of multimodal interactions in a shared physical space with speech transcriptions, prosodic features, gestures, actions, and facets of collaboration, and operationalize these features for use in a deep neural model to predict moves toward construction of common ground. Model outputs cascade into a set of formal closure rules derived from situated evidence and belief axioms and update operations. We empirically assess the contribution of each feature type toward successful construction of common ground relative to ground truth, establishing a benchmark in this novel, challenging task.
How Good is Automatic Segmentation as a Multimodal Discourse Annotation Aid?
May 27, 2023


Collaborative problem solving (CPS) in teams is tightly coupled with the creation of shared meaning between participants in a situated, collaborative task. In this work, we assess the quality of different utterance segmentation techniques as an aid in annotating CPS. We (1) manually transcribe utterances in a dataset of triads collaboratively solving a problem involving dialogue and physical object manipulation, (2) annotate collaborative moves according to these gold-standard transcripts, and then (3) apply these annotations to utterances that have been automatically segmented using toolkits from Google and OpenAI's Whisper. We show that the oracle utterances have minimal correspondence to automatically segmented speech, and that automatically segmented speech using different segmentation methods is also inconsistent. We also show that annotating automatically segmented speech has distinct implications compared with annotating oracle utterances--since most annotation schemes are designed for oracle cases, when annotating automatically-segmented utterances, annotators must invoke other information to make arbitrary judgments which other annotators may not replicate. We conclude with a discussion of how future annotation specs can account for these needs.
Hamming Similarity and Graph Laplacians for Class Partitioning and Adversarial Image Detection
May 06, 2023



Researchers typically investigate neural network representations by examining activation outputs for one or more layers of a network. Here, we investigate the potential for ReLU activation patterns (encoded as bit vectors) to aid in understanding and interpreting the behavior of neural networks. We utilize Representational Dissimilarity Matrices (RDMs) to investigate the coherence of data within the embedding spaces of a deep neural network. From each layer of a network, we extract and utilize bit vectors to construct similarity scores between images. From these similarity scores, we build a similarity matrix for a collection of images drawn from 2 classes. We then apply Fiedler partitioning to the associated Laplacian matrix to separate the classes. Our results indicate, through bit vector representations, that the network continues to refine class detectability with the last ReLU layer achieving better than 95\% separation accuracy. Additionally, we demonstrate that bit vectors aid in adversarial image detection, again achieving over 95\% accuracy in separating adversarial and non-adversarial images using a simple classifier.
A Computer Vision Method for Estimating Velocity from Jumps
Dec 09, 2022
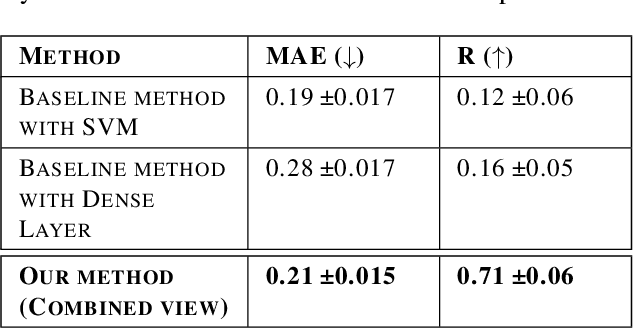
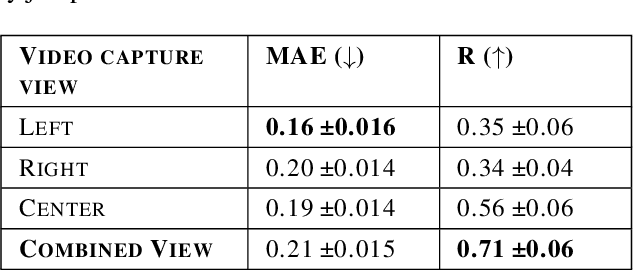
Athletes routinely undergo fitness evaluations to evaluate their training progress. Typically, these evaluations require a trained professional who utilizes specialized equipment like force plates. For the assessment, athletes perform drop and squat jumps, and key variables are measured, e.g. velocity, flight time, and time to stabilization, to name a few. However, amateur athletes may not have access to professionals or equipment that can provide these assessments. Here, we investigate the feasibility of estimating key variables using video recordings. We focus on jump velocity as a starting point because it is highly correlated with other key variables and is important for determining posture and lower-limb capacity. We find that velocity can be estimated with a high degree of precision across a range of athletes, with an average R-value of 0.71 (SD = 0.06).
Dual Graphs of Polyhedral Decompositions for the Detection of Adversarial Attacks
Dec 02, 2022


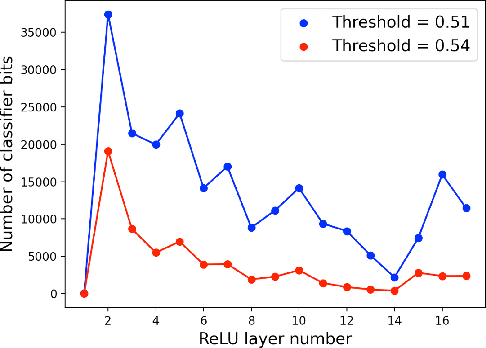
Previous work has shown that a neural network with the rectified linear unit (ReLU) activation function leads to a convex polyhedral decomposition of the input space. These decompositions can be represented by a dual graph with vertices corresponding to polyhedra and edges corresponding to polyhedra sharing a facet, which is a subgraph of a Hamming graph. This paper illustrates how one can utilize the dual graph to detect and analyze adversarial attacks in the context of digital images. When an image passes through a network containing ReLU nodes, the firing or non-firing at a node can be encoded as a bit ($1$ for ReLU activation, $0$ for ReLU non-activation). The sequence of all bit activations identifies the image with a bit vector, which identifies it with a polyhedron in the decomposition and, in turn, identifies it with a vertex in the dual graph. We identify ReLU bits that are discriminators between non-adversarial and adversarial images and examine how well collections of these discriminators can ensemble vote to build an adversarial image detector. Specifically, we examine the similarities and differences of ReLU bit vectors for adversarial images, and their non-adversarial counterparts, using a pre-trained ResNet-50 architecture. While this paper focuses on adversarial digital images, ResNet-50 architecture, and the ReLU activation function, our methods extend to other network architectures, activation functions, and types of datasets.