 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA UCB Bandit Algorithm for General ML-Based Estimators
Jan 06, 2026We present ML-UCB, a generalized upper confidence bound algorithm that integrates arbitrary machine learning models into multi-armed bandit frameworks. A fundamental challenge in deploying sophisticated ML models for sequential decision-making is the lack of tractable concentration inequalities required for principled exploration. We overcome this limitation by directly modeling the learning curve behavior of the underlying estimator. Specifically, assuming the Mean Squared Error decreases as a power law in the number of training samples, we derive a generalized concentration inequality and prove that ML-UCB achieves sublinear regret. This framework enables the principled integration of any ML model whose learning curve can be empirically characterized, eliminating the need for model-specific theoretical analysis. We validate our approach through experiments on a collaborative filtering recommendation system using online matrix factorization with synthetic data designed to simulate a simplified two-tower model, demonstrating substantial improvements over LinUCB
IDDM: Bridging Synthetic-to-Real Domain Gap from Physics-Guided Diffusion for Real-world Image Dehazing
Apr 30, 2025Due to the domain gap between real-world and synthetic hazy images, current data-driven dehazing algorithms trained on synthetic datasets perform well on synthetic data but struggle to generalize to real-world scenarios. To address this challenge, we propose \textbf{I}mage \textbf{D}ehazing \textbf{D}iffusion \textbf{M}odels (IDDM), a novel diffusion process that incorporates the atmospheric scattering model into noise diffusion. IDDM aims to use the gradual haze formation process to help the denoising Unet robustly learn the distribution of clear images from the conditional input hazy images. We design a specialized training strategy centered around IDDM. Diffusion models are leveraged to bridge the domain gap from synthetic to real-world, while the atmospheric scattering model provides physical guidance for haze formation. During the forward process, IDDM simultaneously introduces haze and noise into clear images, and then robustly separates them during the sampling process. By training with physics-guided information, IDDM shows the ability of domain generalization, and effectively restores the real-world hazy images despite being trained on synthetic datasets. Extensive experiments demonstrate the effectiveness of our method through both quantitative and qualitative comparisons with state-of-the-art approaches.
Unbiased Faster R-CNN for Single-source Domain Generalized Object Detection
May 24, 2024

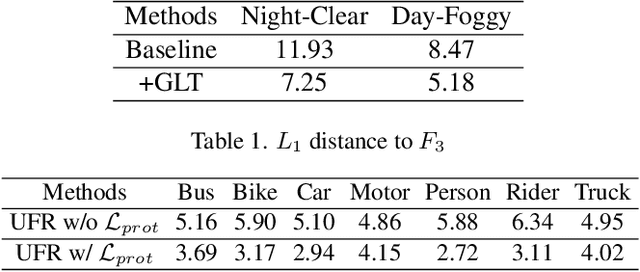

Single-source domain generalization (SDG) for object detection is a challenging yet essential task as the distribution bias of the unseen domain degrades the algorithm performance significantly. However, existing methods attempt to extract domain-invariant features, neglecting that the biased data leads the network to learn biased features that are non-causal and poorly generalizable. To this end, we propose an Unbiased Faster R-CNN (UFR) for generalizable feature learning. Specifically, we formulate SDG in object detection from a causal perspective and construct a Structural Causal Model (SCM) to analyze the data bias and feature bias in the task, which are caused by scene confounders and object attribute confounders. Based on the SCM, we design a Global-Local Transformation module for data augmentation, which effectively simulates domain diversity and mitigates the data bias. Additionally, we introduce a Causal Attention Learning module that incorporates a designed attention invariance loss to learn image-level features that are robust to scene confounders. Moreover, we develop a Causal Prototype Learning module with an explicit instance constraint and an implicit prototype constraint, which further alleviates the negative impact of object attribute confounders. Experimental results on five scenes demonstrate the prominent generalization ability of our method, with an improvement of 3.9% mAP on the Night-Clear scene.
ReLU Neural Networks, Polyhedral Decompositions, and Persistent Homolog
Jun 30, 2023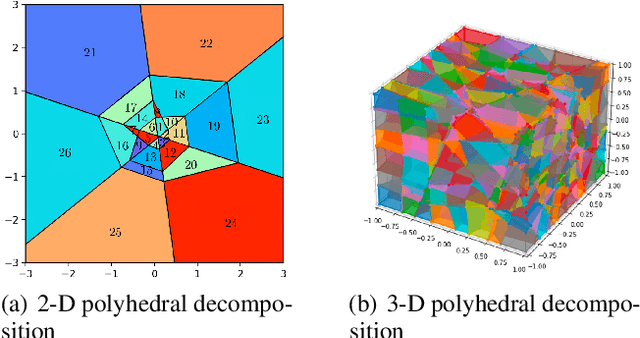
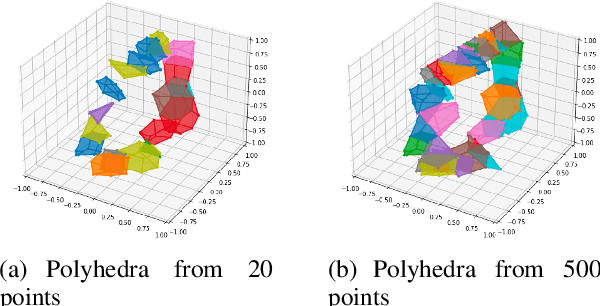
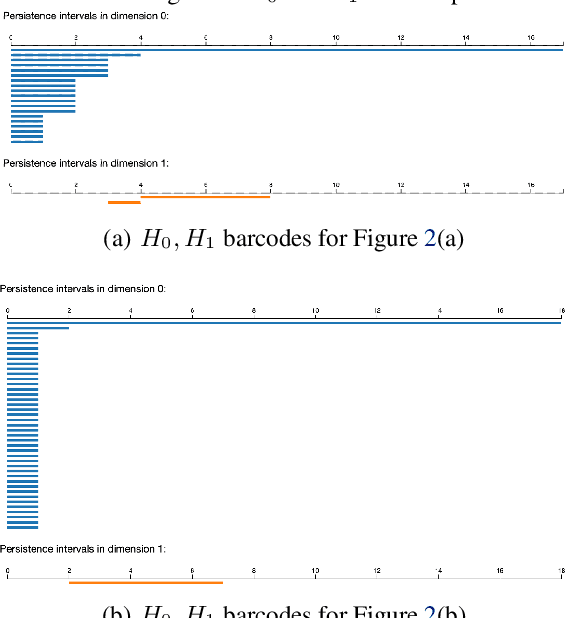

A ReLU neural network leads to a finite polyhedral decomposition of input space and a corresponding finite dual graph. We show that while this dual graph is a coarse quantization of input space, it is sufficiently robust that it can be combined with persistent homology to detect homological signals of manifolds in the input space from samples. This property holds for a variety of networks trained for a wide range of purposes that have nothing to do with this topological application. We found this feature to be surprising and interesting; we hope it will also be useful.
Hamming Similarity and Graph Laplacians for Class Partitioning and Adversarial Image Detection
May 06, 2023



Researchers typically investigate neural network representations by examining activation outputs for one or more layers of a network. Here, we investigate the potential for ReLU activation patterns (encoded as bit vectors) to aid in understanding and interpreting the behavior of neural networks. We utilize Representational Dissimilarity Matrices (RDMs) to investigate the coherence of data within the embedding spaces of a deep neural network. From each layer of a network, we extract and utilize bit vectors to construct similarity scores between images. From these similarity scores, we build a similarity matrix for a collection of images drawn from 2 classes. We then apply Fiedler partitioning to the associated Laplacian matrix to separate the classes. Our results indicate, through bit vector representations, that the network continues to refine class detectability with the last ReLU layer achieving better than 95\% separation accuracy. Additionally, we demonstrate that bit vectors aid in adversarial image detection, again achieving over 95\% accuracy in separating adversarial and non-adversarial images using a simple classifier.
Dual Graphs of Polyhedral Decompositions for the Detection of Adversarial Attacks
Dec 02, 2022


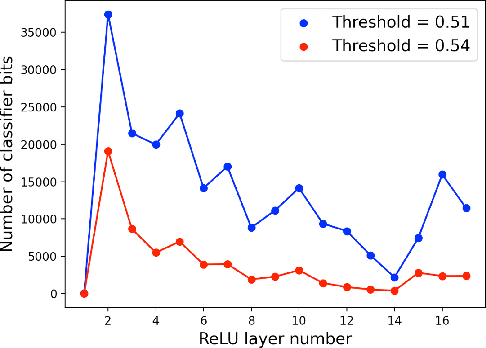
Previous work has shown that a neural network with the rectified linear unit (ReLU) activation function leads to a convex polyhedral decomposition of the input space. These decompositions can be represented by a dual graph with vertices corresponding to polyhedra and edges corresponding to polyhedra sharing a facet, which is a subgraph of a Hamming graph. This paper illustrates how one can utilize the dual graph to detect and analyze adversarial attacks in the context of digital images. When an image passes through a network containing ReLU nodes, the firing or non-firing at a node can be encoded as a bit ($1$ for ReLU activation, $0$ for ReLU non-activation). The sequence of all bit activations identifies the image with a bit vector, which identifies it with a polyhedron in the decomposition and, in turn, identifies it with a vertex in the dual graph. We identify ReLU bits that are discriminators between non-adversarial and adversarial images and examine how well collections of these discriminators can ensemble vote to build an adversarial image detector. Specifically, we examine the similarities and differences of ReLU bit vectors for adversarial images, and their non-adversarial counterparts, using a pre-trained ResNet-50 architecture. While this paper focuses on adversarial digital images, ResNet-50 architecture, and the ReLU activation function, our methods extend to other network architectures, activation functions, and types of datasets.
Self-Supervision Can Be a Good Few-Shot Learner
Jul 19, 2022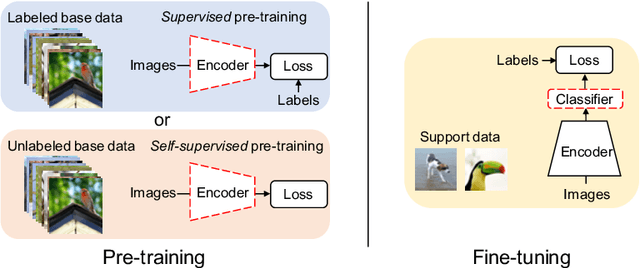
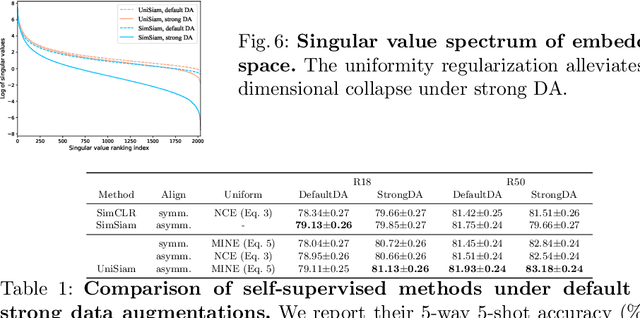
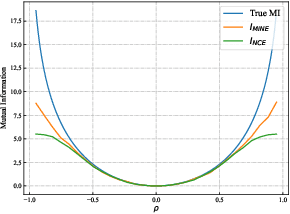
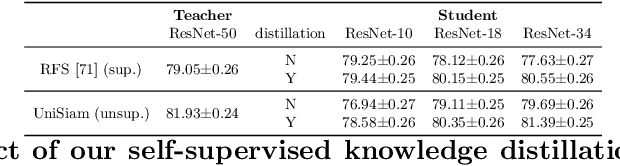
Existing few-shot learning (FSL) methods rely on training with a large labeled dataset, which prevents them from leveraging abundant unlabeled data. From an information-theoretic perspective, we propose an effective unsupervised FSL method, learning representations with self-supervision. Following the InfoMax principle, our method learns comprehensive representations by capturing the intrinsic structure of the data. Specifically, we maximize the mutual information (MI) of instances and their representations with a low-bias MI estimator to perform self-supervised pre-training. Rather than supervised pre-training focusing on the discriminable features of the seen classes, our self-supervised model has less bias toward the seen classes, resulting in better generalization for unseen classes. We explain that supervised pre-training and self-supervised pre-training are actually maximizing different MI objectives. Extensive experiments are further conducted to analyze their FSL performance with various training settings. Surprisingly, the results show that self-supervised pre-training can outperform supervised pre-training under the appropriate conditions. Compared with state-of-the-art FSL methods, our approach achieves comparable performance on widely used FSL benchmarks without any labels of the base classes.
Source-Free Domain Adaptation for Real-world Image Dehazing
Jul 14, 2022
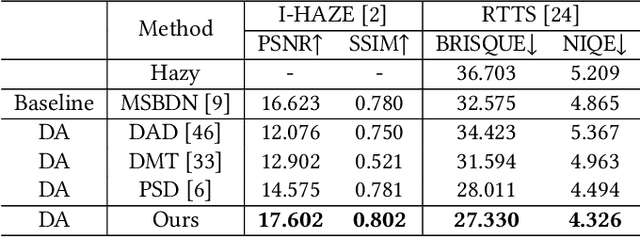
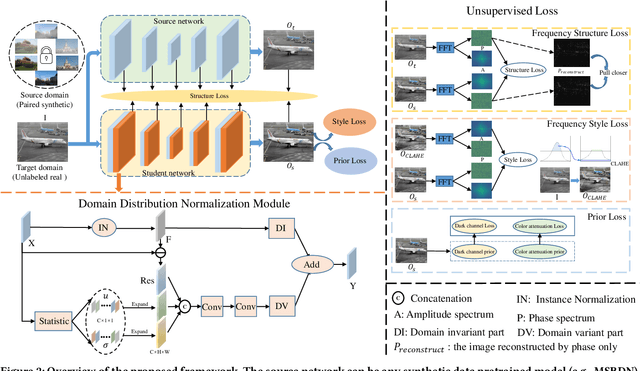
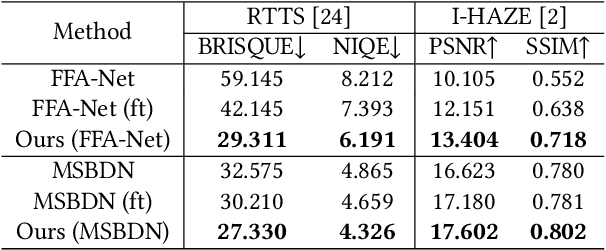
Deep learning-based source dehazing methods trained on synthetic datasets have achieved remarkable performance but suffer from dramatic performance degradation on real hazy images due to domain shift. Although certain Domain Adaptation (DA) dehazing methods have been presented, they inevitably require access to the source dataset to reduce the gap between the source synthetic and target real domains. To address these issues, we present a novel Source-Free Unsupervised Domain Adaptation (SFUDA) image dehazing paradigm, in which only a well-trained source model and an unlabeled target real hazy dataset are available. Specifically, we devise the Domain Representation Normalization (DRN) module to make the representation of real hazy domain features match that of the synthetic domain to bridge the gaps. With our plug-and-play DRN module, unlabeled real hazy images can adapt existing well-trained source networks. Besides, the unsupervised losses are applied to guide the learning of the DRN module, which consists of frequency losses and physical prior losses. Frequency losses provide structure and style constraints, while the prior loss explores the inherent statistic property of haze-free images. Equipped with our DRN module and unsupervised loss, existing source dehazing models are able to dehaze unlabeled real hazy images. Extensive experiments on multiple baselines demonstrate the validity and superiority of our method visually and quantitatively.
Prompt Distribution Learning
May 06, 2022
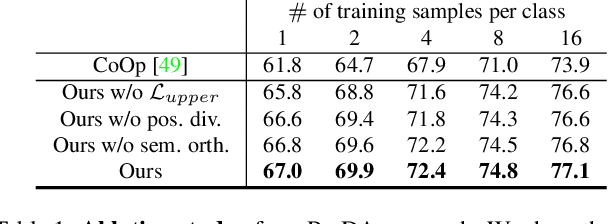
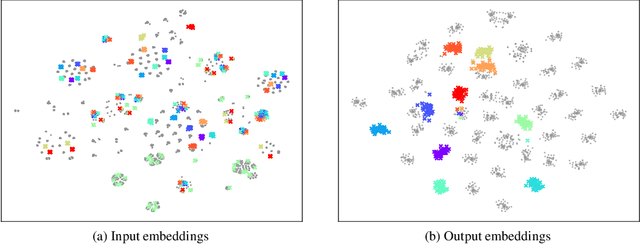

We present prompt distribution learning for effectively adapting a pre-trained vision-language model to address downstream recognition tasks. Our method not only learns low-bias prompts from a few samples but also captures the distribution of diverse prompts to handle the varying visual representations. In this way, we provide high-quality task-related content for facilitating recognition. This prompt distribution learning is realized by an efficient approach that learns the output embeddings of prompts instead of the input embeddings. Thus, we can employ a Gaussian distribution to model them effectively and derive a surrogate loss for efficient training. Extensive experiments on 12 datasets demonstrate that our method consistently and significantly outperforms existing methods. For example, with 1 sample per category, it relatively improves the average result by 9.1% compared to human-crafted prompts.
Improving Fraud Detection via Hierarchical Attention-based Graph Neural Network
Feb 21, 2022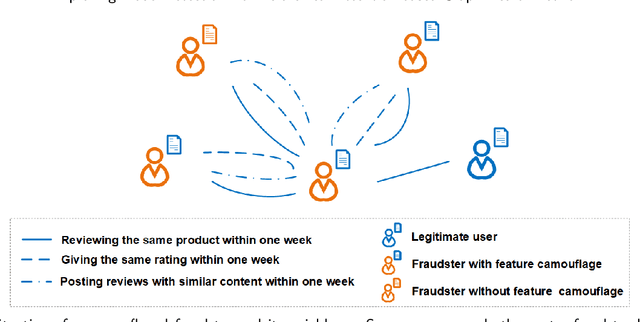
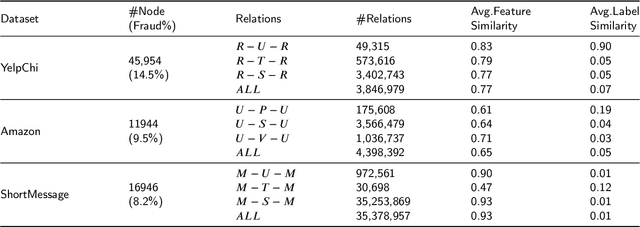
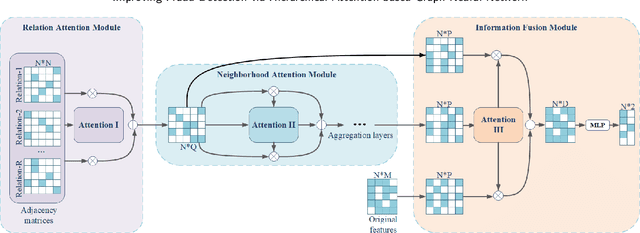

Graph neural networks (GNN) have emerged as a powerful tool for fraud detection tasks, where fraudulent nodes are identified by aggregating neighbor information via different relations. To get around such detection, crafty fraudsters resort to camouflage via connecting to legitimate users (i.e., relation camouflage) or providing seemingly legitimate feedbacks (i.e., feature camouflage). A wide-spread solution reinforces the GNN aggregation process with neighbor selectors according to original node features. This method may carry limitations when identifying fraudsters not only with the relation camouflage, but with the feature camouflage making them hard to distinguish from their legitimate neighbors. In this paper, we propose a Hierarchical Attention-based Graph Neural Network (HA-GNN) for fraud detection, which incorporates weighted adjacency matrices across different relations against camouflage. This is motivated in the Relational Density Theory and is exploited for forming a hierarchical attention-based graph neural network. Specifically, we design a relation attention module to reflect the tie strength between two nodes, while a neighborhood attention module to capture the long-range structural affinity associated with the graph. We generate node embeddings by aggregating information from local/long-range structures and original node features. Experiments on three real-world datasets demonstrate the effectiveness of our model over the state-of-the-arts.