 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Position Embedding as a Context Controller for Multi-Reference and Multi-Shot Video Generation
Apr 04, 2026Recent proprietary models such as Sora2 demonstrate promising progress in generating multi-shot videos conditioned on multiple reference characters. However, academic research on this problem remains limited. We study this task and identify a core challenge: when reference images exhibit highly similar appearances, the model often suffers from reference confusion, where semantically similar tokens degrade the model's ability to retrieve the correct context. To address this, we introduce PoCo (Position Embedding as a Context Controller), which incorporates position encoding as additional context control beyond semantic retrieval. By employing side information of tokens, PoCo enables precise token-level matching while preserving implicit semantic consistency modeling. Building on PoCo, we develop a multi-reference and multi-shot video generation model capable of reliably controlling characters with extremely similar visual traits. Extensive experiments demonstrate that PoCo improves cross-shot consistency and reference fidelity compared with various baselines.
Few-Shot Learning with Visual Distribution Calibration and Cross-Modal Distribution Alignment
May 19, 2023Pre-trained vision-language models have inspired much research on few-shot learning. However, with only a few training images, there exist two crucial problems: (1) the visual feature distributions are easily distracted by class-irrelevant information in images, and (2) the alignment between the visual and language feature distributions is difficult. To deal with the distraction problem, we propose a Selective Attack module, which consists of trainable adapters that generate spatial attention maps of images to guide the attacks on class-irrelevant image areas. By messing up these areas, the critical features are captured and the visual distributions of image features are calibrated. To better align the visual and language feature distributions that describe the same object class, we propose a cross-modal distribution alignment module, in which we introduce a vision-language prototype for each class to align the distributions, and adopt the Earth Mover's Distance (EMD) to optimize the prototypes. For efficient computation, the upper bound of EMD is derived. In addition, we propose an augmentation strategy to increase the diversity of the images and the text prompts, which can reduce overfitting to the few-shot training images. Extensive experiments on 11 datasets demonstrate that our method consistently outperforms prior arts in few-shot learning. The implementation code will be available at https://github.com/bhrqw/SADA.
Self-Supervision Can Be a Good Few-Shot Learner
Jul 19, 2022
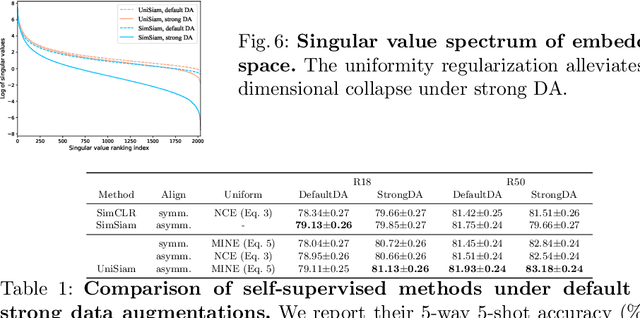
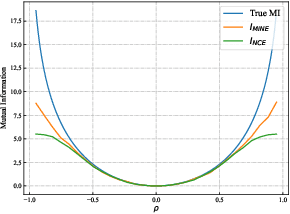
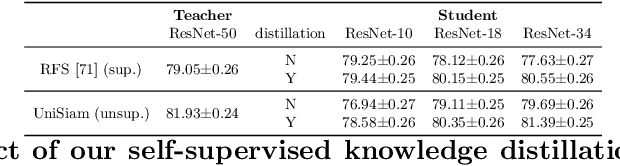
Existing few-shot learning (FSL) methods rely on training with a large labeled dataset, which prevents them from leveraging abundant unlabeled data. From an information-theoretic perspective, we propose an effective unsupervised FSL method, learning representations with self-supervision. Following the InfoMax principle, our method learns comprehensive representations by capturing the intrinsic structure of the data. Specifically, we maximize the mutual information (MI) of instances and their representations with a low-bias MI estimator to perform self-supervised pre-training. Rather than supervised pre-training focusing on the discriminable features of the seen classes, our self-supervised model has less bias toward the seen classes, resulting in better generalization for unseen classes. We explain that supervised pre-training and self-supervised pre-training are actually maximizing different MI objectives. Extensive experiments are further conducted to analyze their FSL performance with various training settings. Surprisingly, the results show that self-supervised pre-training can outperform supervised pre-training under the appropriate conditions. Compared with state-of-the-art FSL methods, our approach achieves comparable performance on widely used FSL benchmarks without any labels of the base classes.
Prompt Distribution Learning
May 06, 2022
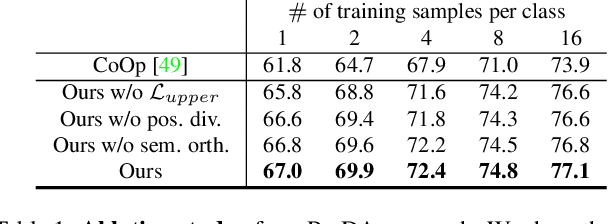
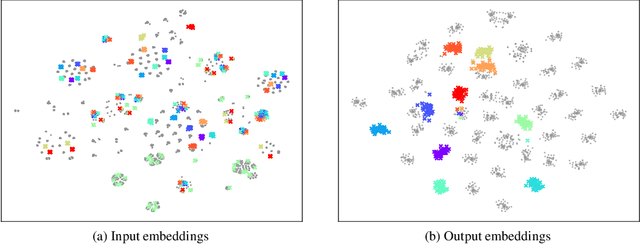

We present prompt distribution learning for effectively adapting a pre-trained vision-language model to address downstream recognition tasks. Our method not only learns low-bias prompts from a few samples but also captures the distribution of diverse prompts to handle the varying visual representations. In this way, we provide high-quality task-related content for facilitating recognition. This prompt distribution learning is realized by an efficient approach that learns the output embeddings of prompts instead of the input embeddings. Thus, we can employ a Gaussian distribution to model them effectively and derive a surrogate loss for efficient training. Extensive experiments on 12 datasets demonstrate that our method consistently and significantly outperforms existing methods. For example, with 1 sample per category, it relatively improves the average result by 9.1% compared to human-crafted prompts.