 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistribution-aware Forgetting Compensation for Exemplar-Free Lifelong Person Re-identification
Apr 22, 2025Lifelong Person Re-identification (LReID) suffers from a key challenge in preserving old knowledge while adapting to new information. The existing solutions include rehearsal-based and rehearsal-free methods to address this challenge. Rehearsal-based approaches rely on knowledge distillation, continuously accumulating forgetting during the distillation process. Rehearsal-free methods insufficiently learn the distribution of each domain, leading to forgetfulness over time. To solve these issues, we propose a novel Distribution-aware Forgetting Compensation (DAFC) model that explores cross-domain shared representation learning and domain-specific distribution integration without using old exemplars or knowledge distillation. We propose a Text-driven Prompt Aggregation (TPA) that utilizes text features to enrich prompt elements and guide the prompt model to learn fine-grained representations for each instance. This can enhance the differentiation of identity information and establish the foundation for domain distribution awareness. Then, Distribution-based Awareness and Integration (DAI) is designed to capture each domain-specific distribution by a dedicated expert network and adaptively consolidate them into a shared region in high-dimensional space. In this manner, DAI can consolidate and enhance cross-domain shared representation learning while alleviating catastrophic forgetting. Furthermore, we develop a Knowledge Consolidation Mechanism (KCM) that comprises instance-level discrimination and cross-domain consistency alignment strategies to facilitate model adaptive learning of new knowledge from the current domain and promote knowledge consolidation learning between acquired domain-specific distributions, respectively. Experimental results show that our DAFC outperforms state-of-the-art methods. Our code is available at https://github.com/LiuShiBen/DAFC.
GAFusion: Adaptive Fusing LiDAR and Camera with Multiple Guidance for 3D Object Detection
Nov 01, 2024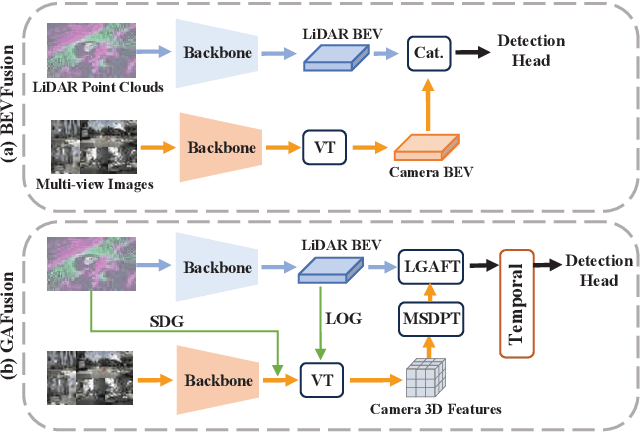
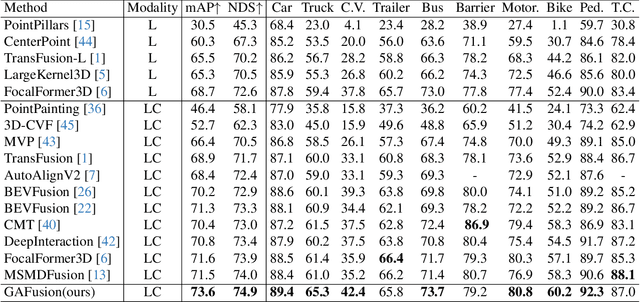
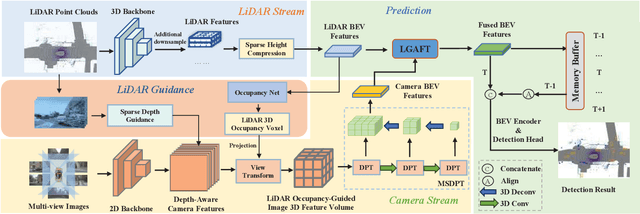
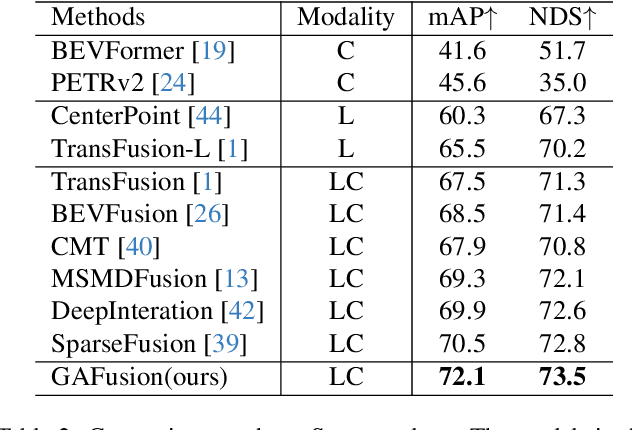
Recent years have witnessed the remarkable progress of 3D multi-modality object detection methods based on the Bird's-Eye-View (BEV) perspective. However, most of them overlook the complementary interaction and guidance between LiDAR and camera. In this work, we propose a novel multi-modality 3D objection detection method, named GAFusion, with LiDAR-guided global interaction and adaptive fusion. Specifically, we introduce sparse depth guidance (SDG) and LiDAR occupancy guidance (LOG) to generate 3D features with sufficient depth information. In the following, LiDAR-guided adaptive fusion transformer (LGAFT) is developed to adaptively enhance the interaction of different modal BEV features from a global perspective. Meanwhile, additional downsampling with sparse height compression and multi-scale dual-path transformer (MSDPT) are designed to enlarge the receptive fields of different modal features. Finally, a temporal fusion module is introduced to aggregate features from previous frames. GAFusion achieves state-of-the-art 3D object detection results with 73.6$\%$ mAP and 74.9$\%$ NDS on the nuScenes test set.
GMT: A Robust Global Association Model for Multi-Target Multi-Camera Tracking
Jul 01, 2024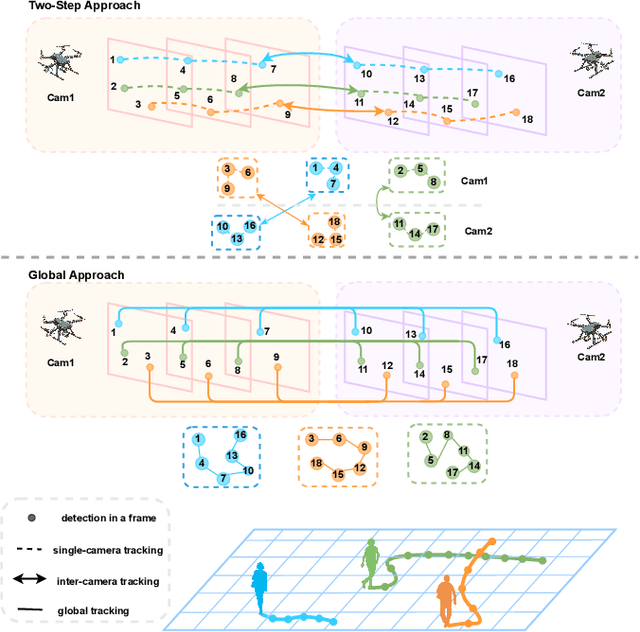
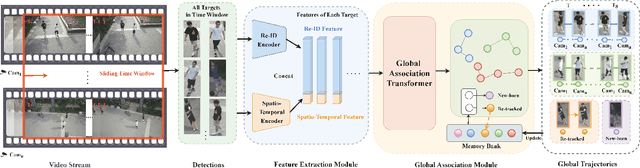

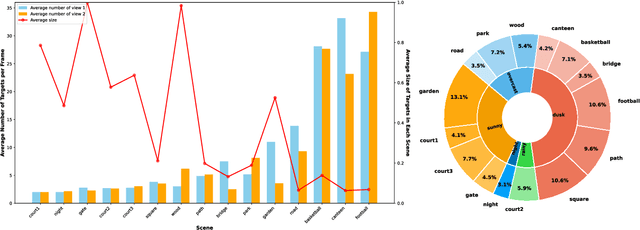
In the task of multi-target multi-camera (MTMC) tracking of pedestrians, the data association problem is a key issue and main challenge, especially with complications arising from camera movements, lighting variations, and obstructions. However, most MTMC models adopt two-step approaches, thus heavily depending on the results of the first-step tracking in practical applications. Moreover, the same targets crossing different cameras may exhibit significant appearance variations, which further increases the difficulty of cross-camera matching. To address the aforementioned issues, we propose a global online MTMC tracking model that addresses the dependency on the first tracking stage in two-step methods and enhances cross-camera matching. Specifically, we propose a transformer-based global MTMC association module to explore target associations across different cameras and frames, generating global trajectories directly. Additionally, to integrate the appearance and spatio-temporal features of targets, we propose a feature extraction and fusion module for MTMC tracking. This module enhances feature representation and establishes correlations between the features of targets across multiple cameras. To accommodate high scene diversity and complex lighting condition variations, we have established the VisionTrack dataset, which enables the development of models that are more generalized and robust to various environments. Our model demonstrates significant improvements over comparison methods on the VisionTrack dataset and others.
Unbiased Faster R-CNN for Single-source Domain Generalized Object Detection
May 24, 2024

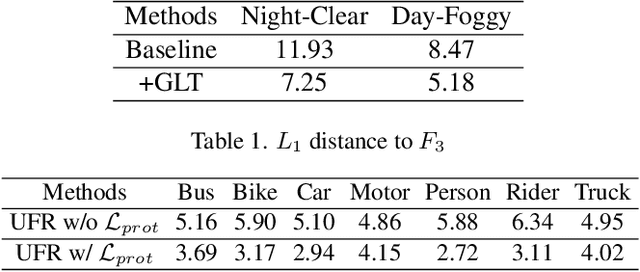

Single-source domain generalization (SDG) for object detection is a challenging yet essential task as the distribution bias of the unseen domain degrades the algorithm performance significantly. However, existing methods attempt to extract domain-invariant features, neglecting that the biased data leads the network to learn biased features that are non-causal and poorly generalizable. To this end, we propose an Unbiased Faster R-CNN (UFR) for generalizable feature learning. Specifically, we formulate SDG in object detection from a causal perspective and construct a Structural Causal Model (SCM) to analyze the data bias and feature bias in the task, which are caused by scene confounders and object attribute confounders. Based on the SCM, we design a Global-Local Transformation module for data augmentation, which effectively simulates domain diversity and mitigates the data bias. Additionally, we introduce a Causal Attention Learning module that incorporates a designed attention invariance loss to learn image-level features that are robust to scene confounders. Moreover, we develop a Causal Prototype Learning module with an explicit instance constraint and an implicit prototype constraint, which further alleviates the negative impact of object attribute confounders. Experimental results on five scenes demonstrate the prominent generalization ability of our method, with an improvement of 3.9% mAP on the Night-Clear scene.
EasyTrack: Efficient and Compact One-stream 3D Point Clouds Tracker
Apr 12, 2024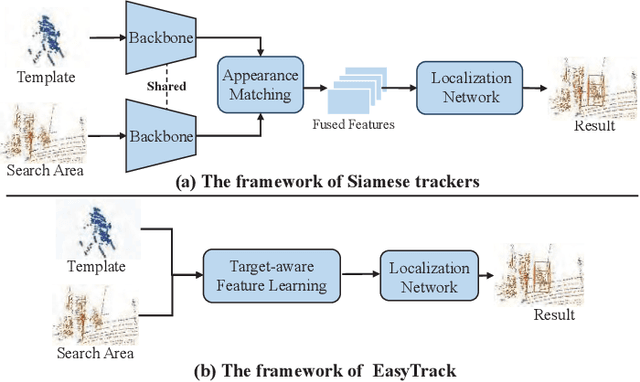
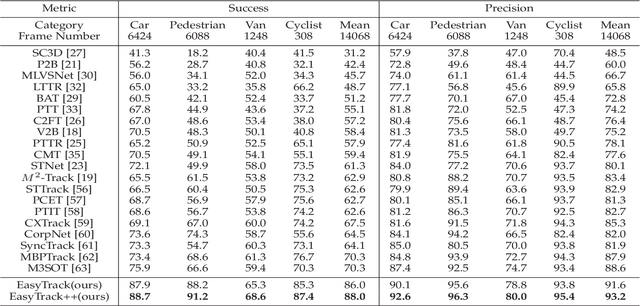
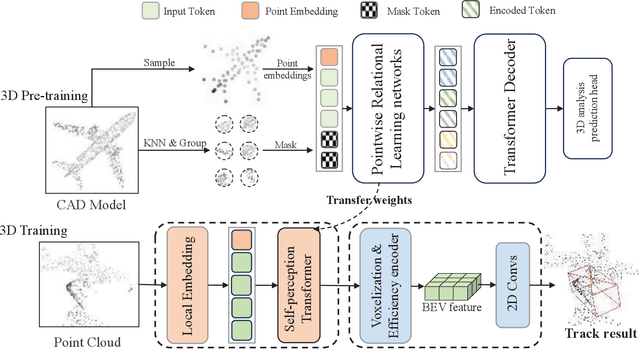
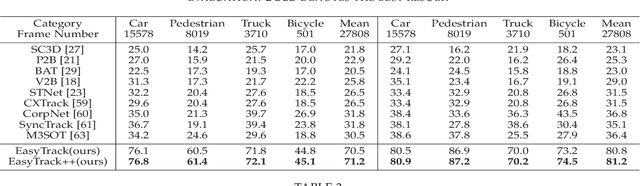
Most of 3D single object trackers (SOT) in point clouds follow the two-stream multi-stage 3D Siamese or motion tracking paradigms, which process the template and search area point clouds with two parallel branches, built on supervised point cloud backbones. In this work, beyond typical 3D Siamese or motion tracking, we propose a neat and compact one-stream transformer 3D SOT paradigm from the novel perspective, termed as \textbf{EasyTrack}, which consists of three special designs: 1) A 3D point clouds tracking feature pre-training module is developed to exploit the masked autoencoding for learning 3D point clouds tracking representations. 2) A unified 3D tracking feature learning and fusion network is proposed to simultaneously learns target-aware 3D features, and extensively captures mutual correlation through the flexible self-attention mechanism. 3) A target location network in the dense bird's eye view (BEV) feature space is constructed for target classification and regression. Moreover, we develop an enhanced version named EasyTrack++, which designs the center points interaction (CPI) strategy to reduce the ambiguous targets caused by the noise point cloud background information. The proposed EasyTrack and EasyTrack++ set a new state-of-the-art performance ($\textbf{18\%}$, $\textbf{40\%}$ and $\textbf{3\%}$ success gains) in KITTI, NuScenes, and Waymo while runing at \textbf{52.6fps} with few parameters (\textbf{1.3M}). The code will be available at https://github.com/KnightApple427/Easytrack.