 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIDDM: Bridging Synthetic-to-Real Domain Gap from Physics-Guided Diffusion for Real-world Image Dehazing
Apr 30, 2025Due to the domain gap between real-world and synthetic hazy images, current data-driven dehazing algorithms trained on synthetic datasets perform well on synthetic data but struggle to generalize to real-world scenarios. To address this challenge, we propose \textbf{I}mage \textbf{D}ehazing \textbf{D}iffusion \textbf{M}odels (IDDM), a novel diffusion process that incorporates the atmospheric scattering model into noise diffusion. IDDM aims to use the gradual haze formation process to help the denoising Unet robustly learn the distribution of clear images from the conditional input hazy images. We design a specialized training strategy centered around IDDM. Diffusion models are leveraged to bridge the domain gap from synthetic to real-world, while the atmospheric scattering model provides physical guidance for haze formation. During the forward process, IDDM simultaneously introduces haze and noise into clear images, and then robustly separates them during the sampling process. By training with physics-guided information, IDDM shows the ability of domain generalization, and effectively restores the real-world hazy images despite being trained on synthetic datasets. Extensive experiments demonstrate the effectiveness of our method through both quantitative and qualitative comparisons with state-of-the-art approaches.
Yi-Lightning Technical Report
Dec 03, 2024



This technical report presents Yi-Lightning, our latest flagship large language model (LLM). It achieves exceptional performance, ranking 6th overall on Chatbot Arena, with particularly strong results (2nd to 4th place) in specialized categories including Chinese, Math, Coding, and Hard Prompts. Yi-Lightning leverages an enhanced Mixture-of-Experts (MoE) architecture, featuring advanced expert segmentation and routing mechanisms coupled with optimized KV-caching techniques. Our development process encompasses comprehensive pre-training, supervised fine-tuning (SFT), and reinforcement learning from human feedback (RLHF), where we devise deliberate strategies for multi-stage training, synthetic data construction, and reward modeling. Furthermore, we implement RAISE (Responsible AI Safety Engine), a four-component framework to address safety issues across pre-training, post-training, and serving phases. Empowered by our scalable super-computing infrastructure, all these innovations substantially reduce training, deployment and inference costs while maintaining high-performance standards. With further evaluations on public academic benchmarks, Yi-Lightning demonstrates competitive performance against top-tier LLMs, while we observe a notable disparity between traditional, static benchmark results and real-world, dynamic human preferences. This observation prompts a critical reassessment of conventional benchmarks' utility in guiding the development of more intelligent and powerful AI systems for practical applications. Yi-Lightning is now available through our developer platform at https://platform.lingyiwanwu.com.
Unbiased Faster R-CNN for Single-source Domain Generalized Object Detection
May 24, 2024

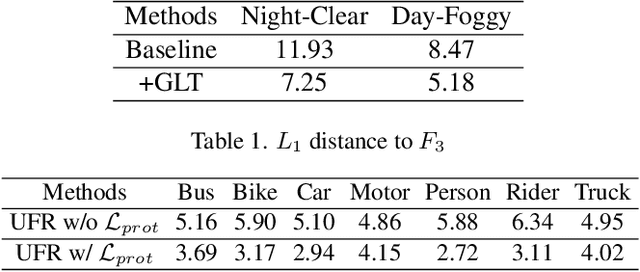

Single-source domain generalization (SDG) for object detection is a challenging yet essential task as the distribution bias of the unseen domain degrades the algorithm performance significantly. However, existing methods attempt to extract domain-invariant features, neglecting that the biased data leads the network to learn biased features that are non-causal and poorly generalizable. To this end, we propose an Unbiased Faster R-CNN (UFR) for generalizable feature learning. Specifically, we formulate SDG in object detection from a causal perspective and construct a Structural Causal Model (SCM) to analyze the data bias and feature bias in the task, which are caused by scene confounders and object attribute confounders. Based on the SCM, we design a Global-Local Transformation module for data augmentation, which effectively simulates domain diversity and mitigates the data bias. Additionally, we introduce a Causal Attention Learning module that incorporates a designed attention invariance loss to learn image-level features that are robust to scene confounders. Moreover, we develop a Causal Prototype Learning module with an explicit instance constraint and an implicit prototype constraint, which further alleviates the negative impact of object attribute confounders. Experimental results on five scenes demonstrate the prominent generalization ability of our method, with an improvement of 3.9% mAP on the Night-Clear scene.
EasyTrack: Efficient and Compact One-stream 3D Point Clouds Tracker
Apr 12, 2024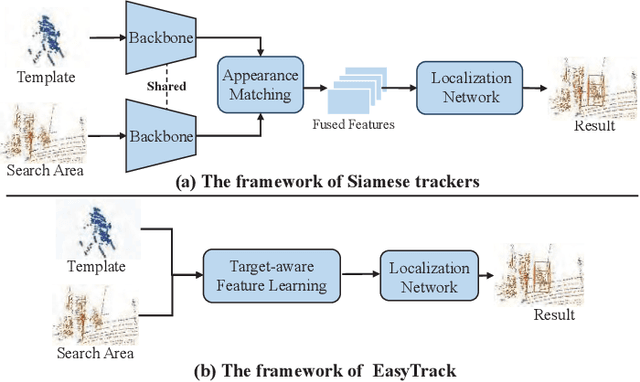
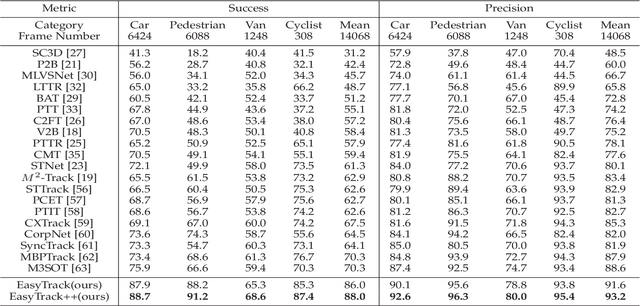
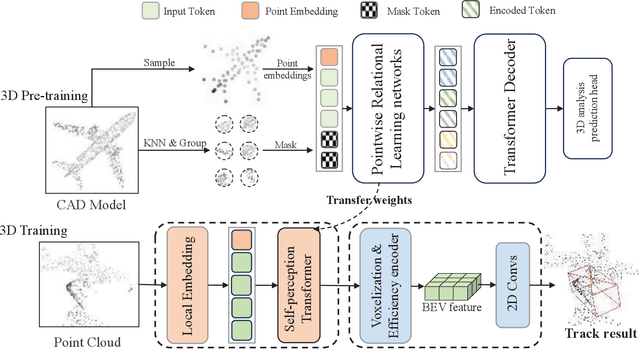
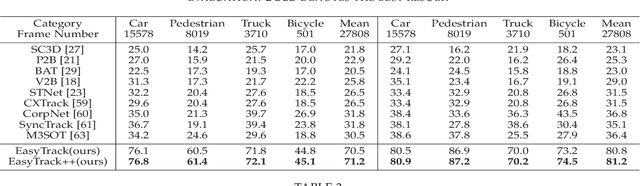
Most of 3D single object trackers (SOT) in point clouds follow the two-stream multi-stage 3D Siamese or motion tracking paradigms, which process the template and search area point clouds with two parallel branches, built on supervised point cloud backbones. In this work, beyond typical 3D Siamese or motion tracking, we propose a neat and compact one-stream transformer 3D SOT paradigm from the novel perspective, termed as \textbf{EasyTrack}, which consists of three special designs: 1) A 3D point clouds tracking feature pre-training module is developed to exploit the masked autoencoding for learning 3D point clouds tracking representations. 2) A unified 3D tracking feature learning and fusion network is proposed to simultaneously learns target-aware 3D features, and extensively captures mutual correlation through the flexible self-attention mechanism. 3) A target location network in the dense bird's eye view (BEV) feature space is constructed for target classification and regression. Moreover, we develop an enhanced version named EasyTrack++, which designs the center points interaction (CPI) strategy to reduce the ambiguous targets caused by the noise point cloud background information. The proposed EasyTrack and EasyTrack++ set a new state-of-the-art performance ($\textbf{18\%}$, $\textbf{40\%}$ and $\textbf{3\%}$ success gains) in KITTI, NuScenes, and Waymo while runing at \textbf{52.6fps} with few parameters (\textbf{1.3M}). The code will be available at https://github.com/KnightApple427/Easytrack.