 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision and Language Integration for Domain Generalization
Apr 17, 2025



Domain generalization aims at training on source domains to uncover a domain-invariant feature space, allowing the model to perform robust generalization ability on unknown target domains. However, due to domain gaps, it is hard to find reliable common image feature space, and the reason for that is the lack of suitable basic units for images. Different from image in vision space, language has comprehensive expression elements that can effectively convey semantics. Inspired by the semantic completeness of language and intuitiveness of image, we propose VLCA, which combine language space and vision space, and connect the multiple image domains by using semantic space as the bridge domain. Specifically, in language space, by taking advantage of the completeness of language basic units, we tend to capture the semantic representation of the relations between categories through word vector distance. Then, in vision space, by taking advantage of the intuitiveness of image features, the common pattern of sample features with the same class is explored through low-rank approximation. In the end, the language representation is aligned with the vision representation through the multimodal space of text and image. Experiments demonstrate the effectiveness of the proposed method.
Unbiased Faster R-CNN for Single-source Domain Generalized Object Detection
May 24, 2024

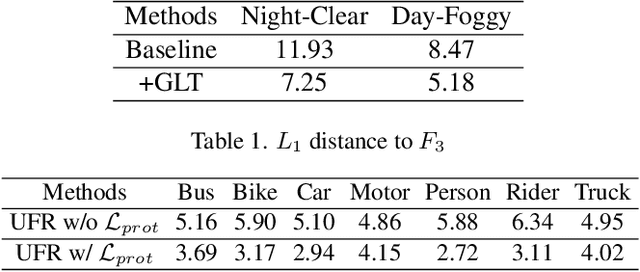

Single-source domain generalization (SDG) for object detection is a challenging yet essential task as the distribution bias of the unseen domain degrades the algorithm performance significantly. However, existing methods attempt to extract domain-invariant features, neglecting that the biased data leads the network to learn biased features that are non-causal and poorly generalizable. To this end, we propose an Unbiased Faster R-CNN (UFR) for generalizable feature learning. Specifically, we formulate SDG in object detection from a causal perspective and construct a Structural Causal Model (SCM) to analyze the data bias and feature bias in the task, which are caused by scene confounders and object attribute confounders. Based on the SCM, we design a Global-Local Transformation module for data augmentation, which effectively simulates domain diversity and mitigates the data bias. Additionally, we introduce a Causal Attention Learning module that incorporates a designed attention invariance loss to learn image-level features that are robust to scene confounders. Moreover, we develop a Causal Prototype Learning module with an explicit instance constraint and an implicit prototype constraint, which further alleviates the negative impact of object attribute confounders. Experimental results on five scenes demonstrate the prominent generalization ability of our method, with an improvement of 3.9% mAP on the Night-Clear scene.
Watermarking in Secure Federated Learning: A Verification Framework Based on Client-Side Backdooring
Nov 14, 2022



Federated learning (FL) allows multiple participants to collaboratively build deep learning (DL) models without directly sharing data. Consequently, the issue of copyright protection in FL becomes important since unreliable participants may gain access to the jointly trained model. Application of homomorphic encryption (HE) in secure FL framework prevents the central server from accessing plaintext models. Thus, it is no longer feasible to embed the watermark at the central server using existing watermarking schemes. In this paper, we propose a novel client-side FL watermarking scheme to tackle the copyright protection issue in secure FL with HE. To our best knowledge, it is the first scheme to embed the watermark to models under the Secure FL environment. We design a black-box watermarking scheme based on client-side backdooring to embed a pre-designed trigger set into an FL model by a gradient-enhanced embedding method. Additionally, we propose a trigger set construction mechanism to ensure the watermark cannot be forged. Experimental results demonstrate that our proposed scheme delivers outstanding protection performance and robustness against various watermark removal attacks and ambiguity attack.
Memorizing Complementation Network for Few-Shot Class-Incremental Learning
Aug 11, 2022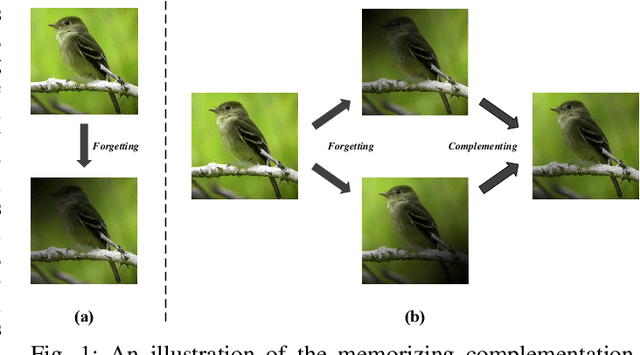
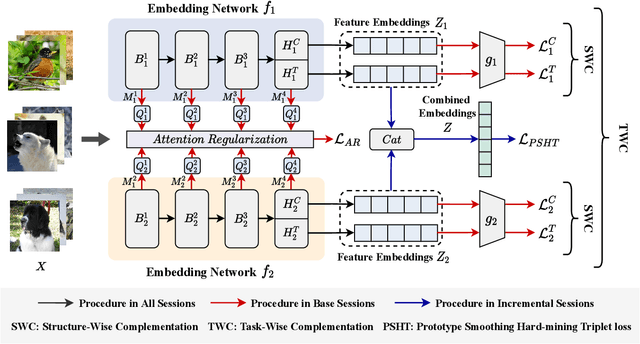
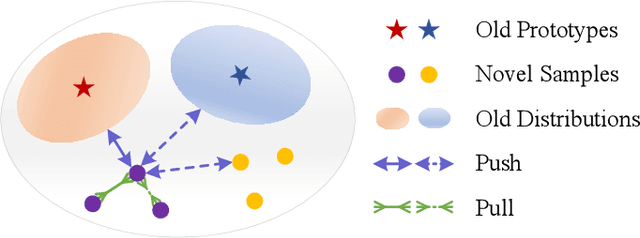
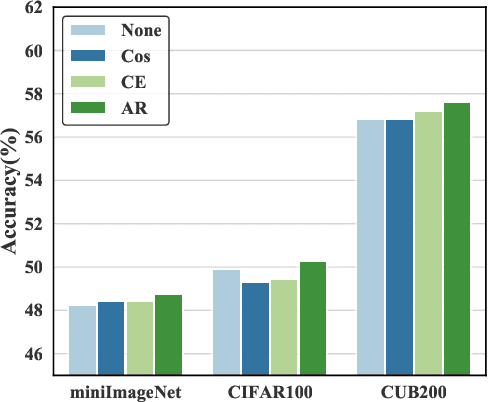
Few-shot Class-Incremental Learning (FSCIL) aims at learning new concepts continually with only a few samples, which is prone to suffer the catastrophic forgetting and overfitting problems. The inaccessibility of old classes and the scarcity of the novel samples make it formidable to realize the trade-off between retaining old knowledge and learning novel concepts. Inspired by that different models memorize different knowledge when learning novel concepts, we propose a Memorizing Complementation Network (MCNet) to ensemble multiple models that complements the different memorized knowledge with each other in novel tasks. Additionally, to update the model with few novel samples, we develop a Prototype Smoothing Hard-mining Triplet (PSHT) loss to push the novel samples away from not only each other in current task but also the old distribution. Extensive experiments on three benchmark datasets, e.g., CIFAR100, miniImageNet and CUB200, have demonstrated the superiority of our proposed method.
MuSCLe: A Multi-Strategy Contrastive Learning Framework for Weakly Supervised Semantic Segmentation
Jan 18, 2022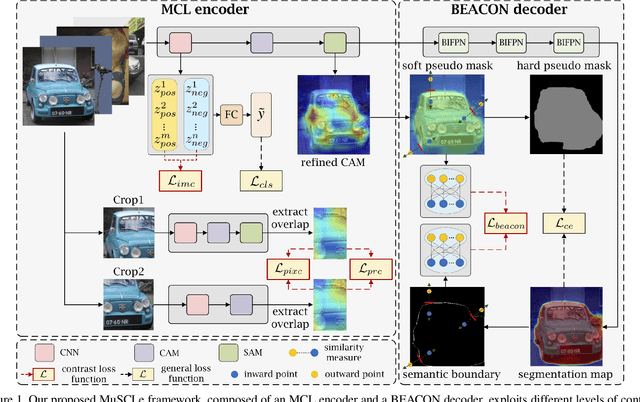
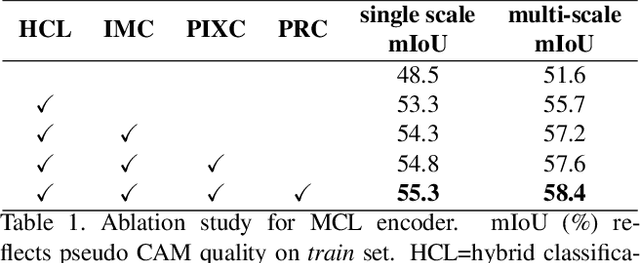
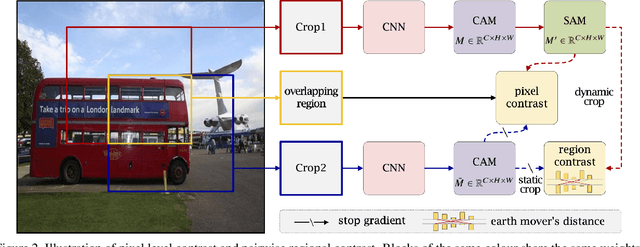
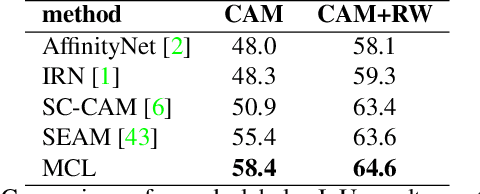
Weakly supervised semantic segmentation (WSSS) has gained significant popularity since it relies only on weak labels such as image level annotations rather than pixel level annotations required by supervised semantic segmentation (SSS) methods. Despite drastically reduced annotation costs, typical feature representations learned from WSSS are only representative of some salient parts of objects and less reliable compared to SSS due to the weak guidance during training. In this paper, we propose a novel Multi-Strategy Contrastive Learning (MuSCLe) framework to obtain enhanced feature representations and improve WSSS performance by exploiting similarity and dissimilarity of contrastive sample pairs at image, region, pixel and object boundary levels. Extensive experiments demonstrate the effectiveness of our method and show that MuSCLe outperforms the current state-of-the-art on the widely used PASCAL VOC 2012 dataset.
Self-Taught Cross-Domain Few-Shot Learning with Weakly Supervised Object Localization and Task-Decomposition
Sep 03, 2021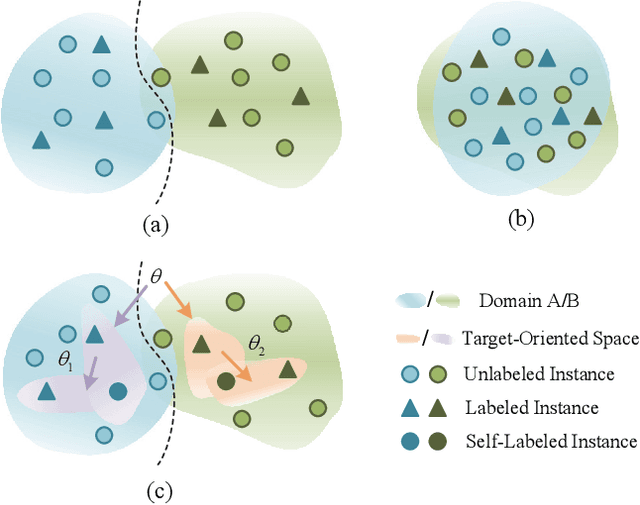

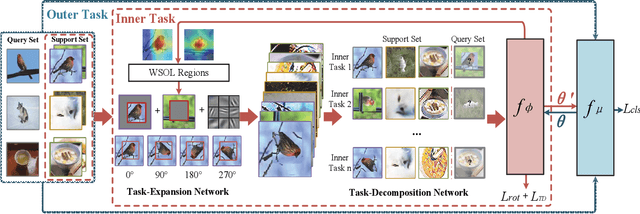
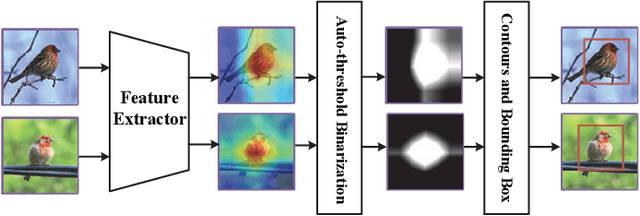
The domain shift between the source and target domain is the main challenge in Cross-Domain Few-Shot Learning (CD-FSL). However, the target domain is absolutely unknown during the training on the source domain, which results in lacking directed guidance for target tasks. We observe that since there are similar backgrounds in target domains, it can apply self-labeled samples as prior tasks to transfer knowledge onto target tasks. To this end, we propose a task-expansion-decomposition framework for CD-FSL, called Self-Taught (ST) approach, which alleviates the problem of non-target guidance by constructing task-oriented metric spaces. Specifically, Weakly Supervised Object Localization (WSOL) and self-supervised technologies are employed to enrich task-oriented samples by exchanging and rotating the discriminative regions, which generates a more abundant task set. Then these tasks are decomposed into several tasks to finish the task of few-shot recognition and rotation classification. It helps to transfer the source knowledge onto the target tasks and focus on discriminative regions. We conduct extensive experiments under the cross-domain setting including 8 target domains: CUB, Cars, Places, Plantae, CropDieases, EuroSAT, ISIC, and ChestX. Experimental results demonstrate that the proposed ST approach is applicable to various metric-based models, and provides promising improvements in CD-FSL.
Information Symmetry Matters: A Modal-Alternating Propagation Network for Few-Shot Learning
Sep 03, 2021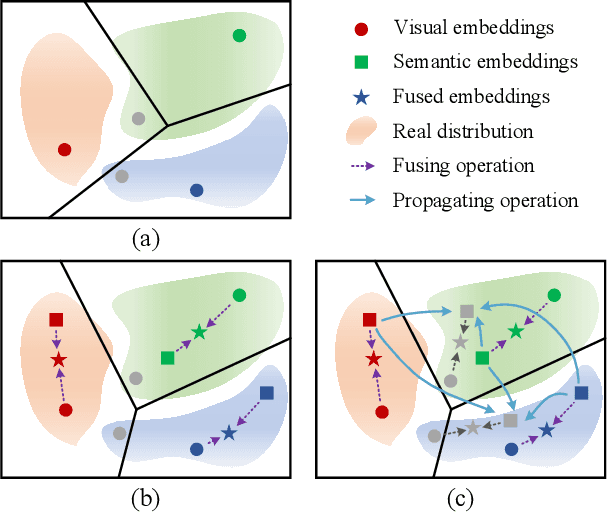

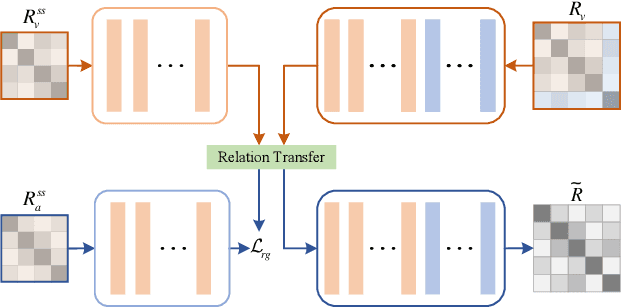
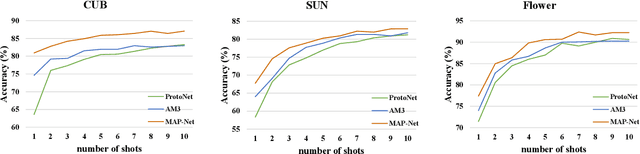
Semantic information provides intra-class consistency and inter-class discriminability beyond visual concepts, which has been employed in Few-Shot Learning (FSL) to achieve further gains. However, semantic information is only available for labeled samples but absent for unlabeled samples, in which the embeddings are rectified unilaterally by guiding the few labeled samples with semantics. Therefore, it is inevitable to bring a cross-modal bias between semantic-guided samples and nonsemantic-guided samples, which results in an information asymmetry problem. To address this problem, we propose a Modal-Alternating Propagation Network (MAP-Net) to supplement the absent semantic information of unlabeled samples, which builds information symmetry among all samples in both visual and semantic modalities. Specifically, the MAP-Net transfers the neighbor information by the graph propagation to generate the pseudo-semantics for unlabeled samples guided by the completed visual relationships and rectify the feature embeddings. In addition, due to the large discrepancy between visual and semantic modalities, we design a Relation Guidance (RG) strategy to guide the visual relation vectors via semantics so that the propagated information is more beneficial. Extensive experimental results on three semantic-labeled datasets, i.e., Caltech-UCSD-Birds 200-2011, SUN Attribute Database, and Oxford 102 Flower, have demonstrated that our proposed method achieves promising performance and outperforms the state-of-the-art approaches, which indicates the necessity of information symmetry.