 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Contrastive Network for Few-Shot Remote Sensing Image Scene Classification
Mar 24, 2026Few-shot remote sensing image scene classification (FS-RSISC) aims at classifying remote sensing images with only a few labeled samples. The main challenges lie in small inter-class variances and large intra-class variances, which are the inherent property of remote sensing images. To address these challenges, we propose a transfer-based Dual Contrastive Network (DCN), which incorporates two auxiliary supervised contrastive learning branches during the training process. Specifically, one is a Context-guided Contrastive Learning (CCL) branch and the other is a Detail-guided Contrastive Learning (DCL) branch, which focus on inter-class discriminability and intra-class invariance, respectively. In the CCL branch, we first devise a Condenser Network to capture context features, and then leverage a supervised contrastive learning on top of the obtained context features to facilitate the model to learn more discriminative features. In the DCL branch, a Smelter Network is designed to highlight the significant local detail information. And then we construct a supervised contrastive learning based on the detail feature maps to fully exploit the spatial information in each map, enabling the model to concentrate on invariant detail features. Extensive experiments on four public benchmark remote sensing datasets demonstrate the competitive performance of our proposed DCN.
FAPE-IR: Frequency-Aware Planning and Execution Framework for All-in-One Image Restoration
Nov 18, 2025All-in-One Image Restoration (AIO-IR) aims to develop a unified model that can handle multiple degradations under complex conditions. However, existing methods often rely on task-specific designs or latent routing strategies, making it hard to adapt to real-world scenarios with various degradations. We propose FAPE-IR, a Frequency-Aware Planning and Execution framework for image restoration. It uses a frozen Multimodal Large Language Model (MLLM) as a planner to analyze degraded images and generate concise, frequency-aware restoration plans. These plans guide a LoRA-based Mixture-of-Experts (LoRA-MoE) module within a diffusion-based executor, which dynamically selects high- or low-frequency experts, complemented by frequency features of the input image. To further improve restoration quality and reduce artifacts, we introduce adversarial training and a frequency regularization loss. By coupling semantic planning with frequency-based restoration, FAPE-IR offers a unified and interpretable solution for all-in-one image restoration. Extensive experiments show that FAPE-IR achieves state-of-the-art performance across seven restoration tasks and exhibits strong zero-shot generalization under mixed degradations.
Interpretable Few-Shot Image Classification via Prototypical Concept-Guided Mixture of LoRA Experts
Jun 05, 2025



Self-Explainable Models (SEMs) rely on Prototypical Concept Learning (PCL) to enable their visual recognition processes more interpretable, but they often struggle in data-scarce settings where insufficient training samples lead to suboptimal performance.To address this limitation, we propose a Few-Shot Prototypical Concept Classification (FSPCC) framework that systematically mitigates two key challenges under low-data regimes: parametric imbalance and representation misalignment. Specifically, our approach leverages a Mixture of LoRA Experts (MoLE) for parameter-efficient adaptation, ensuring a balanced allocation of trainable parameters between the backbone and the PCL module.Meanwhile, cross-module concept guidance enforces tight alignment between the backbone's feature representations and the prototypical concept activation patterns.In addition, we incorporate a multi-level feature preservation strategy that fuses spatial and semantic cues across various layers, thereby enriching the learned representations and mitigating the challenges posed by limited data availability.Finally, to enhance interpretability and minimize concept overlap, we introduce a geometry-aware concept discrimination loss that enforces orthogonality among concepts, encouraging more disentangled and transparent decision boundaries.Experimental results on six popular benchmarks (CUB-200-2011, mini-ImageNet, CIFAR-FS, Stanford Cars, FGVC-Aircraft, and DTD) demonstrate that our approach consistently outperforms existing SEMs by a notable margin, with 4.2%-8.7% relative gains in 5-way 5-shot classification.These findings highlight the efficacy of coupling concept learning with few-shot adaptation to achieve both higher accuracy and clearer model interpretability, paving the way for more transparent visual recognition systems.
How can Diffusion Models Evolve into Continual Generators?
May 17, 2025While diffusion models have achieved remarkable success in static data generation, their deployment in streaming or continual learning (CL) scenarios faces a major challenge: catastrophic forgetting (CF), where newly acquired generative capabilities overwrite previously learned ones. To systematically address this, we introduce a formal Continual Diffusion Generation (CDG) paradigm that characterizes and redefines CL in the context of generative diffusion models. Prior efforts often adapt heuristic strategies from continual classification tasks but lack alignment with the underlying diffusion process. In this work, we develop the first theoretical framework for CDG by analyzing cross-task dynamics in diffusion-based generative modeling. Our analysis reveals that the retention and stability of generative knowledge across tasks are governed by three key consistency criteria: inter-task knowledge consistency (IKC), unconditional knowledge consistency (UKC), and label knowledge consistency (LKC). Building on these insights, we propose Continual Consistency Diffusion (CCD), a principled framework that integrates these consistency objectives into training via hierarchical loss terms $\mathcal{L}_{IKC}$, $\mathcal{L}_{UKC}$, and $\mathcal{L}_{LKC}$. This promotes effective knowledge retention while enabling the assimilation of new generative capabilities. Extensive experiments on four benchmark datasets demonstrate that CCD achieves state-of-the-art performance under continual settings, with substantial gains in Mean Fidelity (MF) and Incremental Mean Fidelity (IMF), particularly in tasks with rich cross-task knowledge overlap.
iEBAKER: Improved Remote Sensing Image-Text Retrieval Framework via Eliminate Before Align and Keyword Explicit Reasoning
Apr 08, 2025



Recent studies focus on the Remote Sensing Image-Text Retrieval (RSITR), which aims at searching for the corresponding targets based on the given query. Among these efforts, the application of Foundation Models (FMs), such as CLIP, to the domain of remote sensing has yielded encouraging outcomes. However, existing FM based methodologies neglect the negative impact of weakly correlated sample pairs and fail to account for the key distinctions among remote sensing texts, leading to biased and superficial exploration of sample pairs. To address these challenges, we propose an approach named iEBAKER (an Improved Eliminate Before Align strategy with Keyword Explicit Reasoning framework) for RSITR. Specifically, we propose an innovative Eliminate Before Align (EBA) strategy to filter out the weakly correlated sample pairs, thereby mitigating their deviations from optimal embedding space during alignment.Further, two specific schemes are introduced from the perspective of whether local similarity and global similarity affect each other. On this basis, we introduce an alternative Sort After Reversed Retrieval (SAR) strategy, aims at optimizing the similarity matrix via reverse retrieval. Additionally, we incorporate a Keyword Explicit Reasoning (KER) module to facilitate the beneficial impact of subtle key concept distinctions. Without bells and whistles, our approach enables a direct transition from FM to RSITR task, eliminating the need for additional pretraining on remote sensing data. Extensive experiments conducted on three popular benchmark datasets demonstrate that our proposed iEBAKER method surpasses the state-of-the-art models while requiring less training data. Our source code will be released at https://github.com/zhangy0822/iEBAKER.
Optimal Transport Adapter Tuning for Bridging Modality Gaps in Few-Shot Remote Sensing Scene Classification
Mar 19, 2025



Few-Shot Remote Sensing Scene Classification (FS-RSSC) presents the challenge of classifying remote sensing images with limited labeled samples. Existing methods typically emphasize single-modal feature learning, neglecting the potential benefits of optimizing multi-modal representations. To address this limitation, we propose a novel Optimal Transport Adapter Tuning (OTAT) framework aimed at constructing an ideal Platonic representational space through optimal transport (OT) theory. This framework seeks to harmonize rich visual information with less dense textual cues, enabling effective cross-modal information transfer and complementarity. Central to this approach is the Optimal Transport Adapter (OTA), which employs a cross-modal attention mechanism to enrich textual representations and facilitate subsequent better information interaction. By transforming the network optimization into an OT optimization problem, OTA establishes efficient pathways for balanced information exchange between modalities. Moreover, we introduce a sample-level Entropy-Aware Weighted (EAW) loss, which combines difficulty-weighted similarity scores with entropy-based regularization. This loss function provides finer control over the OT optimization process, enhancing its solvability and stability. Our framework offers a scalable and efficient solution for advancing multimodal learning in remote sensing applications. Extensive experiments on benchmark datasets demonstrate that OTAT achieves state-of-the-art performance in FS-RSSC, significantly improving the model performance and generalization.
Underlying Semantic Diffusion for Effective and Efficient In-Context Learning
Mar 06, 2025



Diffusion models has emerged as a powerful framework for tasks like image controllable generation and dense prediction. However, existing models often struggle to capture underlying semantics (e.g., edges, textures, shapes) and effectively utilize in-context learning, limiting their contextual understanding and image generation quality. Additionally, high computational costs and slow inference speeds hinder their real-time applicability. To address these challenges, we propose Underlying Semantic Diffusion (US-Diffusion), an enhanced diffusion model that boosts underlying semantics learning, computational efficiency, and in-context learning capabilities on multi-task scenarios. We introduce Separate & Gather Adapter (SGA), which decouples input conditions for different tasks while sharing the architecture, enabling better in-context learning and generalization across diverse visual domains. We also present a Feedback-Aided Learning (FAL) framework, which leverages feedback signals to guide the model in capturing semantic details and dynamically adapting to task-specific contextual cues. Furthermore, we propose a plug-and-play Efficient Sampling Strategy (ESS) for dense sampling at time steps with high-noise levels, which aims at optimizing training and inference efficiency while maintaining strong in-context learning performance. Experimental results demonstrate that US-Diffusion outperforms the state-of-the-art method, achieving an average reduction of 7.47 in FID on Map2Image tasks and an average reduction of 0.026 in RMSE on Image2Map tasks, while achieving approximately 9.45 times faster inference speed. Our method also demonstrates superior training efficiency and in-context learning capabilities, excelling in new datasets and tasks, highlighting its robustness and adaptability across diverse visual domains.
Multi-Stage Knowledge Integration of Vision-Language Models for Continual Learning
Nov 11, 2024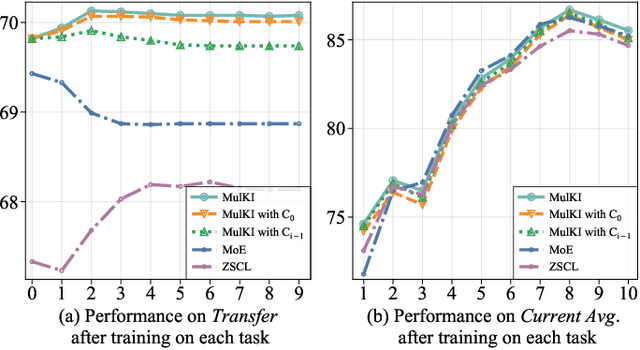
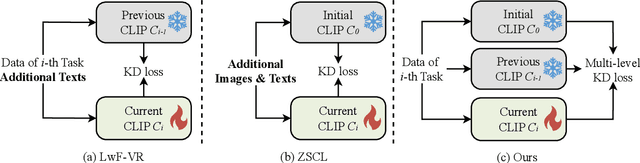
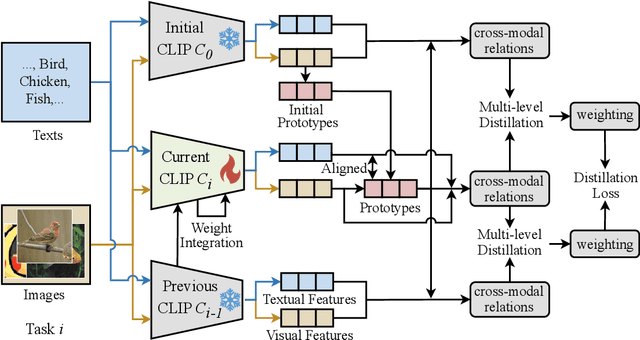
Vision Language Models (VLMs), pre-trained on large-scale image-text datasets, enable zero-shot predictions for unseen data but may underperform on specific unseen tasks. Continual learning (CL) can help VLMs effectively adapt to new data distributions without joint training, but faces challenges of catastrophic forgetting and generalization forgetting. Although significant progress has been achieved by distillation-based methods, they exhibit two severe limitations. One is the popularly adopted single-teacher paradigm fails to impart comprehensive knowledge, The other is the existing methods inadequately leverage the multimodal information in the original training dataset, instead they rely on additional data for distillation, which increases computational and storage overhead. To mitigate both limitations, by drawing on Knowledge Integration Theory (KIT), we propose a Multi-Stage Knowledge Integration network (MulKI) to emulate the human learning process in distillation methods. MulKI achieves this through four stages, including Eliciting Ideas, Adding New Ideas, Distinguishing Ideas, and Making Connections. During the four stages, we first leverage prototypes to align across modalities, eliciting cross-modal knowledge, then adding new knowledge by constructing fine-grained intra- and inter-modality relationships with prototypes. After that, knowledge from two teacher models is adaptively distinguished and re-weighted. Finally, we connect between models from intra- and inter-task, integrating preceding and new knowledge. Our method demonstrates significant improvements in maintaining zero-shot capabilities while supporting continual learning across diverse downstream tasks, showcasing its potential in adapting VLMs to evolving data distributions.
A Fresh Look at Generalized Category Discovery through Non-negative Matrix Factorization
Oct 29, 2024
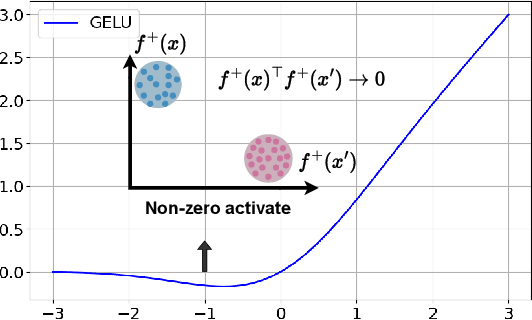


Generalized Category Discovery (GCD) aims to classify both base and novel images using labeled base data. However, current approaches inadequately address the intrinsic optimization of the co-occurrence matrix $\bar{A}$ based on cosine similarity, failing to achieve zero base-novel regions and adequate sparsity in base and novel domains. To address these deficiencies, we propose a Non-Negative Generalized Category Discovery (NN-GCD) framework. It employs Symmetric Non-negative Matrix Factorization (SNMF) as a mathematical medium to prove the equivalence of optimal K-means with optimal SNMF, and the equivalence of SNMF solver with non-negative contrastive learning (NCL) optimization. Utilizing these theoretical equivalences, it reframes the optimization of $\bar{A}$ and K-means clustering as an NCL optimization problem. Moreover, to satisfy the non-negative constraints and make a GCD model converge to a near-optimal region, we propose a GELU activation function and an NMF NCE loss. To transition $\bar{A}$ from a suboptimal state to the desired $\bar{A}^*$, we introduce a hybrid sparse regularization approach to impose sparsity constraints. Experimental results show NN-GCD outperforms state-of-the-art methods on GCD benchmarks, achieving an average accuracy of 66.1\% on the Semantic Shift Benchmark, surpassing prior counterparts by 4.7\%.
Parameter-Efficient Fine-Tuning for Continual Learning: A Neural Tangent Kernel Perspective
Jul 24, 2024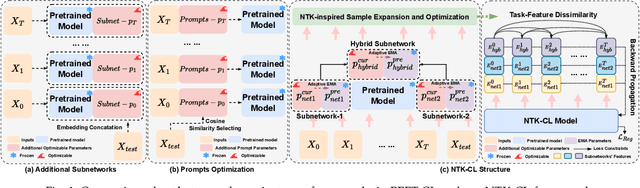
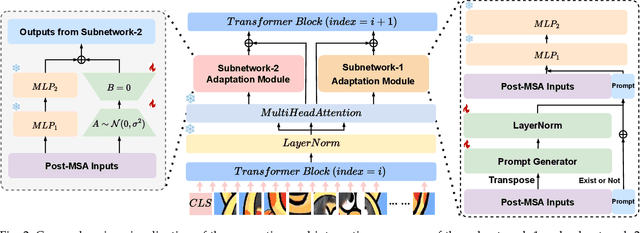
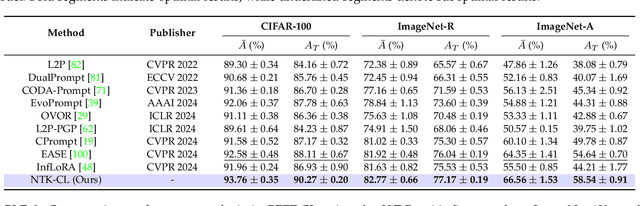
Parameter-efficient fine-tuning for continual learning (PEFT-CL) has shown promise in adapting pre-trained models to sequential tasks while mitigating catastrophic forgetting problem. However, understanding the mechanisms that dictate continual performance in this paradigm remains elusive. To tackle this complexity, we undertake a rigorous analysis of PEFT-CL dynamics to derive relevant metrics for continual scenarios using Neural Tangent Kernel (NTK) theory. With the aid of NTK as a mathematical analysis tool, we recast the challenge of test-time forgetting into the quantifiable generalization gaps during training, identifying three key factors that influence these gaps and the performance of PEFT-CL: training sample size, task-level feature orthogonality, and regularization. To address these challenges, we introduce NTK-CL, a novel framework that eliminates task-specific parameter storage while adaptively generating task-relevant features. Aligning with theoretical guidance, NTK-CL triples the feature representation of each sample, theoretically and empirically reducing the magnitude of both task-interplay and task-specific generalization gaps. Grounded in NTK analysis, our approach imposes an adaptive exponential moving average mechanism and constraints on task-level feature orthogonality, maintaining intra-task NTK forms while attenuating inter-task NTK forms. Ultimately, by fine-tuning optimizable parameters with appropriate regularization, NTK-CL achieves state-of-the-art performance on established PEFT-CL benchmarks. This work provides a theoretical foundation for understanding and improving PEFT-CL models, offering insights into the interplay between feature representation, task orthogonality, and generalization, contributing to the development of more efficient continual learning systems.