 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVIP: Versatile Image Outpainting Empowered by Multimodal Large Language Model
Paper and Code
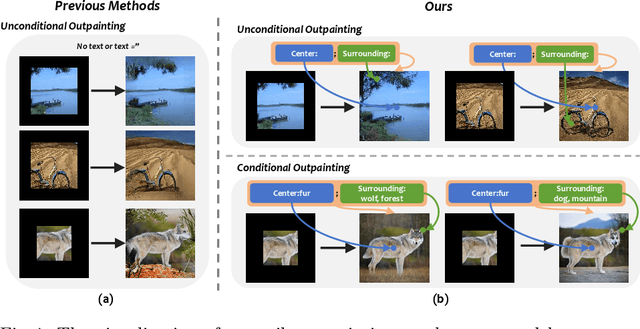
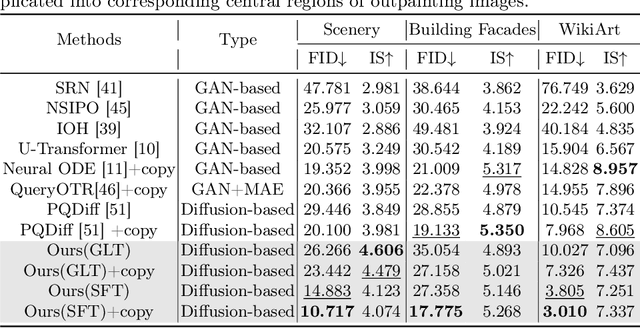
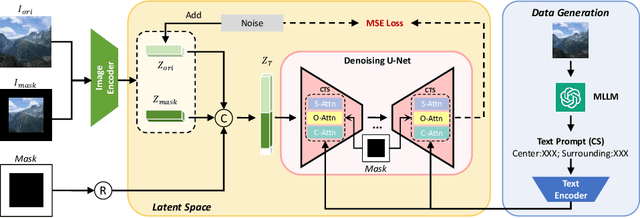
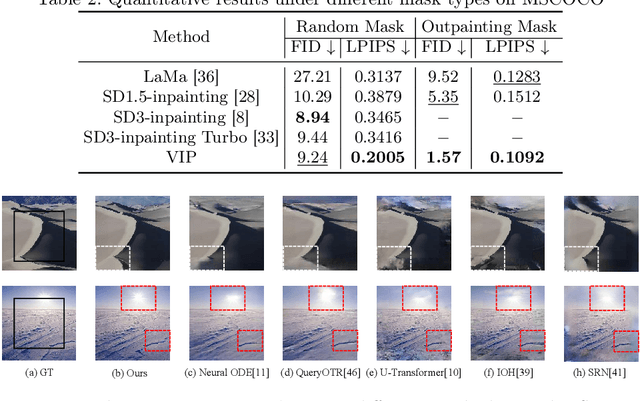
In this paper, we focus on resolving the problem of image outpainting, which aims to extrapolate the surrounding parts given the center contents of an image. Although recent works have achieved promising performance, the lack of versatility and customization hinders their practical applications in broader scenarios. Therefore, this work presents a novel image outpainting framework that is capable of customizing the results according to the requirement of users. First of all, we take advantage of a Multimodal Large Language Model (MLLM) that automatically extracts and organizes the corresponding textual descriptions of the masked and unmasked part of a given image. Accordingly, the obtained text prompts are introduced to endow our model with the capacity to customize the outpainting results. In addition, a special Cross-Attention module, namely Center-Total-Surrounding (CTS), is elaborately designed to enhance further the the interaction between specific space regions of the image and corresponding parts of the text prompts. Note that unlike most existing methods, our approach is very resource-efficient since it is just slightly fine-tuned on the off-the-shelf stable diffusion (SD) model rather than being trained from scratch. Finally, the experimental results on three commonly used datasets, i.e. Scenery, Building, and WikiArt, demonstrate our model significantly surpasses the SoTA methods. Moreover, versatile outpainting results are listed to show its customized ability.