 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Study of Failure Modes in Two-Stage Human-Object Interaction Detection
Apr 15, 2026Human-object interaction (HOI) detection aims to detect interactions between humans and objects in images. While recent advances have improved performance on existing benchmarks, their evaluations mainly focus on overall prediction accuracy and provide limited insight into the underlying causes of model failures. In particular, modern models often struggle in complex scenes involving multiple people and rare interaction combinations. In this work, we present a study to better understand the failure modes of two-stage HOI models, which form the basis of many current HOI detection approaches. Rather than constructing a large-scale benchmark, we instead decompose HOI detection into multiple interpretable perspectives and analyze model behavior across these dimensions to study different types of failure patterns. We curate a subset of images from an existing HOI dataset organized by human-object-interaction configurations (e.g., multi-person interactions and object sharing), and analyze model behavior under these configurations to examine different failure modes. This design allows us to analyze how these HOI models behave under different scene compositions and why their predictions fail. Importantly, high overall benchmark performance does not necessarily reflect robust visual reasoning about human-object relationships. We hope that this study can provide useful insights into the limitations of HOI models and offer observations for future research in this area.
JailWAM: Jailbreaking World Action Models in Robot Control
Apr 07, 2026The World Action Model (WAM) can jointly predict future world states and actions, exhibiting stronger physical manipulation capabilities compared with traditional models. Such powerful physical interaction ability is a double-edged sword: if safety is ignored, it will directly threaten personal safety, property security and environmental safety. However, existing research pays extremely limited attention to the critical security gap: the vulnerability of WAM to jailbreak attacks. To fill this gap, we define the Three-Level Safety Classification Framework to systematically quantify the safety of robotic arm motions. Furthermore, we propose JailWAM, the first dedicated jailbreak attack and evaluation framework for WAM, which consists of three core components: (1) Visual-Trajectory Mapping, which unifies heterogeneous action spaces into visual trajectory representations and enables cross-architectural unified evaluation; (2) Risk Discriminator, which serves as a high-recall screening tool that optimizes the efficiency-accuracy trade-off when identifying destructive behaviors in visual trajectories; (3) Dual-Path Verification Strategy, which first conducts rapid coarse screening via a single-image-based video-action generation module, and then performs efficient and comprehensive verification through full closed-loop physical simulation. In addition, we construct JailWAM-Bench, a benchmark for comprehensively evaluating the safety alignment performance of WAM under jailbreak attacks. Experiments in RoboTwin simulation environment demonstrate that the proposed framework efficiently exposes physical vulnerabilities, achieving an 84.2% attack success rate on the state-of-the-art LingBot-VA. Meanwhile, robust defense mechanisms can be constructed based on JailWAM, providing an effective technical solution for designing safe and reliable robot control systems.
Lessons and Open Questions from a Unified Study of Camera-Trap Species Recognition Over Time
Mar 20, 2026Camera traps are vital for large-scale biodiversity monitoring, yet accurate automated analysis remains challenging due to diverse deployment environments. While the computer vision community has mostly framed this challenge as cross-domain generalization, this perspective overlooks a primary challenge faced by ecological practitioners: maintaining reliable recognition at the fixed site over time, where the dynamic nature of ecosystems introduces profound temporal shifts in both background and animal distributions. To bridge this gap, we present the first unified study of camera-trap species recognition over time. We introduce a realistic benchmark comprising 546 camera traps with a streaming protocol that evaluates models over chronologically ordered intervals. Our end-user-centric study yields four key findings. (1) Biological foundation models (e.g., BioCLIP 2) underperform at numerous sites even in initial intervals, underscoring the necessity of site-specific adaptation. (2) Adaptation is challenging under realistic evaluation: when models are updated using past data and evaluated on future intervals (mirrors real deployment lifecycles), naive adaptation can even degrade below zero-shot performance. (3) We identify two drivers of this difficulty: severe class imbalance and pronounced temporal shift in both species distribution and backgrounds between consecutive intervals. (4) We find that effective integration of model-update and post-processing techniques can largely improve accuracy, though a gap from the upper bounds remains. Finally, we highlight critical open questions, such as predicting when zero-shot models will succeed at a new site and determining whether/when model updates are necessary. Our benchmark and analysis provide actionable deployment guidelines for ecological practitioners while establishing new directions for future research in vision and machine learning.
When the Prompt Becomes Visual: Vision-Centric Jailbreak Attacks for Large Image Editing Models
Feb 10, 2026Recent advances in large image editing models have shifted the paradigm from text-driven instructions to vision-prompt editing, where user intent is inferred directly from visual inputs such as marks, arrows, and visual-text prompts. While this paradigm greatly expands usability, it also introduces a critical and underexplored safety risk: the attack surface itself becomes visual. In this work, we propose Vision-Centric Jailbreak Attack (VJA), the first visual-to-visual jailbreak attack that conveys malicious instructions purely through visual inputs. To systematically study this emerging threat, we introduce IESBench, a safety-oriented benchmark for image editing models. Extensive experiments on IESBench demonstrate that VJA effectively compromises state-of-the-art commercial models, achieving attack success rates of up to 80.9% on Nano Banana Pro and 70.1% on GPT-Image-1.5. To mitigate this vulnerability, we propose a training-free defense based on introspective multimodal reasoning, which substantially improves the safety of poorly aligned models to a level comparable with commercial systems, without auxiliary guard models and with negligible computational overhead. Our findings expose new vulnerabilities, provide both a benchmark and practical defense to advance safe and trustworthy modern image editing systems. Warning: This paper contains offensive images created by large image editing models.
Learning a Shape-adaptive Assist-as-needed Rehabilitation Policy from Therapist-informed Input
Oct 06, 2025Therapist-in-the-loop robotic rehabilitation has shown great promise in enhancing rehabilitation outcomes by integrating the strengths of therapists and robotic systems. However, its broader adoption remains limited due to insufficient safe interaction and limited adaptation capability. This article proposes a novel telerobotics-mediated framework that enables therapists to intuitively and safely deliver assist-as-needed~(AAN) therapy based on two primary contributions. First, our framework encodes the therapist-informed corrective force into via-points in a latent space, allowing the therapist to provide only minimal assistance while encouraging patient maintaining own motion preferences. Second, a shape-adaptive ANN rehabilitation policy is learned to partially and progressively deform the reference trajectory for movement therapy based on encoded patient motion preferences and therapist-informed via-points. The effectiveness of the proposed shape-adaptive AAN strategy was validated on a telerobotic rehabilitation system using two representative tasks. The results demonstrate its practicality for remote AAN therapy and its superiority over two state-of-the-art methods in reducing corrective force and improving movement smoothness.
AVA-Bench: Atomic Visual Ability Benchmark for Vision Foundation Models
Jun 10, 2025



The rise of vision foundation models (VFMs) calls for systematic evaluation. A common approach pairs VFMs with large language models (LLMs) as general-purpose heads, followed by evaluation on broad Visual Question Answering (VQA) benchmarks. However, this protocol has two key blind spots: (i) the instruction tuning data may not align with VQA test distributions, meaning a wrong prediction can stem from such data mismatch rather than a VFM' visual shortcomings; (ii) VQA benchmarks often require multiple visual abilities, making it hard to tell whether errors stem from lacking all required abilities or just a single critical one. To address these gaps, we introduce AVA-Bench, the first benchmark that explicitly disentangles 14 Atomic Visual Abilities (AVAs) -- foundational skills like localization, depth estimation, and spatial understanding that collectively support complex visual reasoning tasks. By decoupling AVAs and matching training and test distributions within each, AVA-Bench pinpoints exactly where a VFM excels or falters. Applying AVA-Bench to leading VFMs thus reveals distinctive "ability fingerprints," turning VFM selection from educated guesswork into principled engineering. Notably, we find that a 0.5B LLM yields similar VFM rankings as a 7B LLM while cutting GPU hours by 8x, enabling more efficient evaluation. By offering a comprehensive and transparent benchmark, we hope AVA-Bench lays the foundation for the next generation of VFMs.
BrainNetMLP: An Efficient and Effective Baseline for Functional Brain Network Classification
May 14, 2025Recent studies have made great progress in functional brain network classification by modeling the brain as a network of Regions of Interest (ROIs) and leveraging their connections to understand brain functionality and diagnose mental disorders. Various deep learning architectures, including Convolutional Neural Networks, Graph Neural Networks, and the recent Transformer, have been developed. However, despite the increasing complexity of these models, the performance gain has not been as salient. This raises a question: Does increasing model complexity necessarily lead to higher classification accuracy? In this paper, we revisit the simplest deep learning architecture, the Multi-Layer Perceptron (MLP), and propose a pure MLP-based method, named BrainNetMLP, for functional brain network classification, which capitalizes on the advantages of MLP, including efficient computation and fewer parameters. Moreover, BrainNetMLP incorporates a dual-branch structure to jointly capture both spatial connectivity and spectral information, enabling precise spatiotemporal feature fusion. We evaluate our proposed BrainNetMLP on two public and popular brain network classification datasets, the Human Connectome Project (HCP) and the Autism Brain Imaging Data Exchange (ABIDE). Experimental results demonstrate pure MLP-based methods can achieve state-of-the-art performance, revealing the potential of MLP-based models as more efficient yet effective alternatives in functional brain network classification. The code will be available at https://github.com/JayceonHo/BrainNetMLP.
Signal Processing over Time-Varying Graphs: A Systematic Review
Nov 30, 2024



As irregularly structured data representations, graphs have received a large amount of attention in recent years and have been widely applied to various real-world scenarios such as social, traffic, and energy settings. Compared to non-graph algorithms, numerous graph-based methodologies benefited from the strong power of graphs for representing high-dimensional and non-Euclidean data. In the field of Graph Signal Processing (GSP), analogies of classical signal processing concepts, such as shifting, convolution, filtering, and transformations are developed. However, many GSP techniques usually postulate the graph is static in both signal and typology. This assumption hinders the effectiveness of GSP methodologies as the assumption ignores the time-varying properties in numerous real-world systems. For example, in the traffic network, the signal on each node varies over time and contains underlying temporal correlation and patterns worthy of analysis. To tackle this challenge, more and more work are being done recently to investigate the processing of time-varying graph signals. They cope with time-varying challenges from three main directions: 1) graph time-spectral filtering, 2) multi-variate time-series forecasting, and 3) spatiotemporal graph data mining by neural networks, where non-negligible progress has been achieved. Despite the success of signal processing and learning over time-varying graphs, there is no survey to compare and conclude the current methodology for GSP and graph learning. To compensate for this, in this paper, we aim to review the development and recent progress on signal processing and learning over time-varying graphs, and compare their advantages and disadvantages from both the methodological and experimental side, to outline the challenges and potential research directions for future research.
Raformer: Redundancy-Aware Transformer for Video Wire Inpainting
Apr 24, 2024
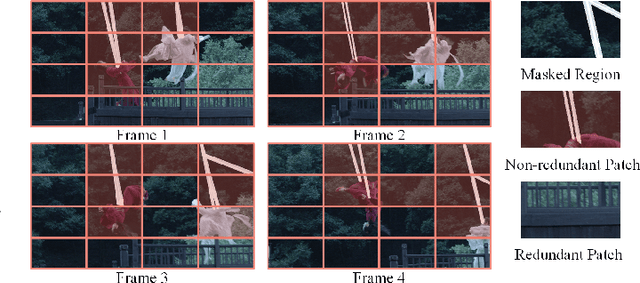
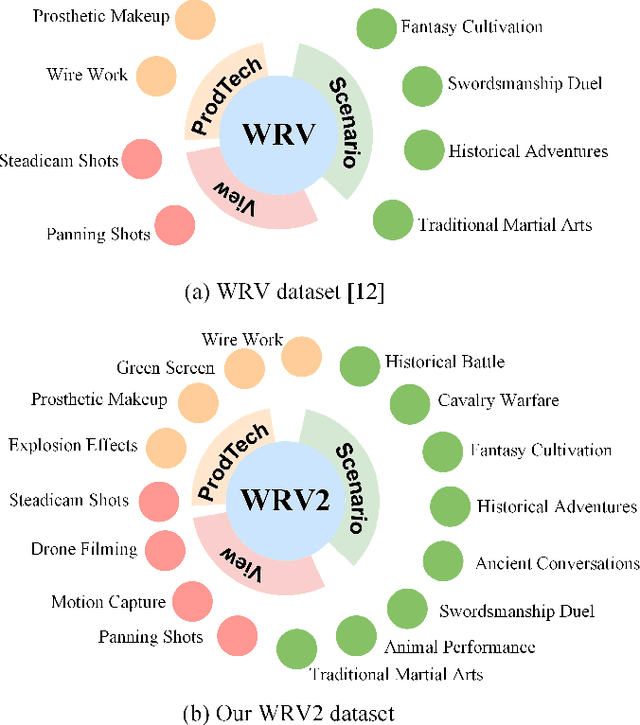

Video Wire Inpainting (VWI) is a prominent application in video inpainting, aimed at flawlessly removing wires in films or TV series, offering significant time and labor savings compared to manual frame-by-frame removal. However, wire removal poses greater challenges due to the wires being longer and slimmer than objects typically targeted in general video inpainting tasks, and often intersecting with people and background objects irregularly, which adds complexity to the inpainting process. Recognizing the limitations posed by existing video wire datasets, which are characterized by their small size, poor quality, and limited variety of scenes, we introduce a new VWI dataset with a novel mask generation strategy, namely Wire Removal Video Dataset 2 (WRV2) and Pseudo Wire-Shaped (PWS) Masks. WRV2 dataset comprises over 4,000 videos with an average length of 80 frames, designed to facilitate the development and efficacy of inpainting models. Building upon this, our research proposes the Redundancy-Aware Transformer (Raformer) method that addresses the unique challenges of wire removal in video inpainting. Unlike conventional approaches that indiscriminately process all frame patches, Raformer employs a novel strategy to selectively bypass redundant parts, such as static background segments devoid of valuable information for inpainting. At the core of Raformer is the Redundancy-Aware Attention (RAA) module, which isolates and accentuates essential content through a coarse-grained, window-based attention mechanism. This is complemented by a Soft Feature Alignment (SFA) module, which refines these features and achieves end-to-end feature alignment. Extensive experiments on both the traditional video inpainting datasets and our proposed WRV2 dataset demonstrate that Raformer outperforms other state-of-the-art methods.