 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameter-Efficient Fine-Tuning for Continual Learning: A Neural Tangent Kernel Perspective
Jul 24, 2024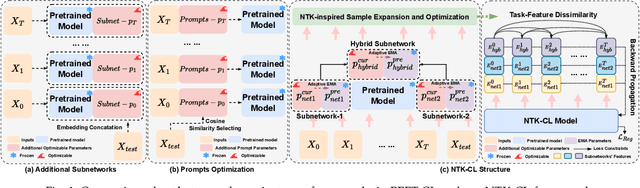
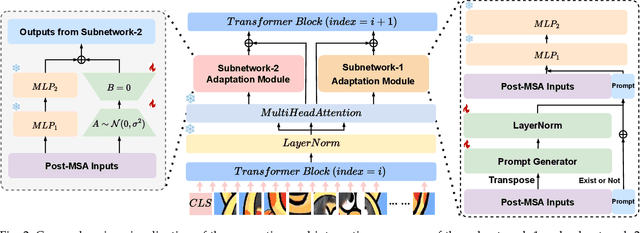
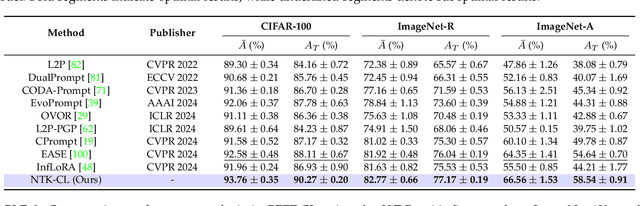
Parameter-efficient fine-tuning for continual learning (PEFT-CL) has shown promise in adapting pre-trained models to sequential tasks while mitigating catastrophic forgetting problem. However, understanding the mechanisms that dictate continual performance in this paradigm remains elusive. To tackle this complexity, we undertake a rigorous analysis of PEFT-CL dynamics to derive relevant metrics for continual scenarios using Neural Tangent Kernel (NTK) theory. With the aid of NTK as a mathematical analysis tool, we recast the challenge of test-time forgetting into the quantifiable generalization gaps during training, identifying three key factors that influence these gaps and the performance of PEFT-CL: training sample size, task-level feature orthogonality, and regularization. To address these challenges, we introduce NTK-CL, a novel framework that eliminates task-specific parameter storage while adaptively generating task-relevant features. Aligning with theoretical guidance, NTK-CL triples the feature representation of each sample, theoretically and empirically reducing the magnitude of both task-interplay and task-specific generalization gaps. Grounded in NTK analysis, our approach imposes an adaptive exponential moving average mechanism and constraints on task-level feature orthogonality, maintaining intra-task NTK forms while attenuating inter-task NTK forms. Ultimately, by fine-tuning optimizable parameters with appropriate regularization, NTK-CL achieves state-of-the-art performance on established PEFT-CL benchmarks. This work provides a theoretical foundation for understanding and improving PEFT-CL models, offering insights into the interplay between feature representation, task orthogonality, and generalization, contributing to the development of more efficient continual learning systems.
NTK-Guided Few-Shot Class Incremental Learning
Mar 19, 2024While anti-amnesia FSCIL learners often excel in incremental sessions, they tend to prioritize mitigating knowledge attrition over harnessing the model's potential for knowledge acquisition. In this paper, we delve into the foundations of model generalization in FSCIL through the lens of the Neural Tangent Kernel (NTK). Our primary design focus revolves around ensuring optimal NTK convergence and NTK-related generalization error, serving as the theoretical bedrock for exceptional generalization. To attain globally optimal NTK convergence, we employ a meta-learning mechanism grounded in mathematical principles to guide the optimization process within an expanded network. Furthermore, to reduce the NTK-related generalization error, we commence from the foundational level, optimizing the relevant factors constituting its generalization loss. Specifically, we initiate self-supervised pre-training on the base session to shape the initial network weights. Then they are carefully refined through curricular alignment, followed by the application of dual NTK regularization tailored specifically for both convolutional and linear layers. Through the combined effects of these measures, our network acquires robust NTK properties, significantly enhancing its foundational generalization. On popular FSCIL benchmark datasets, our NTK-FSCIL surpasses contemporary state-of-the-art approaches, elevating end-session accuracy by 2.9% to 8.7%.