 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameter-Efficient Fine-Tuning for Continual Learning: A Neural Tangent Kernel Perspective
Paper and Code
Jul 24, 2024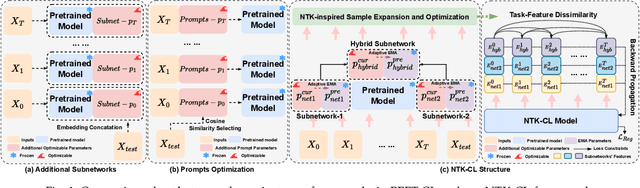
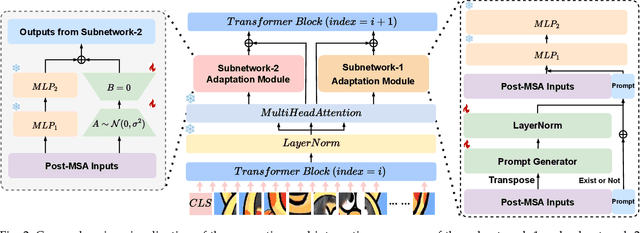
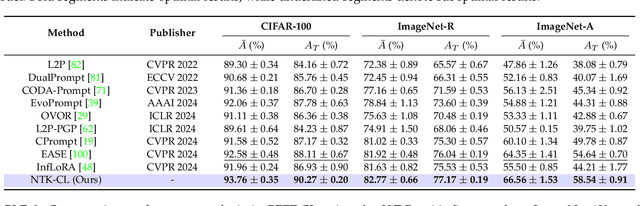
Parameter-efficient fine-tuning for continual learning (PEFT-CL) has shown promise in adapting pre-trained models to sequential tasks while mitigating catastrophic forgetting problem. However, understanding the mechanisms that dictate continual performance in this paradigm remains elusive. To tackle this complexity, we undertake a rigorous analysis of PEFT-CL dynamics to derive relevant metrics for continual scenarios using Neural Tangent Kernel (NTK) theory. With the aid of NTK as a mathematical analysis tool, we recast the challenge of test-time forgetting into the quantifiable generalization gaps during training, identifying three key factors that influence these gaps and the performance of PEFT-CL: training sample size, task-level feature orthogonality, and regularization. To address these challenges, we introduce NTK-CL, a novel framework that eliminates task-specific parameter storage while adaptively generating task-relevant features. Aligning with theoretical guidance, NTK-CL triples the feature representation of each sample, theoretically and empirically reducing the magnitude of both task-interplay and task-specific generalization gaps. Grounded in NTK analysis, our approach imposes an adaptive exponential moving average mechanism and constraints on task-level feature orthogonality, maintaining intra-task NTK forms while attenuating inter-task NTK forms. Ultimately, by fine-tuning optimizable parameters with appropriate regularization, NTK-CL achieves state-of-the-art performance on established PEFT-CL benchmarks. This work provides a theoretical foundation for understanding and improving PEFT-CL models, offering insights into the interplay between feature representation, task orthogonality, and generalization, contributing to the development of more efficient continual learning systems.