 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsistency-Regularized GAN for Few-Shot SAR Target Recognition
Jan 22, 2026Few-shot recognition in synthetic aperture radar (SAR) imagery remains a critical bottleneck for real-world applications due to extreme data scarcity. A promising strategy involves synthesizing a large dataset with a generative adversarial network (GAN), pre-training a model via self-supervised learning (SSL), and then fine-tuning on the few labeled samples. However, this approach faces a fundamental paradox: conventional GANs themselves require abundant data for stable training, contradicting the premise of few-shot learning. To resolve this, we propose the consistency-regularized generative adversarial network (Cr-GAN), a novel framework designed to synthesize diverse, high-fidelity samples even when trained under these severe data limitations. Cr-GAN introduces a dual-branch discriminator that decouples adversarial training from representation learning. This architecture enables a channel-wise feature interpolation strategy to create novel latent features, complemented by a dual-domain cycle consistency mechanism that ensures semantic integrity. Our Cr-GAN framework is adaptable to various GAN architectures, and its synthesized data effectively boosts multiple SSL algorithms. Extensive experiments on the MSTAR and SRSDD datasets validate our approach, with Cr-GAN achieving a highly competitive accuracy of 71.21% and 51.64%, respectively, in the 8-shot setting, significantly outperforming leading baselines, while requiring only ~5 of the parameters of state-of-the-art diffusion models. Code is available at: https://github.com/yikuizhai/Cr-GAN.
Democratizing planetary-scale analysis: An ultra-lightweight Earth embedding database for accurate and flexible global land monitoring
Jan 16, 2026The rapid evolution of satellite-borne Earth Observation (EO) systems has revolutionized terrestrial monitoring, yielding petabyte-scale archives. However, the immense computational and storage requirements for global-scale analysis often preclude widespread use, hindering planetary-scale studies. To address these barriers, we present Embedded Seamless Data (ESD), an ultra-lightweight, 30-m global Earth embedding database spanning the 25-year period from 2000 to 2024. By transforming high-dimensional, multi-sensor observations from the Landsat series (5, 7, 8, and 9) and MODIS Terra into information-dense, quantized latent vectors, ESD distills essential geophysical and semantic features into a unified latent space. Utilizing the ESDNet architecture and Finite Scalar Quantization (FSQ), the dataset achieves a transformative ~340-fold reduction in data volume compared to raw archives. This compression allows the entire global land surface for a single year to be encapsulated within approximately 2.4 TB, enabling decadal-scale global analysis on standard local workstations. Rigorous validation demonstrates high reconstructive fidelity (MAE: 0.0130; RMSE: 0.0179; CC: 0.8543). By condensing the annual phenological cycle into 12 temporal steps, the embeddings provide inherent denoising and a semantically organized space that outperforms raw reflectance in land-cover classification, achieving 79.74% accuracy (vs. 76.92% for raw fusion). With robust few-shot learning capabilities and longitudinal consistency, ESD provides a versatile foundation for democratizing planetary-scale research and advancing next-generation geospatial artificial intelligence.
Wetland mapping from sparse annotations with satellite image time series and temporal-aware segment anything model
Jan 16, 2026Accurate wetland mapping is essential for ecosystem monitoring, yet dense pixel-level annotation is prohibitively expensive and practical applications usually rely on sparse point labels, under which existing deep learning models perform poorly, while strong seasonal and inter-annual wetland dynamics further render single-date imagery inadequate and lead to significant mapping errors; although foundation models such as SAM show promising generalization from point prompts, they are inherently designed for static images and fail to model temporal information, resulting in fragmented masks in heterogeneous wetlands. To overcome these limitations, we propose WetSAM, a SAM-based framework that integrates satellite image time series for wetland mapping from sparse point supervision through a dual-branch design, where a temporally prompted branch extends SAM with hierarchical adapters and dynamic temporal aggregation to disentangle wetland characteristics from phenological variability, and a spatial branch employs a temporally constrained region-growing strategy to generate reliable dense pseudo-labels, while a bidirectional consistency regularization jointly optimizes both branches. Extensive experiments across eight global regions of approximately 5,000 km2 each demonstrate that WetSAM substantially outperforms state-of-the-art methods, achieving an average F1-score of 85.58%, and delivering accurate and structurally consistent wetland segmentation with minimal labeling effort, highlighting its strong generalization capability and potential for scalable, low-cost, high-resolution wetland mapping.
OCCDiff: Occupancy Diffusion Model for High-Fidelity 3D Building Reconstruction from Noisy Point Clouds
Dec 09, 2025A major challenge in reconstructing buildings from LiDAR point clouds lies in accurately capturing building surfaces under varying point densities and noise interference. To flexibly gather high-quality 3D profiles of the building in diverse resolution, we propose OCCDiff applying latent diffusion in the occupancy function space. Our OCCDiff combines a latent diffusion process with a function autoencoder architecture to generate continuous occupancy functions evaluable at arbitrary locations. Moreover, a point encoder is proposed to provide condition features to diffusion learning, constraint the final occupancy prediction for occupancy decoder, and insert multi-modal features for latent generation to latent encoder. To further enhance the model performance, a multi-task training strategy is employed, ensuring that the point encoder learns diverse and robust feature representations. Empirical results show that our method generates physically consistent samples with high fidelity to the target distribution and exhibits robustness to noisy data.
Multimodal Feature Fusion Network with Text Difference Enhancement for Remote Sensing Change Detection
Sep 04, 2025Although deep learning has advanced remote sensing change detection (RSCD), most methods rely solely on image modality, limiting feature representation, change pattern modeling, and generalization especially under illumination and noise disturbances. To address this, we propose MMChange, a multimodal RSCD method that combines image and text modalities to enhance accuracy and robustness. An Image Feature Refinement (IFR) module is introduced to highlight key regions and suppress environmental noise. To overcome the semantic limitations of image features, we employ a vision language model (VLM) to generate semantic descriptions of bitemporal images. A Textual Difference Enhancement (TDE) module then captures fine grained semantic shifts, guiding the model toward meaningful changes. To bridge the heterogeneity between modalities, we design an Image Text Feature Fusion (ITFF) module that enables deep cross modal integration. Extensive experiments on LEVIRCD, WHUCD, and SYSUCD demonstrate that MMChange consistently surpasses state of the art methods across multiple metrics, validating its effectiveness for multimodal RSCD. Code is available at: https://github.com/yikuizhai/MMChange.
A comprehensive review of remote sensing in wetland classification and mapping
Apr 15, 2025Wetlands constitute critical ecosystems that support both biodiversity and human well-being; however, they have experienced a significant decline since the 20th century. Back in the 1970s, researchers began to employ remote sensing technologies for wetland classification and mapping to elucidate the extent and variations of wetlands. Although some review articles summarized the development of this field, there is a lack of a thorough and in-depth understanding of wetland classification and mapping: (1) the scientific importance of wetlands, (2) major data, methods used in wetland classification and mapping, (3) driving factors of wetland changes, (4) current research paradigm and limitations, (5) challenges and opportunities in wetland classification and mapping under the context of technological innovation and global environmental change. In this review, we aim to provide a comprehensive perspective and new insights into wetland classification and mapping for readers to answer these questions. First, we conduct a meta-analysis of over 1,200 papers, encompassing wetland types, methods, sensor types, and study sites, examining prevailing trends in wetland classification and mapping. Next, we review and synthesize the wetland features and existing data and methods in wetland classification and mapping. We also summarize typical wetland mapping products and explore the intrinsic driving factors of wetland changes across multiple spatial and temporal scales. Finally, we discuss current limitations and propose future directions in response to global environmental change and technological innovation. This review consolidates our understanding of wetland remote sensing and offers scientific recommendations that foster transformative progress in wetland science.
Multi-Stage Knowledge Integration of Vision-Language Models for Continual Learning
Nov 11, 2024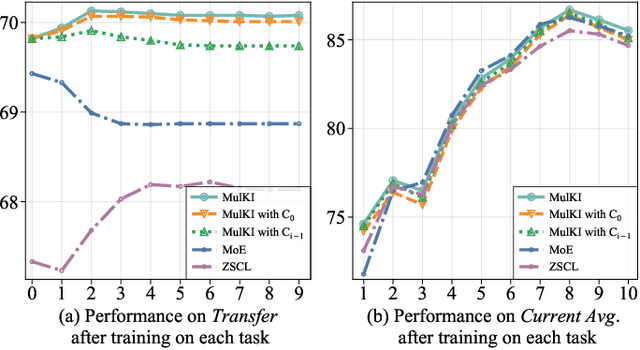
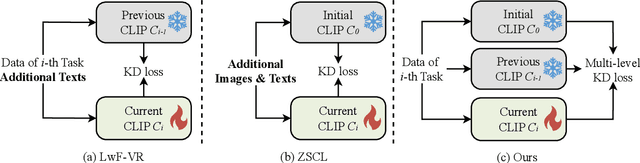
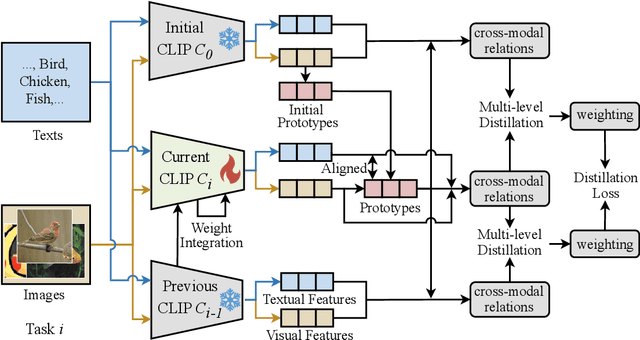
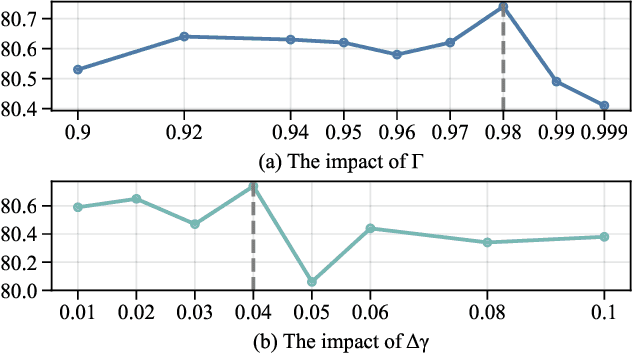
Vision Language Models (VLMs), pre-trained on large-scale image-text datasets, enable zero-shot predictions for unseen data but may underperform on specific unseen tasks. Continual learning (CL) can help VLMs effectively adapt to new data distributions without joint training, but faces challenges of catastrophic forgetting and generalization forgetting. Although significant progress has been achieved by distillation-based methods, they exhibit two severe limitations. One is the popularly adopted single-teacher paradigm fails to impart comprehensive knowledge, The other is the existing methods inadequately leverage the multimodal information in the original training dataset, instead they rely on additional data for distillation, which increases computational and storage overhead. To mitigate both limitations, by drawing on Knowledge Integration Theory (KIT), we propose a Multi-Stage Knowledge Integration network (MulKI) to emulate the human learning process in distillation methods. MulKI achieves this through four stages, including Eliciting Ideas, Adding New Ideas, Distinguishing Ideas, and Making Connections. During the four stages, we first leverage prototypes to align across modalities, eliciting cross-modal knowledge, then adding new knowledge by constructing fine-grained intra- and inter-modality relationships with prototypes. After that, knowledge from two teacher models is adaptively distinguished and re-weighted. Finally, we connect between models from intra- and inter-task, integrating preceding and new knowledge. Our method demonstrates significant improvements in maintaining zero-shot capabilities while supporting continual learning across diverse downstream tasks, showcasing its potential in adapting VLMs to evolving data distributions.
Superpixel-based and Spatially-regularized Diffusion Learning for Unsupervised Hyperspectral Image Clustering
Dec 24, 2023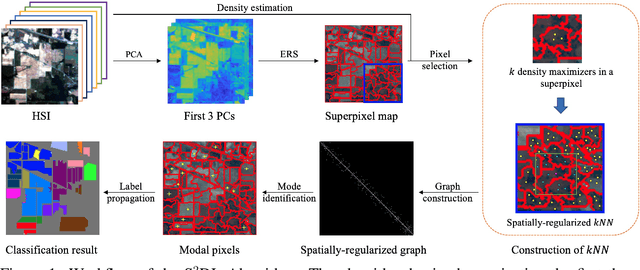
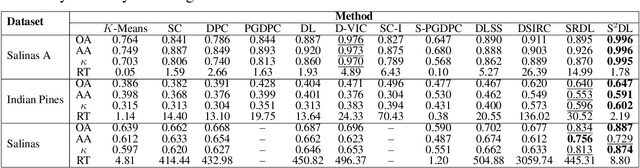

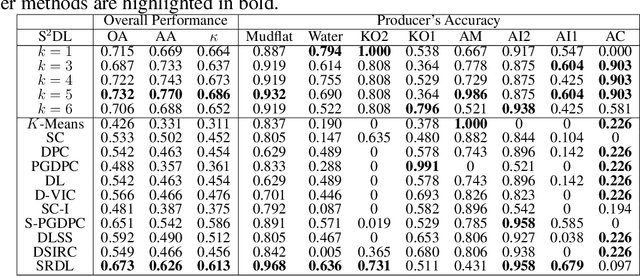
Hyperspectral images (HSIs) provide exceptional spatial and spectral resolution of a scene, crucial for various remote sensing applications. However, the high dimensionality, presence of noise and outliers, and the need for precise labels of HSIs present significant challenges to HSIs analysis, motivating the development of performant HSI clustering algorithms. This paper introduces a novel unsupervised HSI clustering algorithm, Superpixel-based and Spatially-regularized Diffusion Learning (S2DL), which addresses these challenges by incorporating rich spatial information encoded in HSIs into diffusion geometry-based clustering. S2DL employs the Entropy Rate Superpixel (ERS) segmentation technique to partition an image into superpixels, then constructs a spatially-regularized diffusion graph using the most representative high-density pixels. This approach reduces computational burden while preserving accuracy. Cluster modes, serving as exemplars for underlying cluster structure, are identified as the highest-density pixels farthest in diffusion distance from other highest-density pixels. These modes guide the labeling of the remaining representative pixels from ERS superpixels. Finally, majority voting is applied to the labels assigned within each superpixel to propagate labels to the rest of the image. This spatial-spectral approach simultaneously simplifies graph construction, reduces computational cost, and improves clustering performance. S2DL's performance is illustrated with extensive experiments on three publicly available, real-world HSIs: Indian Pines, Salinas, and Salinas A. Additionally, we apply S2DL to landscape-scale, unsupervised mangrove species mapping in the Mai Po Nature Reserve, Hong Kong, using a Gaofen-5 HSI. The success of S2DL in these diverse numerical experiments indicates its efficacy on a wide range of important unsupervised remote sensing analysis tasks.
AerialVLN: Vision-and-Language Navigation for UAVs
Aug 13, 2023



Recently emerged Vision-and-Language Navigation (VLN) tasks have drawn significant attention in both computer vision and natural language processing communities. Existing VLN tasks are built for agents that navigate on the ground, either indoors or outdoors. However, many tasks require intelligent agents to carry out in the sky, such as UAV-based goods delivery, traffic/security patrol, and scenery tour, to name a few. Navigating in the sky is more complicated than on the ground because agents need to consider the flying height and more complex spatial relationship reasoning. To fill this gap and facilitate research in this field, we propose a new task named AerialVLN, which is UAV-based and towards outdoor environments. We develop a 3D simulator rendered by near-realistic pictures of 25 city-level scenarios. Our simulator supports continuous navigation, environment extension and configuration. We also proposed an extended baseline model based on the widely-used cross-modal-alignment (CMA) navigation methods. We find that there is still a significant gap between the baseline model and human performance, which suggests AerialVLN is a new challenging task. Dataset and code is available at https://github.com/AirVLN/AirVLN.