 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsynchronous Training of Mixed-Role Human Actors in a Partially-Observable Environment
Dec 23, 2024In cooperative training, humans within a team coordinate on complex tasks, building mental models of their teammates and learning to adapt to teammates' actions in real-time. To reduce the often prohibitive scheduling constraints associated with cooperative training, this article introduces a paradigm for cooperative asynchronous training of human teams in which trainees practice coordination with autonomous teammates rather than humans. We introduce a novel experimental design for evaluating autonomous teammates for use as training partners in cooperative training. We apply the design to a human-subjects experiment where humans are trained with either another human or an autonomous teammate and are evaluated with a new human subject in a new, partially observable, cooperative game developed for this study. Importantly, we employ a method to cluster teammate trajectories from demonstrations performed in the experiment to form a smaller number of training conditions. This results in a simpler experiment design that enabled us to conduct a complex cooperative training human-subjects study in a reasonable amount of time. Through a demonstration of the proposed experimental design, we provide takeaways and design recommendations for future research in the development of cooperative asynchronous training systems utilizing robot surrogates for human teammates.
Superpixel-based and Spatially-regularized Diffusion Learning for Unsupervised Hyperspectral Image Clustering
Dec 24, 2023
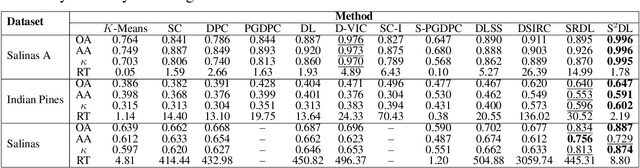

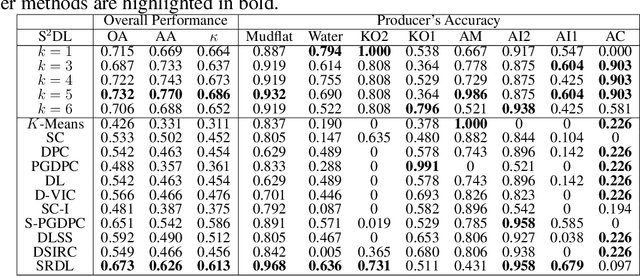
Hyperspectral images (HSIs) provide exceptional spatial and spectral resolution of a scene, crucial for various remote sensing applications. However, the high dimensionality, presence of noise and outliers, and the need for precise labels of HSIs present significant challenges to HSIs analysis, motivating the development of performant HSI clustering algorithms. This paper introduces a novel unsupervised HSI clustering algorithm, Superpixel-based and Spatially-regularized Diffusion Learning (S2DL), which addresses these challenges by incorporating rich spatial information encoded in HSIs into diffusion geometry-based clustering. S2DL employs the Entropy Rate Superpixel (ERS) segmentation technique to partition an image into superpixels, then constructs a spatially-regularized diffusion graph using the most representative high-density pixels. This approach reduces computational burden while preserving accuracy. Cluster modes, serving as exemplars for underlying cluster structure, are identified as the highest-density pixels farthest in diffusion distance from other highest-density pixels. These modes guide the labeling of the remaining representative pixels from ERS superpixels. Finally, majority voting is applied to the labels assigned within each superpixel to propagate labels to the rest of the image. This spatial-spectral approach simultaneously simplifies graph construction, reduces computational cost, and improves clustering performance. S2DL's performance is illustrated with extensive experiments on three publicly available, real-world HSIs: Indian Pines, Salinas, and Salinas A. Additionally, we apply S2DL to landscape-scale, unsupervised mangrove species mapping in the Mai Po Nature Reserve, Hong Kong, using a Gaofen-5 HSI. The success of S2DL in these diverse numerical experiments indicates its efficacy on a wide range of important unsupervised remote sensing analysis tasks.
Unsupervised Spatial-spectral Hyperspectral Image Reconstruction and Clustering with Diffusion Geometry
Apr 28, 2022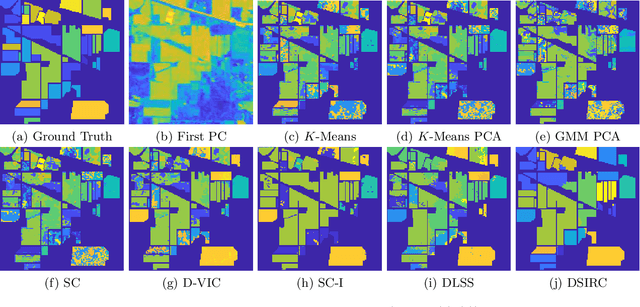

Hyperspectral images, which store a hundred or more spectral bands of reflectance, have become an important data source in natural and social sciences. Hyperspectral images are often generated in large quantities at a relatively coarse spatial resolution. As such, unsupervised machine learning algorithms incorporating known structure in hyperspectral imagery are needed to analyze these images automatically. This work introduces the Spatial-Spectral Image Reconstruction and Clustering with Diffusion Geometry (DSIRC) algorithm for partitioning highly mixed hyperspectral images. DSIRC reduces measurement noise through a shape-adaptive reconstruction procedure. In particular, for each pixel, DSIRC locates spectrally correlated pixels within a data-adaptive spatial neighborhood and reconstructs that pixel's spectral signature using those of its neighbors. DSIRC then locates high-density, high-purity pixels far in diffusion distance (a data-dependent distance metric) from other high-density, high-purity pixels and treats these as cluster exemplars, giving each a unique label. Non-modal pixels are assigned the label of their diffusion distance-nearest neighbor of higher density and purity that is already labeled. Strong numerical results indicate that incorporating spatial information through image reconstruction substantially improves the performance of pixel-wise clustering.
Unsupervised detection of ash dieback disease (Hymenoscyphus fraxineus) using diffusion-based hyperspectral image clustering
Apr 19, 2022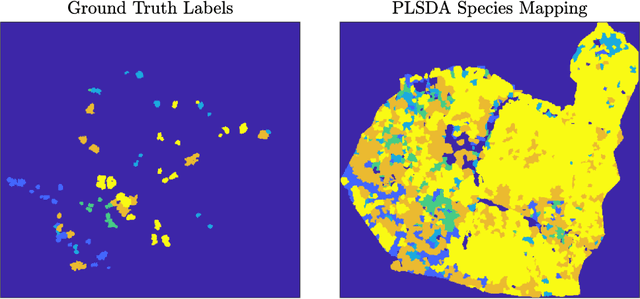

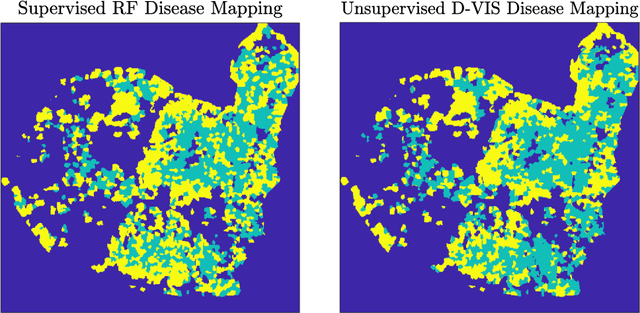
Ash dieback (Hymenoscyphus fraxineus) is an introduced fungal disease that is causing the widespread death of ash trees across Europe. Remote sensing hyperspectral images encode rich structure that has been exploited for the detection of dieback disease in ash trees using supervised machine learning techniques. However, to understand the state of forest health at landscape-scale, accurate unsupervised approaches are needed. This article investigates the use of the unsupervised Diffusion and VCA-Assisted Image Segmentation (D-VIS) clustering algorithm for the detection of ash dieback disease in a forest site near Cambridge, United Kingdom. The unsupervised clustering presented in this work has high overlap with the supervised classification of previous work on this scene (overall accuracy = 71%). Thus, unsupervised learning may be used for the remote detection of ash dieback disease without the need for expert labeling.
Active Diffusion and VCA-Assisted Image Segmentation of Hyperspectral Images
Apr 13, 2022
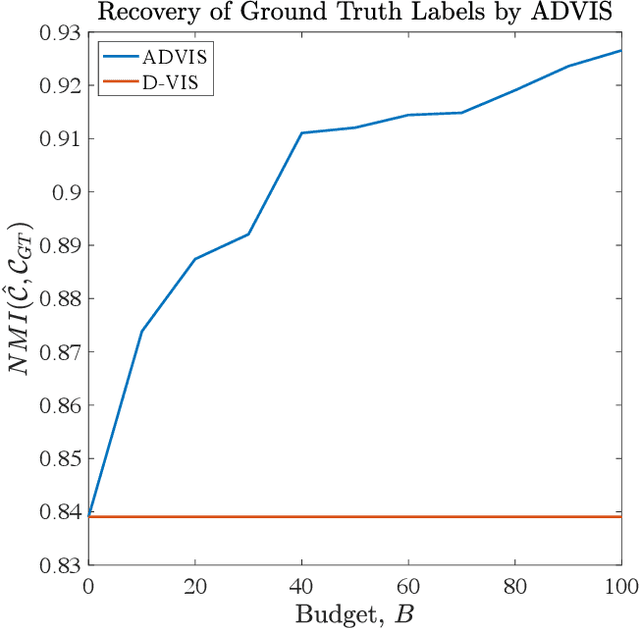
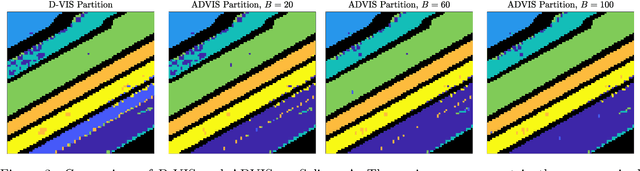
Hyperspectral images encode rich structure that can be exploited for material discrimination by machine learning algorithms. This article introduces the Active Diffusion and VCA-Assisted Image Segmentation (ADVIS) for active material discrimination. ADVIS selects high-purity, high-density pixels that are far in diffusion distance (a data-dependent metric) from other high-purity, high-density pixels in the hyperspectral image. The ground truth labels of these pixels are queried and propagated to the rest of the image. The ADVIS active learning algorithm is shown to strongly outperform its fully unsupervised clustering algorithm counterpart, suggesting that the incorporation of a very small number of carefully-selected ground truth labels can result in substantially superior material discrimination in hyperspectral images.
Diffusion and Volume Maximization-Based Clustering of Highly Mixed Hyperspectral Images
Mar 26, 2022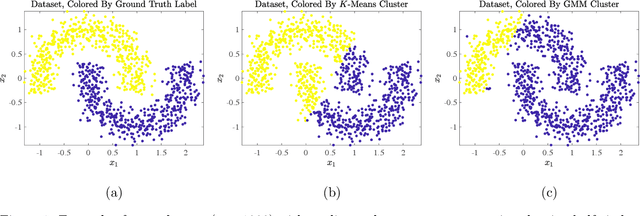
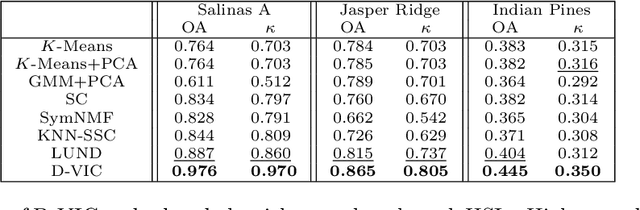
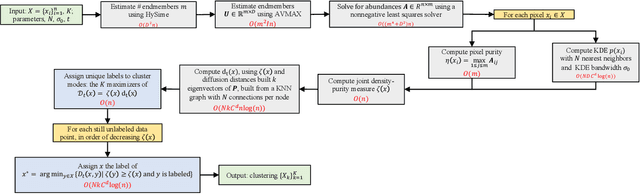
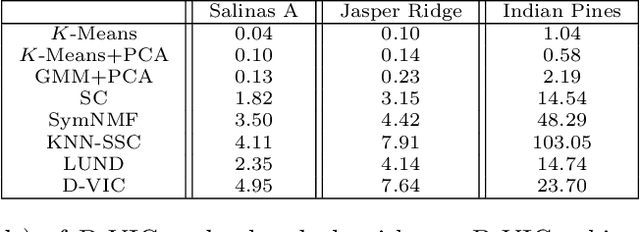
Hyperspectral images of a scene or object are a rich data source, often encoding a hundred or more spectral bands of reflectance at each pixel. Despite being very high-dimensional, these images typically encode latent low-dimensional structure that can be exploited for material discrimination. However, due to an inherent trade-off between spectral and spatial resolution, many hyperspectral images are generated at a coarse spatial scale, and single pixels may correspond to spatial regions containing multiple materials. This article introduces the Diffusion and Volume maximization-based Image Clustering (D-VIC) algorithm for unsupervised material discrimination. D-VIC locates cluster modes - high-density, high-purity pixels in the hyperspectral image that are far in diffusion distance (a data-dependent distance metric) from other high-density, high-purity pixels - and assigns these pixels unique labels, as these points are meant to exemplify underlying material structure. Non-modal pixels are labeled according to their diffusion distance nearest neighbor of higher density and purity that is already labeled. By directly incorporating pixel purity into its modal and non-modal labeling, D-VIC upweights pixels that correspond to a spatial region containing just a single material, yielding more interpretable clusterings. D-VIC is shown to outperform baseline and comparable state-of-the-art methods in extensive numerical experiments on a range of hyperspectral images, implying that it is well-equipped for material discrimination and clustering of these data.
Multiscale Clustering of Hyperspectral Images Through Spectral-Spatial Diffusion Geometry
Mar 29, 2021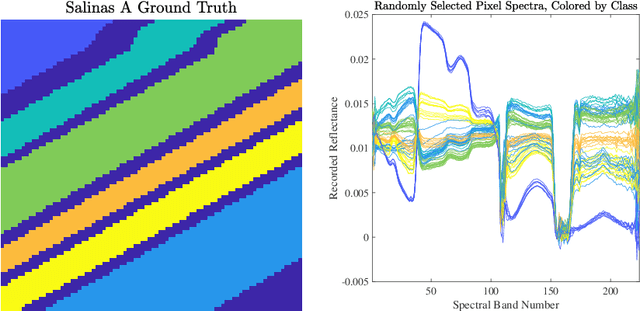
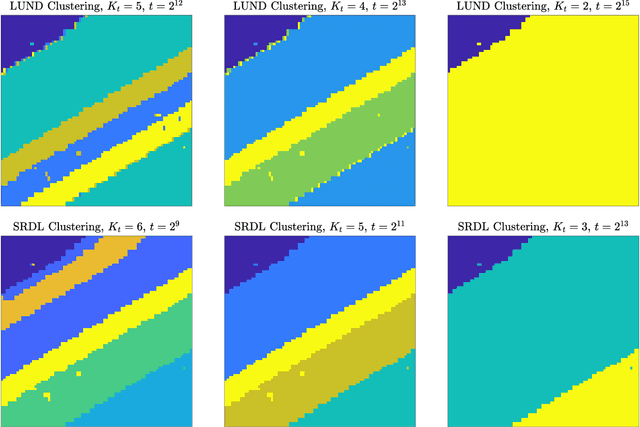
Clustering algorithms partition a dataset into groups of similar points. The primary contribution of this article is the Multiscale Spatially-Regularized Diffusion Learning (M-SRDL) clustering algorithm, which uses spatially-regularized diffusion distances to efficiently and accurately learn multiple scales of latent structure in hyperspectral images (HSI). The M-SRDL clustering algorithm extracts clusterings at many scales from an HSI and outputs these clusterings' variation of information-barycenter as an exemplar for all underlying cluster structure. We show that incorporating spatial regularization into a multiscale clustering framework corresponds to smoother and more coherent clusters when applied to HSI data and leads to more accurate clustering labels.
A Multiscale Environment for Learning by Diffusion
Jan 31, 2021
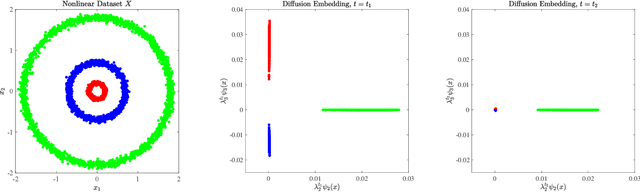
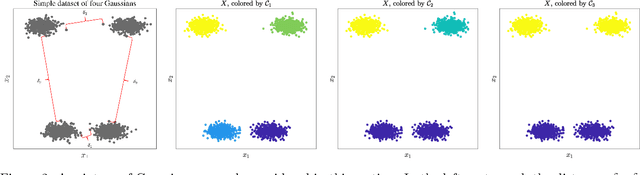

Clustering algorithms partition a dataset into groups of similar points. The clustering problem is very general, and different partitions of the same dataset could be considered correct and useful. To fully understand such data, it must be considered at a variety of scales, ranging from coarse to fine. We introduce the Multiscale Environment for Learning by Diffusion (MELD) data model, which is a family of clusterings parameterized by nonlinear diffusion on the dataset. We show that the MELD data model precisely captures latent multiscale structure in data and facilitates its analysis. To efficiently learn the multiscale structure observed in many real datasets, we introduce the Multiscale Learning by Unsupervised Nonlinear Diffusion (M-LUND) clustering algorithm, which is derived from a diffusion process at a range of temporal scales. We provide theoretical guarantees for the algorithm's performance and establish its computational efficiency. Finally, we show that the M-LUND clustering algorithm detects the latent structure in a range of synthetic and real datasets.