 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsynchronous Training of Mixed-Role Human Actors in a Partially-Observable Environment
Dec 23, 2024In cooperative training, humans within a team coordinate on complex tasks, building mental models of their teammates and learning to adapt to teammates' actions in real-time. To reduce the often prohibitive scheduling constraints associated with cooperative training, this article introduces a paradigm for cooperative asynchronous training of human teams in which trainees practice coordination with autonomous teammates rather than humans. We introduce a novel experimental design for evaluating autonomous teammates for use as training partners in cooperative training. We apply the design to a human-subjects experiment where humans are trained with either another human or an autonomous teammate and are evaluated with a new human subject in a new, partially observable, cooperative game developed for this study. Importantly, we employ a method to cluster teammate trajectories from demonstrations performed in the experiment to form a smaller number of training conditions. This results in a simpler experiment design that enabled us to conduct a complex cooperative training human-subjects study in a reasonable amount of time. Through a demonstration of the proposed experimental design, we provide takeaways and design recommendations for future research in the development of cooperative asynchronous training systems utilizing robot surrogates for human teammates.
Designs for Enabling Collaboration in Human-Machine Teaming via Interactive and Explainable Systems
Jun 07, 2024Collaborative robots and machine learning-based virtual agents are increasingly entering the human workspace with the aim of increasing productivity and enhancing safety. Despite this, we show in a ubiquitous experimental domain, Overcooked-AI, that state-of-the-art techniques for human-machine teaming (HMT), which rely on imitation or reinforcement learning, are brittle and result in a machine agent that aims to decouple the machine and human's actions to act independently rather than in a synergistic fashion. To remedy this deficiency, we develop HMT approaches that enable iterative, mixed-initiative team development allowing end-users to interactively reprogram interpretable AI teammates. Our 50-subject study provides several findings that we summarize into guidelines. While all approaches underperform a simple collaborative heuristic (a critical, negative result for learning-based methods), we find that white-box approaches supported by interactive modification can lead to significant team development, outperforming white-box approaches alone, and black-box approaches are easier to train and result in better HMT performance highlighting a tradeoff between explainability and interactivity versus ease-of-training. Together, these findings present three important directions: 1) Improving the ability to generate collaborative agents with white-box models, 2) Better learning methods to facilitate collaboration rather than individualized coordination, and 3) Mixed-initiative interfaces that enable users, who may vary in ability, to improve collaboration.
The Utility of Explainable AI in Ad Hoc Human-Machine Teaming
Sep 08, 2022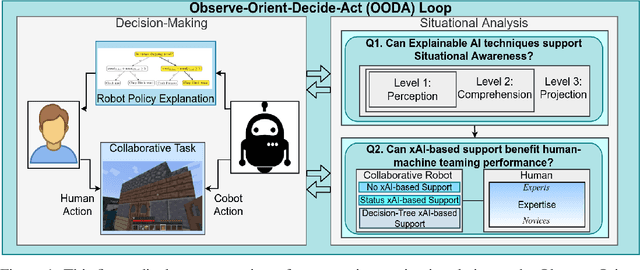
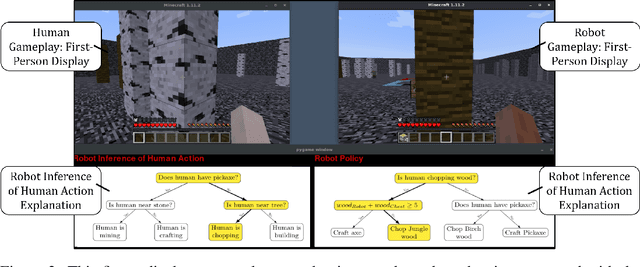
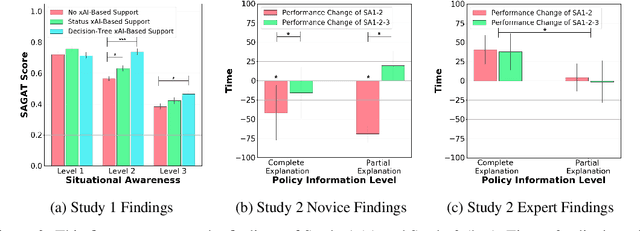
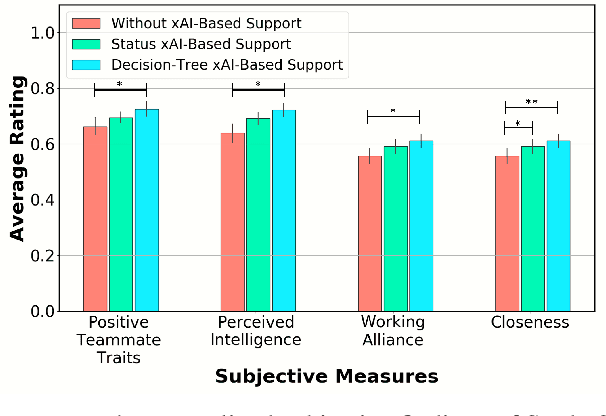
Recent advances in machine learning have led to growing interest in Explainable AI (xAI) to enable humans to gain insight into the decision-making of machine learning models. Despite this recent interest, the utility of xAI techniques has not yet been characterized in human-machine teaming. Importantly, xAI offers the promise of enhancing team situational awareness (SA) and shared mental model development, which are the key characteristics of effective human-machine teams. Rapidly developing such mental models is especially critical in ad hoc human-machine teaming, where agents do not have a priori knowledge of others' decision-making strategies. In this paper, we present two novel human-subject experiments quantifying the benefits of deploying xAI techniques within a human-machine teaming scenario. First, we show that xAI techniques can support SA ($p<0.05)$. Second, we examine how different SA levels induced via a collaborative AI policy abstraction affect ad hoc human-machine teaming performance. Importantly, we find that the benefits of xAI are not universal, as there is a strong dependence on the composition of the human-machine team. Novices benefit from xAI providing increased SA ($p<0.05$) but are susceptible to cognitive overhead ($p<0.05$). On the other hand, expert performance degrades with the addition of xAI-based support ($p<0.05$), indicating that the cost of paying attention to the xAI outweighs the benefits obtained from being provided additional information to enhance SA. Our results demonstrate that researchers must deliberately design and deploy the right xAI techniques in the right scenario by carefully considering human-machine team composition and how the xAI method augments SA.
Human-Machine Collaborative Optimization via Apprenticeship Scheduling
May 11, 2018
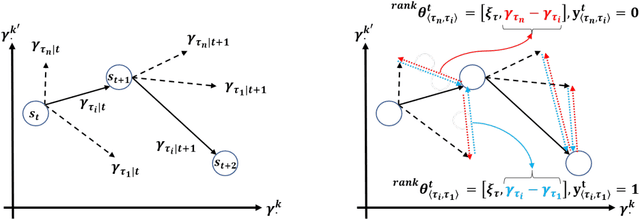

Coordinating agents to complete a set of tasks with intercoupled temporal and resource constraints is computationally challenging, yet human domain experts can solve these difficult scheduling problems using paradigms learned through years of apprenticeship. A process for manually codifying this domain knowledge within a computational framework is necessary to scale beyond the ``single-expert, single-trainee" apprenticeship model. However, human domain experts often have difficulty describing their decision-making processes, causing the codification of this knowledge to become laborious. We propose a new approach for capturing domain-expert heuristics through a pairwise ranking formulation. Our approach is model-free and does not require enumerating or iterating through a large state space. We empirically demonstrate that this approach accurately learns multifaceted heuristics on a synthetic data set incorporating job-shop scheduling and vehicle routing problems, as well as on two real-world data sets consisting of demonstrations of experts solving a weapon-to-target assignment problem and a hospital resource allocation problem. We also demonstrate that policies learned from human scheduling demonstration via apprenticeship learning can substantially improve the efficiency of a branch-and-bound search for an optimal schedule. We employ this human-machine collaborative optimization technique on a variant of the weapon-to-target assignment problem. We demonstrate that this technique generates solutions substantially superior to those produced by human domain experts at a rate up to 9.5 times faster than an optimization approach and can be applied to optimally solve problems twice as complex as those solved by a human demonstrator.