 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Utility of Explainable AI in Ad Hoc Human-Machine Teaming
Sep 08, 2022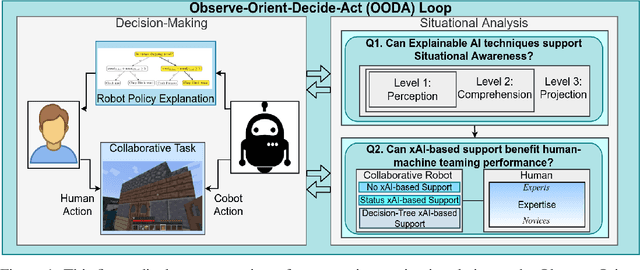
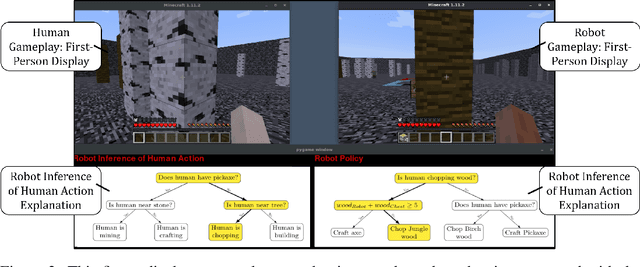
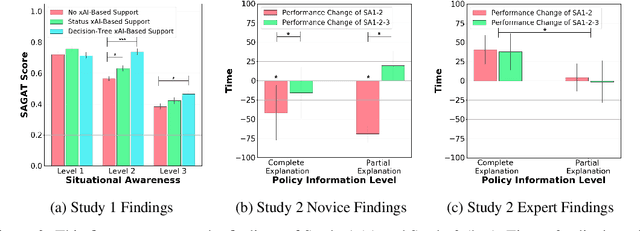
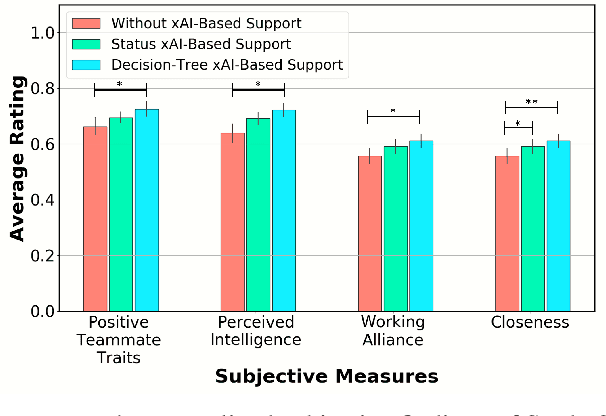
Recent advances in machine learning have led to growing interest in Explainable AI (xAI) to enable humans to gain insight into the decision-making of machine learning models. Despite this recent interest, the utility of xAI techniques has not yet been characterized in human-machine teaming. Importantly, xAI offers the promise of enhancing team situational awareness (SA) and shared mental model development, which are the key characteristics of effective human-machine teams. Rapidly developing such mental models is especially critical in ad hoc human-machine teaming, where agents do not have a priori knowledge of others' decision-making strategies. In this paper, we present two novel human-subject experiments quantifying the benefits of deploying xAI techniques within a human-machine teaming scenario. First, we show that xAI techniques can support SA ($p<0.05)$. Second, we examine how different SA levels induced via a collaborative AI policy abstraction affect ad hoc human-machine teaming performance. Importantly, we find that the benefits of xAI are not universal, as there is a strong dependence on the composition of the human-machine team. Novices benefit from xAI providing increased SA ($p<0.05$) but are susceptible to cognitive overhead ($p<0.05$). On the other hand, expert performance degrades with the addition of xAI-based support ($p<0.05$), indicating that the cost of paying attention to the xAI outweighs the benefits obtained from being provided additional information to enhance SA. Our results demonstrate that researchers must deliberately design and deploy the right xAI techniques in the right scenario by carefully considering human-machine team composition and how the xAI method augments SA.
Four Years in Review: Statistical Practices of Likert Scales in Human-Robot Interaction Studies
Jan 31, 2020


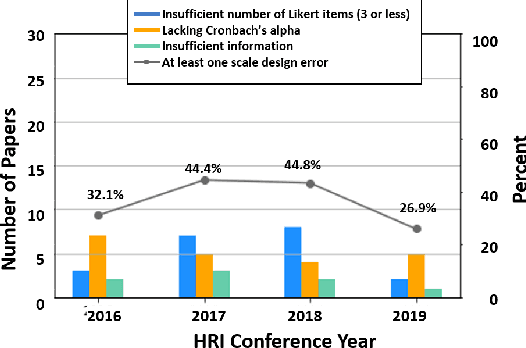
As robots become more prevalent, the importance of the field of human-robot interaction (HRI) grows accordingly. As such, we should endeavor to employ the best statistical practices. Likert scales are commonly used metrics in HRI to measure perceptions and attitudes. Due to misinformation or honest mistakes, most HRI researchers do not adopt best practices when analyzing Likert data. We conduct a review of psychometric literature to determine the current standard for Likert scale design and analysis. Next, we conduct a survey of four years of the International Conference on Human-Robot Interaction (2016 through 2019) and report on incorrect statistical practices and design of Likert scales. During these years, only 3 of the 110 papers applied proper statistical testing to correctly-designed Likert scales. Our analysis suggests there are areas for meaningful improvement in the design and testing of Likert scales. Lastly, we provide recommendations to improve the accuracy of conclusions drawn from Likert data.
Joint Goal and Strategy Inference across Heterogeneous Demonstrators via Reward Network Distillation
Jan 03, 2020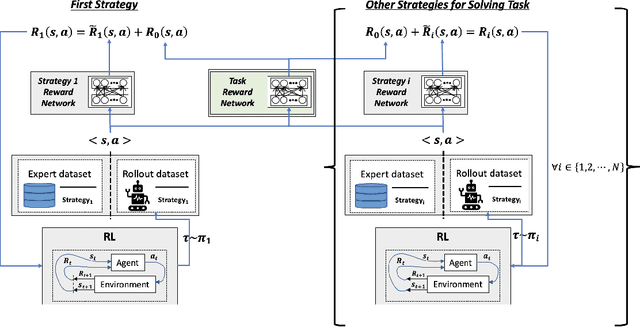
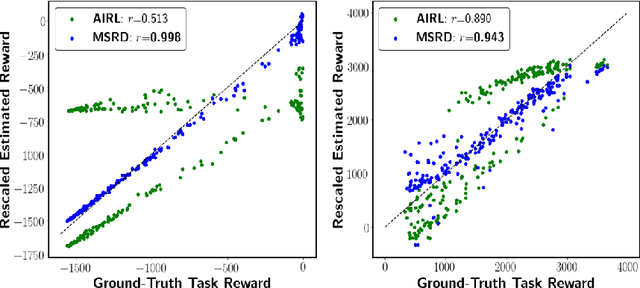
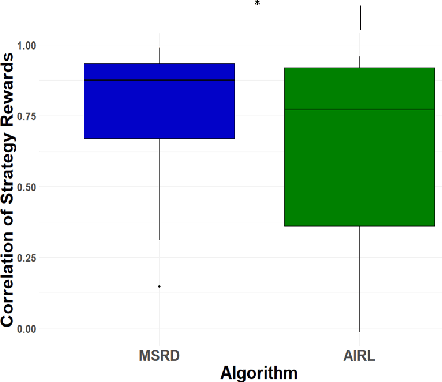
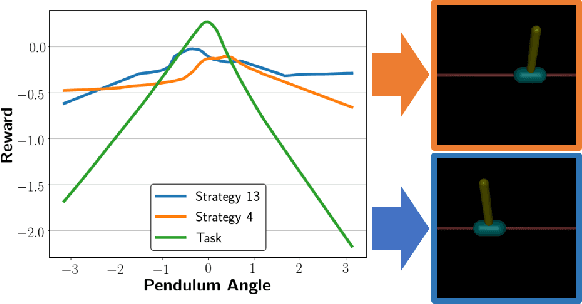
Reinforcement learning (RL) has achieved tremendous success as a general framework for learning how to make decisions. However, this success relies on the interactive hand-tuning of a reward function by RL experts. On the other hand, inverse reinforcement learning (IRL) seeks to learn a reward function from readily-obtained human demonstrations. Yet, IRL suffers from two major limitations: 1) reward ambiguity - there are an infinite number of possible reward functions that could explain an expert's demonstration and 2) heterogeneity - human experts adopt varying strategies and preferences, which makes learning from multiple demonstrators difficult due to the common assumption that demonstrators seeks to maximize the same reward. In this work, we propose a method to jointly infer a task goal and humans' strategic preferences via network distillation. This approach enables us to distill a robust task reward (addressing reward ambiguity) and to model each strategy's objective (handling heterogeneity). We demonstrate our algorithm can better recover task reward and strategy rewards and imitate the strategies in two simulated tasks and a real-world table tennis task.