 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUse of Winsome Robots for Understanding Human Feedback (UWU)
Feb 07, 2025As social robots become more common, many have adopted cute aesthetics aiming to enhance user comfort and acceptance. However, the effect of this aesthetic choice on human feedback in reinforcement learning scenarios remains unclear. Previous research has shown that humans tend to give more positive than negative feedback, which can cause failure to reach optimal robot behavior. We hypothesize that this positive bias may be exacerbated by the robot's level of perceived cuteness. To investigate, we conducted a user study where participants critique a robot's trajectories while it performs a task. We then analyzed the impact of the robot's aesthetic cuteness on the type of participant feedback. Our results suggest that there is a shift in the ratio of positive to negative feedback when perceived cuteness changes. In light of this, we experiment with a stochastic version of TAMER which adapts based on the user's level of positive feedback bias to mitigate these effects.
Diffusion-Reinforcement Learning Hierarchical Motion Planning in Adversarial Multi-agent Games
Mar 16, 2024



Reinforcement Learning- (RL-)based motion planning has recently shown the potential to outperform traditional approaches from autonomous navigation to robot manipulation. In this work, we focus on a motion planning task for an evasive target in a partially observable multi-agent adversarial pursuit-evasion games (PEG). These pursuit-evasion problems are relevant to various applications, such as search and rescue operations and surveillance robots, where robots must effectively plan their actions to gather intelligence or accomplish mission tasks while avoiding detection or capture themselves. We propose a hierarchical architecture that integrates a high-level diffusion model to plan global paths responsive to environment data while a low-level RL algorithm reasons about evasive versus global path-following behavior. Our approach outperforms baselines by 51.2% by leveraging the diffusion model to guide the RL algorithm for more efficient exploration and improves the explanability and predictability.
Learning Models of Adversarial Agent Behavior under Partial Observability
Jul 05, 2023The need for opponent modeling and tracking arises in several real-world scenarios, such as professional sports, video game design, and drug-trafficking interdiction. In this work, we present Graph based Adversarial Modeling with Mutal Information (GrAMMI) for modeling the behavior of an adversarial opponent agent. GrAMMI is a novel graph neural network (GNN) based approach that uses mutual information maximization as an auxiliary objective to predict the current and future states of an adversarial opponent with partial observability. To evaluate GrAMMI, we design two large-scale, pursuit-evasion domains inspired by real-world scenarios, where a team of heterogeneous agents is tasked with tracking and interdicting a single adversarial agent, and the adversarial agent must evade detection while achieving its own objectives. With the mutual information formulation, GrAMMI outperforms all baselines in both domains and achieves 31.68% higher log-likelihood on average for future adversarial state predictions across both domains.
Adversarial Search and Track with Multiagent Reinforcement Learning in Sparsely Observable Environment
Jun 20, 2023We study a search and tracking (S&T) problem for a team of dynamic search agents to capture an adversarial evasive agent with only sparse temporal and spatial knowledge of its location in this paper. The domain is challenging for traditional Reinforcement Learning (RL) approaches as the large space leads to sparse observations of the adversary and in turn sparse rewards for the search agents. Additionally, the opponent's behavior is reactionary to the search agents, which causes a data distribution shift for RL during training as search agents improve their policies. We propose a differentiable Multi-Agent RL (MARL) architecture that utilizes a novel filtering module to supplement estimated adversary location information and enables the effective learning of a team policy. Our algorithm learns how to balance information from prior knowledge and a motion model to remain resilient to the data distribution shift and outperforms all baseline methods with a 46% increase of detection rate.
MAVERIC: A Data-Driven Approach to Personalized Autonomous Driving
Jan 20, 2023
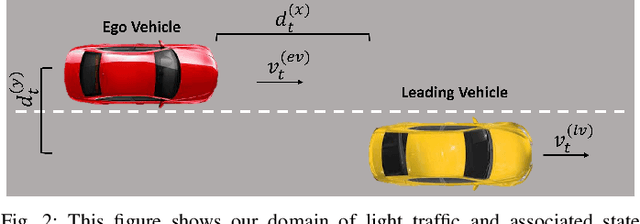
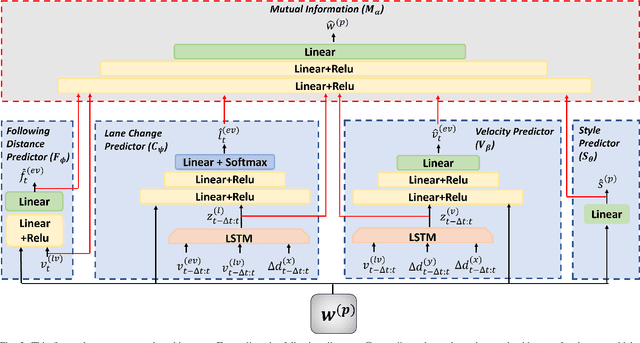
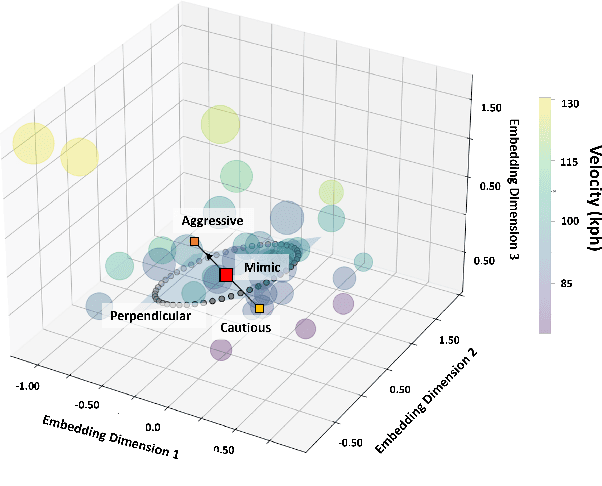
Personalization of autonomous vehicles (AV) may significantly increase trust, use, and acceptance. In particular, we hypothesize that the similarity of an AV's driving style compared to the end-user's driving style will have a major impact on end-user's willingness to use the AV. To investigate the impact of driving style on user acceptance, we 1) develop a data-driven approach to personalize driving style and 2) demonstrate that personalization significantly impacts attitudes towards AVs. Our approach learns a high-level model that tunes low-level controllers to ensure safe and personalized control of the AV. The key to our approach is learning an informative, personalized embedding that represents a user's driving style. Our framework is capable of calibrating the level of aggression so as to optimize driving style based upon driver preference. Across two human subject studies (n = 54), we first demonstrate our approach mimics the driving styles of end-users and can tune attributes of style (e.g., aggressiveness). Second, we investigate the factors (e.g., trust, personality etc.) that impact homophily, i.e. an individual's preference for a driving style similar to their own. We find that our approach generates driving styles consistent with end-user styles (p<.001) and participants rate our approach as more similar to their level of aggressiveness (p=.002). We find that personality (p<.001), perceived similarity (p<.001), and high-velocity driving style (p=.0031) significantly modulate the effect of homophily.
Improving Robot-Centric Learning from Demonstration via Personalized Embeddings
Oct 07, 2021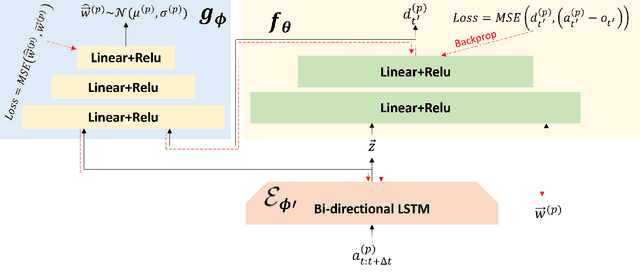
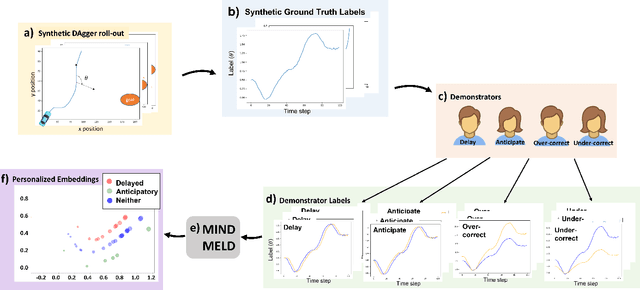

Learning from demonstration (LfD) techniques seek to enable novice users to teach robots novel tasks in the real world. However, prior work has shown that robot-centric LfD approaches, such as Dataset Aggregation (DAgger), do not perform well with human teachers. DAgger requires a human demonstrator to provide corrective feedback to the learner either in real-time, which can result in degraded performance due to suboptimal human labels, or in a post hoc manner which is time intensive and often not feasible. To address this problem, we present Mutual Information-driven Meta-learning from Demonstration (MIND MELD), which meta-learns a mapping from poor quality human labels to predicted ground truth labels, thereby improving upon the performance of prior LfD approaches for DAgger-based training. The key to our approach for improving upon suboptimal feedback is mutual information maximization via variational inference. Our approach learns a meaningful, personalized embedding via variational inference which informs the mapping from human provided labels to predicted ground truth labels. We demonstrate our framework in a synthetic domain and in a human-subjects experiment, illustrating that our approach improves upon the corrective labels provided by a human demonstrator by 63%.
Meta-active Learning in Probabilistically-Safe Optimization
Jul 07, 2020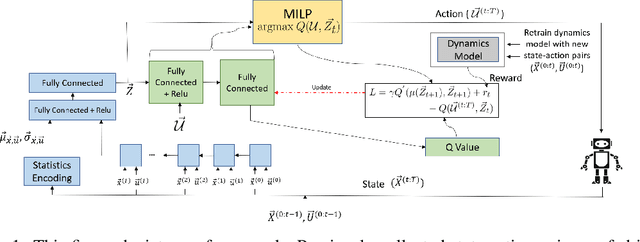


Learning to control a safety-critical system with latent dynamics (e.g. for deep brain stimulation) requires taking calculated risks to gain information as efficiently as possible. To address this problem, we present a probabilistically-safe, meta-active learning approach to efficiently learn system dynamics and optimal configurations. We cast this problem as meta-learning an acquisition function, which is represented by a Long-Short Term Memory Network (LSTM) encoding sampling history. This acquisition function is meta-learned offline to learn high quality sampling strategies. We employ a mixed-integer linear program as our policy with the final, linearized layers of our LSTM acquisition function directly encoded into the objective to trade off expected information gain (e.g., improvement in the accuracy of the model of system dynamics) with the likelihood of safe control. We set a new state-of-the-art in active learning for control of a high-dimensional system with altered dynamics (i.e., a damaged aircraft), achieving a 46% increase in information gain and a 20% speedup in computation time over baselines. Furthermore, we demonstrate our system's ability to learn the optimal parameter settings for deep brain stimulation in a rat's brain while avoiding unwanted side effects (i.e., triggering seizures), outperforming prior state-of-the-art approaches with a 58% increase in information gain. Additionally, our algorithm achieves a 97% likelihood of terminating in a safe state while losing only 15% of information gain.
Four Years in Review: Statistical Practices of Likert Scales in Human-Robot Interaction Studies
Jan 31, 2020


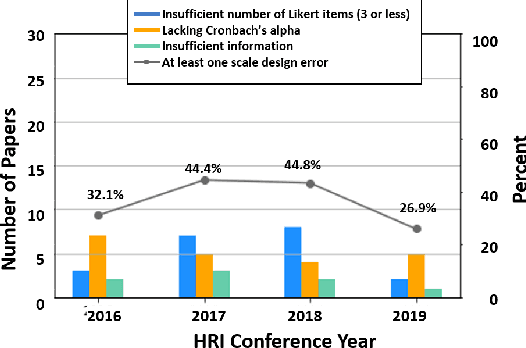
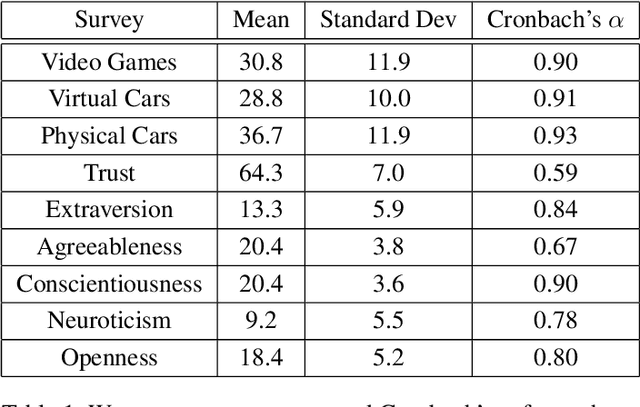
As robots become more prevalent, the importance of the field of human-robot interaction (HRI) grows accordingly. As such, we should endeavor to employ the best statistical practices. Likert scales are commonly used metrics in HRI to measure perceptions and attitudes. Due to misinformation or honest mistakes, most HRI researchers do not adopt best practices when analyzing Likert data. We conduct a review of psychometric literature to determine the current standard for Likert scale design and analysis. Next, we conduct a survey of four years of the International Conference on Human-Robot Interaction (2016 through 2019) and report on incorrect statistical practices and design of Likert scales. During these years, only 3 of the 110 papers applied proper statistical testing to correctly-designed Likert scales. Our analysis suggests there are areas for meaningful improvement in the design and testing of Likert scales. Lastly, we provide recommendations to improve the accuracy of conclusions drawn from Likert data.