 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixed-Initiative Human-Robot Teaming under Suboptimality with Online Bayesian Adaptation
Mar 24, 2024For effective human-agent teaming, robots and other artificial intelligence (AI) agents must infer their human partner's abilities and behavioral response patterns and adapt accordingly. Most prior works make the unrealistic assumption that one or more teammates can act near-optimally. In real-world collaboration, humans and autonomous agents can be suboptimal, especially when each only has partial domain knowledge. In this work, we develop computational modeling and optimization techniques for enhancing the performance of suboptimal human-agent teams, where the human and the agent have asymmetric capabilities and act suboptimally due to incomplete environmental knowledge. We adopt an online Bayesian approach that enables a robot to infer people's willingness to comply with its assistance in a sequential decision-making game. Our user studies show that user preferences and team performance indeed vary with robot intervention styles, and our approach for mixed-initiative collaborations enhances objective team performance ($p<.001$) and subjective measures, such as user's trust ($p<.001$) and perceived likeability of the robot ($p<.001$).
Diffusion-Reinforcement Learning Hierarchical Motion Planning in Adversarial Multi-agent Games
Mar 16, 2024



Reinforcement Learning- (RL-)based motion planning has recently shown the potential to outperform traditional approaches from autonomous navigation to robot manipulation. In this work, we focus on a motion planning task for an evasive target in a partially observable multi-agent adversarial pursuit-evasion games (PEG). These pursuit-evasion problems are relevant to various applications, such as search and rescue operations and surveillance robots, where robots must effectively plan their actions to gather intelligence or accomplish mission tasks while avoiding detection or capture themselves. We propose a hierarchical architecture that integrates a high-level diffusion model to plan global paths responsive to environment data while a low-level RL algorithm reasons about evasive versus global path-following behavior. Our approach outperforms baselines by 51.2% by leveraging the diffusion model to guide the RL algorithm for more efficient exploration and improves the explanability and predictability.
Diffusion Based Multi-Agent Adversarial Tracking
Jul 12, 2023



Target tracking plays a crucial role in real-world scenarios, particularly in drug-trafficking interdiction, where the knowledge of an adversarial target's location is often limited. Improving autonomous tracking systems will enable unmanned aerial, surface, and underwater vehicles to better assist in interdicting smugglers that use manned surface, semi-submersible, and aerial vessels. As unmanned drones proliferate, accurate autonomous target estimation is even more crucial for security and safety. This paper presents Constrained Agent-based Diffusion for Enhanced Multi-Agent Tracking (CADENCE), an approach aimed at generating comprehensive predictions of adversary locations by leveraging past sparse state information. To assess the effectiveness of this approach, we evaluate predictions on single-target and multi-target pursuit environments, employing Monte-Carlo sampling of the diffusion model to estimate the probability associated with each generated trajectory. We propose a novel cross-attention based diffusion model that utilizes constraint-based sampling to generate multimodal track hypotheses. Our single-target model surpasses the performance of all baseline methods on Average Displacement Error (ADE) for predictions across all time horizons.
Learning Models of Adversarial Agent Behavior under Partial Observability
Jul 05, 2023The need for opponent modeling and tracking arises in several real-world scenarios, such as professional sports, video game design, and drug-trafficking interdiction. In this work, we present Graph based Adversarial Modeling with Mutal Information (GrAMMI) for modeling the behavior of an adversarial opponent agent. GrAMMI is a novel graph neural network (GNN) based approach that uses mutual information maximization as an auxiliary objective to predict the current and future states of an adversarial opponent with partial observability. To evaluate GrAMMI, we design two large-scale, pursuit-evasion domains inspired by real-world scenarios, where a team of heterogeneous agents is tasked with tracking and interdicting a single adversarial agent, and the adversarial agent must evade detection while achieving its own objectives. With the mutual information formulation, GrAMMI outperforms all baselines in both domains and achieves 31.68% higher log-likelihood on average for future adversarial state predictions across both domains.
Adversarial Search and Track with Multiagent Reinforcement Learning in Sparsely Observable Environment
Jun 20, 2023We study a search and tracking (S&T) problem for a team of dynamic search agents to capture an adversarial evasive agent with only sparse temporal and spatial knowledge of its location in this paper. The domain is challenging for traditional Reinforcement Learning (RL) approaches as the large space leads to sparse observations of the adversary and in turn sparse rewards for the search agents. Additionally, the opponent's behavior is reactionary to the search agents, which causes a data distribution shift for RL during training as search agents improve their policies. We propose a differentiable Multi-Agent RL (MARL) architecture that utilizes a novel filtering module to supplement estimated adversary location information and enables the effective learning of a team policy. Our algorithm learns how to balance information from prior knowledge and a motion model to remain resilient to the data distribution shift and outperforms all baseline methods with a 46% increase of detection rate.
Human-Robot Team Coordination with Dynamic and Latent Human Task Proficiencies: Scheduling with Learning Curves
Jul 09, 2020
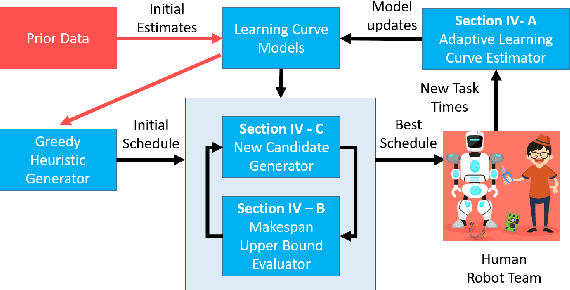


As robots become ubiquitous in the workforce, it is essential that human-robot collaboration be both intuitive and adaptive. A robot's quality improves based on its ability to explicitly reason about the time-varying (i.e. learning curves) and stochastic capabilities of its human counterparts, and adjust the joint workload to improve efficiency while factoring human preferences. We introduce a novel resource coordination algorithm that enables robots to explore the relative strengths and learning abilities of their human teammates, by constructing schedules that are robust to stochastic and time-varying human task performance. We first validate our algorithmic approach using data we collected from a user study (n = 20), showing we can quickly generate and evaluate a robust schedule while discovering the latest individual worker proficiency. Second, we conduct a between-subjects experiment (n = 90) to validate the efficacy of our coordinating algorithm. Results from the human-subjects experiment indicate that scheduling strategies favoring exploration tend to be beneficial for human-robot collaboration as it improves team fluency (p = 0.0438), while also maximizing team efficiency (p < 0.001).