 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoS: Enhancing Personalization and Mitigating Bias with Context Steering
May 02, 2024



When querying a large language model (LLM), the context, i.e. personal, demographic, and cultural information specific to an end-user, can significantly shape the response of the LLM. For example, asking the model to explain Newton's second law with the context "I am a toddler" yields a different answer compared to the context "I am a physics professor." Proper usage of the context enables the LLM to generate personalized responses, whereas inappropriate contextual influence can lead to stereotypical and potentially harmful generations (e.g. associating "female" with "housekeeper"). In practice, striking the right balance when leveraging context is a nuanced and challenging problem that is often situation-dependent. One common approach to address this challenge is to fine-tune LLMs on contextually appropriate responses. However, this approach is expensive, time-consuming, and not controllable for end-users in different situations. In this work, we propose Context Steering (CoS) - a simple training-free method that can be easily applied to autoregressive LLMs at inference time. By measuring the contextual influence in terms of token prediction likelihood and modulating it, our method enables practitioners to determine the appropriate level of contextual influence based on their specific use case and end-user base. We showcase a variety of applications of CoS including amplifying the contextual influence to achieve better personalization and mitigating unwanted influence for reducing model bias. In addition, we show that we can combine CoS with Bayesian Inference to quantify the extent of hate speech on the internet. We demonstrate the effectiveness of CoS on state-of-the-art LLMs and benchmarks.
MAVERIC: A Data-Driven Approach to Personalized Autonomous Driving
Jan 20, 2023
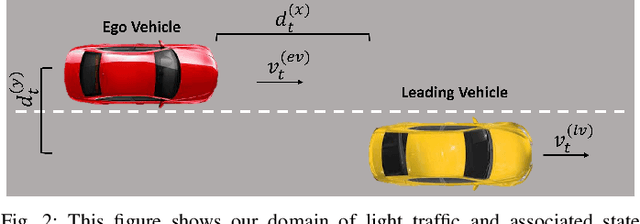
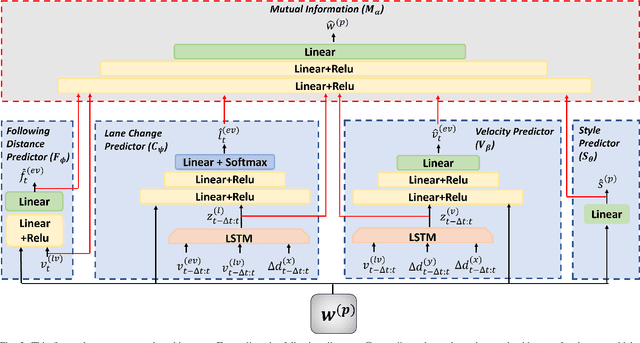
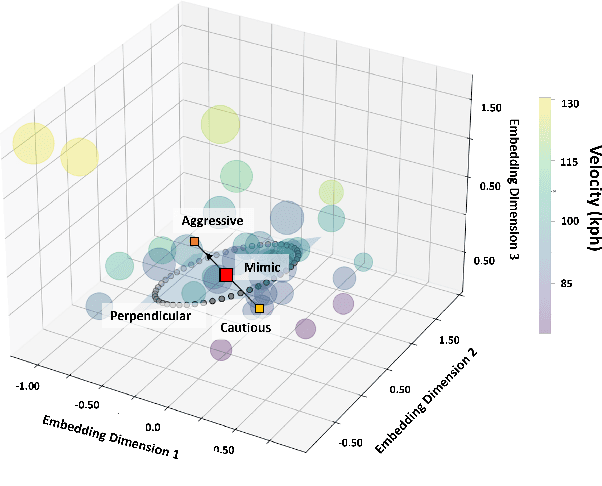
Personalization of autonomous vehicles (AV) may significantly increase trust, use, and acceptance. In particular, we hypothesize that the similarity of an AV's driving style compared to the end-user's driving style will have a major impact on end-user's willingness to use the AV. To investigate the impact of driving style on user acceptance, we 1) develop a data-driven approach to personalize driving style and 2) demonstrate that personalization significantly impacts attitudes towards AVs. Our approach learns a high-level model that tunes low-level controllers to ensure safe and personalized control of the AV. The key to our approach is learning an informative, personalized embedding that represents a user's driving style. Our framework is capable of calibrating the level of aggression so as to optimize driving style based upon driver preference. Across two human subject studies (n = 54), we first demonstrate our approach mimics the driving styles of end-users and can tune attributes of style (e.g., aggressiveness). Second, we investigate the factors (e.g., trust, personality etc.) that impact homophily, i.e. an individual's preference for a driving style similar to their own. We find that our approach generates driving styles consistent with end-user styles (p<.001) and participants rate our approach as more similar to their level of aggressiveness (p=.002). We find that personality (p<.001), perceived similarity (p<.001), and high-velocity driving style (p=.0031) significantly modulate the effect of homophily.
Improving Robot-Centric Learning from Demonstration via Personalized Embeddings
Oct 07, 2021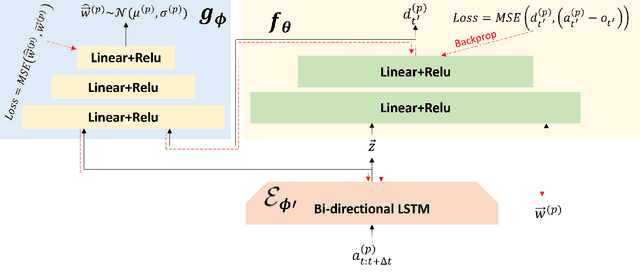
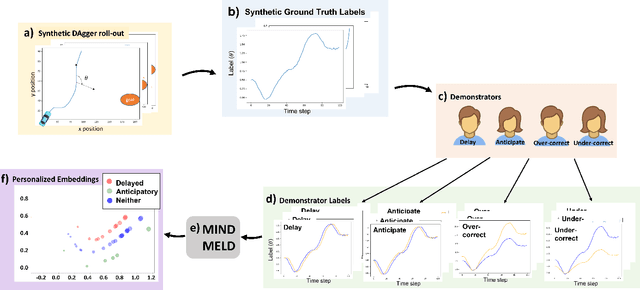

Learning from demonstration (LfD) techniques seek to enable novice users to teach robots novel tasks in the real world. However, prior work has shown that robot-centric LfD approaches, such as Dataset Aggregation (DAgger), do not perform well with human teachers. DAgger requires a human demonstrator to provide corrective feedback to the learner either in real-time, which can result in degraded performance due to suboptimal human labels, or in a post hoc manner which is time intensive and often not feasible. To address this problem, we present Mutual Information-driven Meta-learning from Demonstration (MIND MELD), which meta-learns a mapping from poor quality human labels to predicted ground truth labels, thereby improving upon the performance of prior LfD approaches for DAgger-based training. The key to our approach for improving upon suboptimal feedback is mutual information maximization via variational inference. Our approach learns a meaningful, personalized embedding via variational inference which informs the mapping from human provided labels to predicted ground truth labels. We demonstrate our framework in a synthetic domain and in a human-subjects experiment, illustrating that our approach improves upon the corrective labels provided by a human demonstrator by 63%.
Meta-active Learning in Probabilistically-Safe Optimization
Jul 07, 2020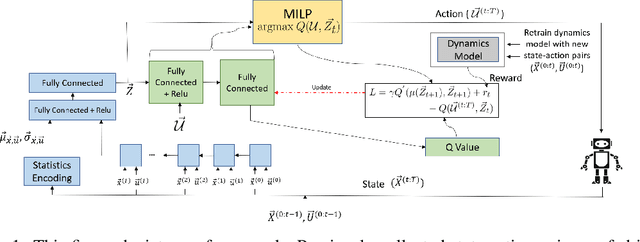
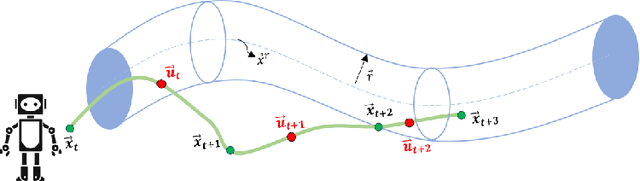


Learning to control a safety-critical system with latent dynamics (e.g. for deep brain stimulation) requires taking calculated risks to gain information as efficiently as possible. To address this problem, we present a probabilistically-safe, meta-active learning approach to efficiently learn system dynamics and optimal configurations. We cast this problem as meta-learning an acquisition function, which is represented by a Long-Short Term Memory Network (LSTM) encoding sampling history. This acquisition function is meta-learned offline to learn high quality sampling strategies. We employ a mixed-integer linear program as our policy with the final, linearized layers of our LSTM acquisition function directly encoded into the objective to trade off expected information gain (e.g., improvement in the accuracy of the model of system dynamics) with the likelihood of safe control. We set a new state-of-the-art in active learning for control of a high-dimensional system with altered dynamics (i.e., a damaged aircraft), achieving a 46% increase in information gain and a 20% speedup in computation time over baselines. Furthermore, we demonstrate our system's ability to learn the optimal parameter settings for deep brain stimulation in a rat's brain while avoiding unwanted side effects (i.e., triggering seizures), outperforming prior state-of-the-art approaches with a 58% increase in information gain. Additionally, our algorithm achieves a 97% likelihood of terminating in a safe state while losing only 15% of information gain.
A Mosquito Pick-and-Place System for PfSPZ-based Malaria Vaccine Production
Apr 12, 2020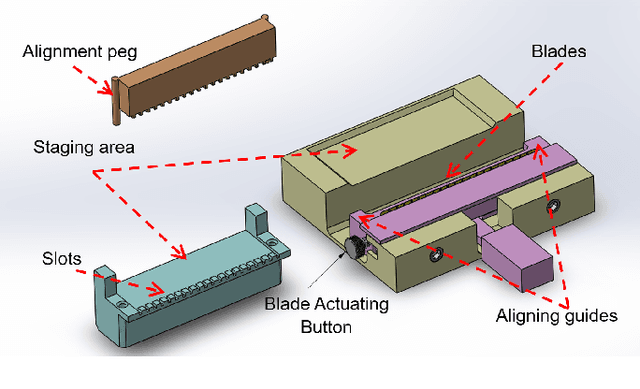


The treatment of malaria is a global health challenge that stands to benefit from the widespread introduction of a vaccine for the disease. A method has been developed to create a live organism vaccine using the sporozoites (SPZ) of the parasite Plasmodium falciparum (Pf), which are concentrated in the salivary glands of infected mosquitoes. Current manual dissection methods to obtain these PfSPZ are not optimally efficient for large-scale vaccine production. We propose an improved dissection procedure and a mechanical fixture that increases the rate of mosquito dissection and helps to deskill this stage of the production process. We further demonstrate the automation of a key step in this production process, the picking and placing of mosquitoes from a staging apparatus into a dissection assembly. This unit test of a robotic mosquito pick-and-place system is performed using a custom-designed micro-gripper attached to a four degree of freedom (4-DOF) robot under the guidance of a computer vision system. Mosquitoes are autonomously grasped and pulled to a pair of notched dissection blades to remove the head of the mosquito, allowing access to the salivary glands. Placement into these blades is adapted based on output from computer vision to accommodate for the unique anatomy and orientation of each grasped mosquito. In this pilot test of the system on 50 mosquitoes, we demonstrate a 100% grasping accuracy and a 90% accuracy in placing the mosquito with its neck within the blade notches such that the head can be removed. This is a promising result for this difficult and non-standard pick-and-place task.
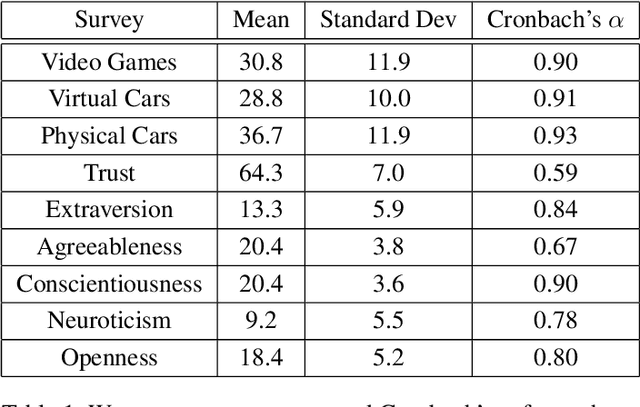
Four Years in Review: Statistical Practices of Likert Scales in Human-Robot Interaction Studies
Jan 31, 2020


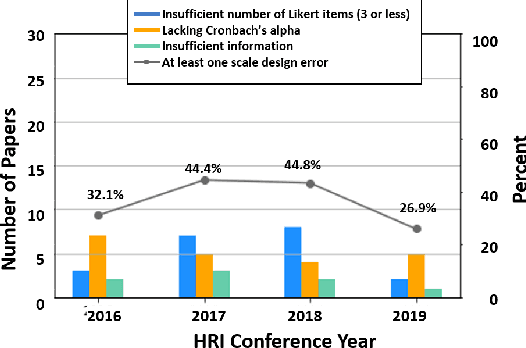
As robots become more prevalent, the importance of the field of human-robot interaction (HRI) grows accordingly. As such, we should endeavor to employ the best statistical practices. Likert scales are commonly used metrics in HRI to measure perceptions and attitudes. Due to misinformation or honest mistakes, most HRI researchers do not adopt best practices when analyzing Likert data. We conduct a review of psychometric literature to determine the current standard for Likert scale design and analysis. Next, we conduct a survey of four years of the International Conference on Human-Robot Interaction (2016 through 2019) and report on incorrect statistical practices and design of Likert scales. During these years, only 3 of the 110 papers applied proper statistical testing to correctly-designed Likert scales. Our analysis suggests there are areas for meaningful improvement in the design and testing of Likert scales. Lastly, we provide recommendations to improve the accuracy of conclusions drawn from Likert data.