 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoS: Enhancing Personalization and Mitigating Bias with Context Steering
May 02, 2024



When querying a large language model (LLM), the context, i.e. personal, demographic, and cultural information specific to an end-user, can significantly shape the response of the LLM. For example, asking the model to explain Newton's second law with the context "I am a toddler" yields a different answer compared to the context "I am a physics professor." Proper usage of the context enables the LLM to generate personalized responses, whereas inappropriate contextual influence can lead to stereotypical and potentially harmful generations (e.g. associating "female" with "housekeeper"). In practice, striking the right balance when leveraging context is a nuanced and challenging problem that is often situation-dependent. One common approach to address this challenge is to fine-tune LLMs on contextually appropriate responses. However, this approach is expensive, time-consuming, and not controllable for end-users in different situations. In this work, we propose Context Steering (CoS) - a simple training-free method that can be easily applied to autoregressive LLMs at inference time. By measuring the contextual influence in terms of token prediction likelihood and modulating it, our method enables practitioners to determine the appropriate level of contextual influence based on their specific use case and end-user base. We showcase a variety of applications of CoS including amplifying the contextual influence to achieve better personalization and mitigating unwanted influence for reducing model bias. In addition, we show that we can combine CoS with Bayesian Inference to quantify the extent of hate speech on the internet. We demonstrate the effectiveness of CoS on state-of-the-art LLMs and benchmarks.
Quantifying Assistive Robustness Via the Natural-Adversarial Frontier
Oct 16, 2023



Our ultimate goal is to build robust policies for robots that assist people. What makes this hard is that people can behave unexpectedly at test time, potentially interacting with the robot outside its training distribution and leading to failures. Even just measuring robustness is a challenge. Adversarial perturbations are the default, but they can paint the wrong picture: they can correspond to human motions that are unlikely to occur during natural interactions with people. A robot policy might fail under small adversarial perturbations but work under large natural perturbations. We propose that capturing robustness in these interactive settings requires constructing and analyzing the entire natural-adversarial frontier: the Pareto-frontier of human policies that are the best trade-offs between naturalness and low robot performance. We introduce RIGID, a method for constructing this frontier by training adversarial human policies that trade off between minimizing robot reward and acting human-like (as measured by a discriminator). On an Assistive Gym task, we use RIGID to analyze the performance of standard collaborative Reinforcement Learning, as well as the performance of existing methods meant to increase robustness. We also compare the frontier RIGID identifies with the failures identified in expert adversarial interaction, and with naturally-occurring failures during user interaction. Overall, we find evidence that RIGID can provide a meaningful measure of robustness predictive of deployment performance, and uncover failure cases in human-robot interaction that are difficult to find manually. https://ood-human.github.io.
Learning Representations that Enable Generalization in Assistive Tasks
Dec 05, 2022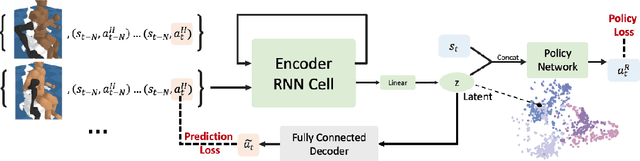



Recent work in sim2real has successfully enabled robots to act in physical environments by training in simulation with a diverse ''population'' of environments (i.e. domain randomization). In this work, we focus on enabling generalization in assistive tasks: tasks in which the robot is acting to assist a user (e.g. helping someone with motor impairments with bathing or with scratching an itch). Such tasks are particularly interesting relative to prior sim2real successes because the environment now contains a human who is also acting. This complicates the problem because the diversity of human users (instead of merely physical environment parameters) is more difficult to capture in a population, thus increasing the likelihood of encountering out-of-distribution (OOD) human policies at test time. We advocate that generalization to such OOD policies benefits from (1) learning a good latent representation for human policies that test-time humans can accurately be mapped to, and (2) making that representation adaptable with test-time interaction data, instead of relying on it to perfectly capture the space of human policies based on the simulated population only. We study how to best learn such a representation by evaluating on purposefully constructed OOD test policies. We find that sim2real methods that encode environment (or population) parameters and work well in tasks that robots do in isolation, do not work well in assistance. In assistance, it seems crucial to train the representation based on the history of interaction directly, because that is what the robot will have access to at test time. Further, training these representations to then predict human actions not only gives them better structure, but also enables them to be fine-tuned at test-time, when the robot observes the partner act. https://adaptive-caregiver.github.io.
A Study of Causal Confusion in Preference-Based Reward Learning
Apr 13, 2022
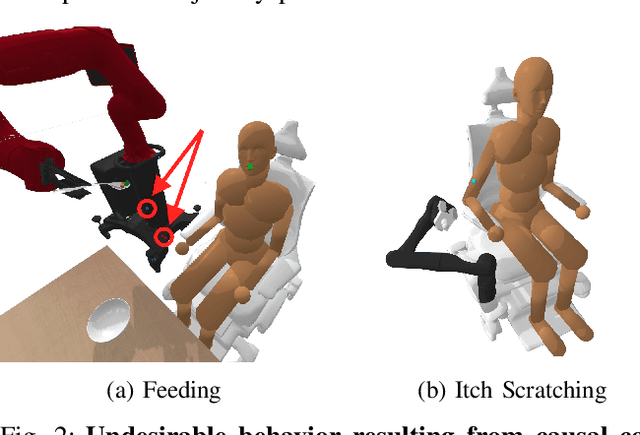
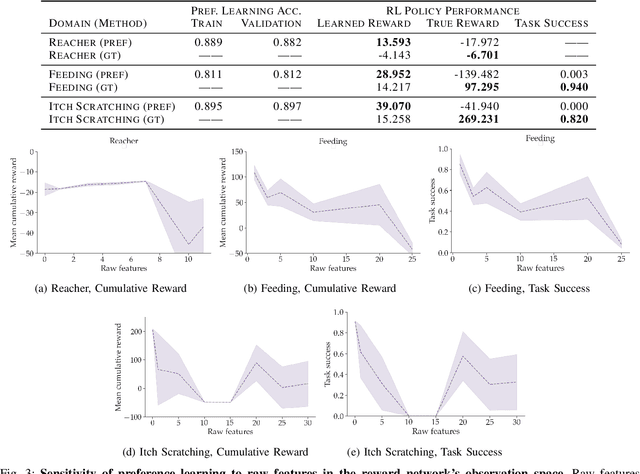

Learning robot policies via preference-based reward learning is an increasingly popular method for customizing robot behavior. However, in recent years, there has been a growing body of anecdotal evidence that learning reward functions from preferences is prone to spurious correlations and reward gaming or hacking behaviors. While there is much anecdotal, empirical, and theoretical analysis of causal confusion and reward gaming behaviors both in reinforcement learning and imitation learning approaches that directly map from states to actions, we provide the first systematic study of causal confusion in the context of learning reward functions from preferences. To facilitate this study, we identify a set of three preference learning benchmark domains where we observe causal confusion when learning from offline datasets of pairwise trajectory preferences: a simple reacher domain, an assistive feeding domain, and an itch-scratching domain. To gain insight into this observed causal confusion, we present a sensitivity analysis that explores the effect of different factors--including the type of training data, reward model capacity, and feature dimensionality--on the robustness of rewards learned from preferences. We find evidence that learning rewards from pairwise trajectory preferences is highly sensitive and non-robust to spurious features and increasing model capacity, but not as sensitive to the type of training data. Videos, code, and supplemental results are available at https://sites.google.com/view/causal-reward-confusion.
Assisted Robust Reward Design
Nov 18, 2021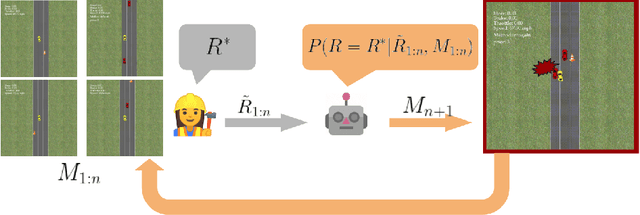
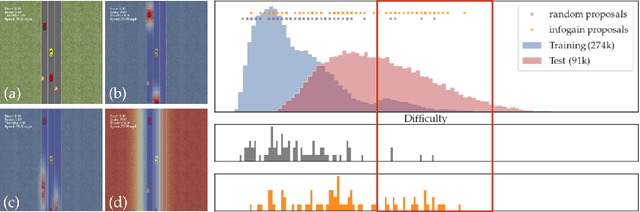
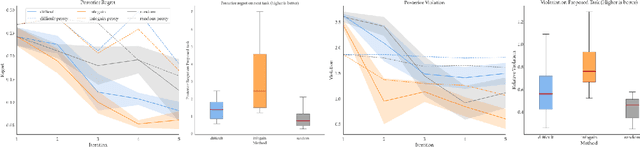
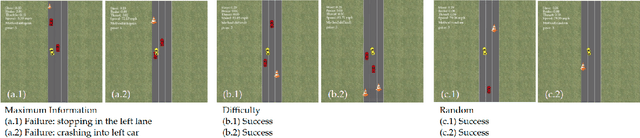
Real-world robotic tasks require complex reward functions. When we define the problem the robot needs to solve, we pretend that a designer specifies this complex reward exactly, and it is set in stone from then on. In practice, however, reward design is an iterative process: the designer chooses a reward, eventually encounters an "edge-case" environment where the reward incentivizes the wrong behavior, revises the reward, and repeats. What would it mean to rethink robotics problems to formally account for this iterative nature of reward design? We propose that the robot not take the specified reward for granted, but rather have uncertainty about it, and account for the future design iterations as future evidence. We contribute an Assisted Reward Design method that speeds up the design process by anticipating and influencing this future evidence: rather than letting the designer eventually encounter failure cases and revise the reward then, the method actively exposes the designer to such environments during the development phase. We test this method in a simplified autonomous driving task and find that it more quickly improves the car's behavior in held-out environments by proposing environments that are "edge cases" for the current reward.