 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbeMDE: Uncertainty-Guided Active Proprioception for Monocular Depth Estimation in Surgical Robotics
Dec 17, 2025Monocular depth estimation (MDE) provides a useful tool for robotic perception, but its predictions are often uncertain and inaccurate in challenging environments such as surgical scenes where textureless surfaces, specular reflections, and occlusions are common. To address this, we propose ProbeMDE, a cost-aware active sensing framework that combines RGB images with sparse proprioceptive measurements for MDE. Our approach utilizes an ensemble of MDE models to predict dense depth maps conditioned on both RGB images and on a sparse set of known depth measurements obtained via proprioception, where the robot has touched the environment in a known configuration. We quantify predictive uncertainty via the ensemble's variance and measure the gradient of the uncertainty with respect to candidate measurement locations. To prevent mode collapse while selecting maximally informative locations to propriocept (touch), we leverage Stein Variational Gradient Descent (SVGD) over this gradient map. We validate our method in both simulated and physical experiments on central airway obstruction surgical phantoms. Our results demonstrate that our approach outperforms baseline methods across standard depth estimation metrics, achieving higher accuracy while minimizing the number of required proprioceptive measurements. Project page: https://brittonjordan.github.io/probe_mde/
Monte Carlo Augmented Actor-Critic for Sparse Reward Deep Reinforcement Learning from Suboptimal Demonstrations
Oct 14, 2022

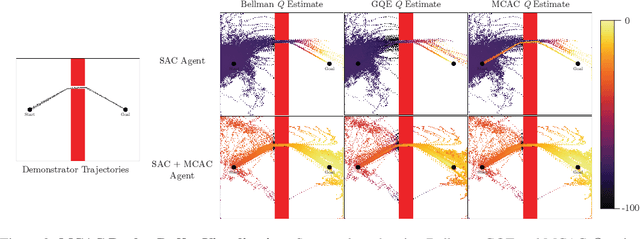

Providing densely shaped reward functions for RL algorithms is often exceedingly challenging, motivating the development of RL algorithms that can learn from easier-to-specify sparse reward functions. This sparsity poses new exploration challenges. One common way to address this problem is using demonstrations to provide initial signal about regions of the state space with high rewards. However, prior RL from demonstrations algorithms introduce significant complexity and many hyperparameters, making them hard to implement and tune. We introduce Monte Carlo Augmented Actor Critic (MCAC), a parameter free modification to standard actor-critic algorithms which initializes the replay buffer with demonstrations and computes a modified $Q$-value by taking the maximum of the standard temporal distance (TD) target and a Monte Carlo estimate of the reward-to-go. This encourages exploration in the neighborhood of high-performing trajectories by encouraging high $Q$-values in corresponding regions of the state space. Experiments across $5$ continuous control domains suggest that MCAC can be used to significantly increase learning efficiency across $6$ commonly used RL and RL-from-demonstrations algorithms. See https://sites.google.com/view/mcac-rl for code and supplementary material.
A Study of Causal Confusion in Preference-Based Reward Learning
Apr 13, 2022
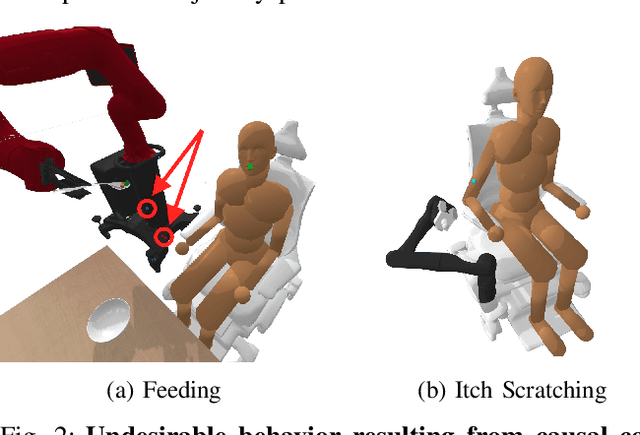
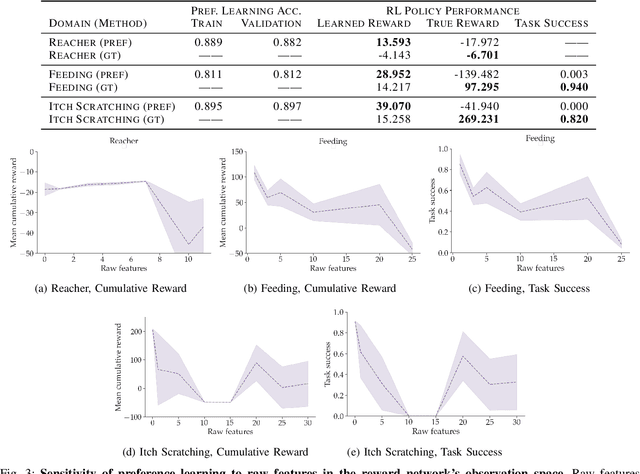

Learning robot policies via preference-based reward learning is an increasingly popular method for customizing robot behavior. However, in recent years, there has been a growing body of anecdotal evidence that learning reward functions from preferences is prone to spurious correlations and reward gaming or hacking behaviors. While there is much anecdotal, empirical, and theoretical analysis of causal confusion and reward gaming behaviors both in reinforcement learning and imitation learning approaches that directly map from states to actions, we provide the first systematic study of causal confusion in the context of learning reward functions from preferences. To facilitate this study, we identify a set of three preference learning benchmark domains where we observe causal confusion when learning from offline datasets of pairwise trajectory preferences: a simple reacher domain, an assistive feeding domain, and an itch-scratching domain. To gain insight into this observed causal confusion, we present a sensitivity analysis that explores the effect of different factors--including the type of training data, reward model capacity, and feature dimensionality--on the robustness of rewards learned from preferences. We find evidence that learning rewards from pairwise trajectory preferences is highly sensitive and non-robust to spurious features and increasing model capacity, but not as sensitive to the type of training data. Videos, code, and supplemental results are available at https://sites.google.com/view/causal-reward-confusion.
Coupling Rendering and Generative Adversarial Networks for Artificial SAS Image Generation
Oct 02, 2019
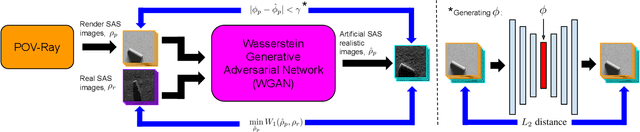

Acquisition of Synthetic Aperture Sonar (SAS) datasets is bottlenecked by the costly deployment of SAS imaging systems, and even when data acquisition is possible,the data is often skewed towards containing barren seafloor rather than objects of interest. We present a novel pipeline, called SAS GAN, which couples an optical renderer with a generative adversarial network (GAN) to synthesize realistic SAS images of targets on the seafloor. This coupling enables high levels of SAS image realism while enabling control over image geometry and parameters. We demonstrate qualitative results by presenting examples of images created with our pipeline. We also present quantitative results through the use of t-SNE and the Fr\'echet Inception Distance to argue that our generated SAS imagery potentially augments SAS datasets more effectively than an off-the-shelf GAN.
Measuring Human Assessed Complexity in Synthetic Aperture Sonar Imagery Using the Elo Rating System
Aug 15, 2018

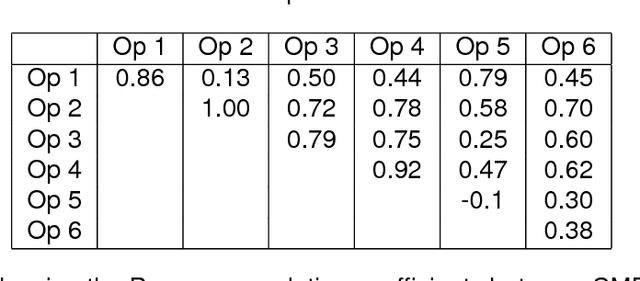

Performance of automatic target recognition from synthetic aperture sonar data is heavily dependent on the complexity of the beamformed imagery. Several mechanisms can contribute to this, including unwanted vehicle dynamics, the bathymetry of the scene, and the presence of natural and manmade clutter. To understand the impact of the environmental complexity on image perception, researchers have taken approaches rooted in information theory, or heuristics. Despite these efforts, a quantitative measure for complexity has not been related to the phenomenology from which it is derived. By using subject matter experts (SMEs) we derive a complexity metric for a set of imagery which accounts for the underlying phenomenology. The goal of this work is to develop an understanding of how several common information theoretic and heuristic measures are related to the SME perceived complexity in synthetic aperture sonar imagery. To achieve this, an ensemble of 10-meter x 10-meter images were cropped from a high-frequency SAS data set that spans multiple environments. The SME's were presented pairs of images from which they could rate the relative image complexity. These comparisons were then converted into the desired sequential ranking using a method first developed by A. Elo for establishing rankings of chess players. The Elo method produced a plausible rank ordering across the broad dataset. The heuristic and information theoretical metrics were then compared to the image rank from which they were derived. The metrics with the highest degree of correlation were those relating to spatial information, e.g. variations in pixel intensity, with an R-squared value of approximately 0.9. However, this agreement was dependent on the scale from which the spatial variation was measured. Results will also be presented for many other measures including lacunarity, image compression, and entropy.