 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDEEPTalk: Dynamic Emotion Embedding for Probabilistic Speech-Driven 3D Face Animation
Aug 12, 2024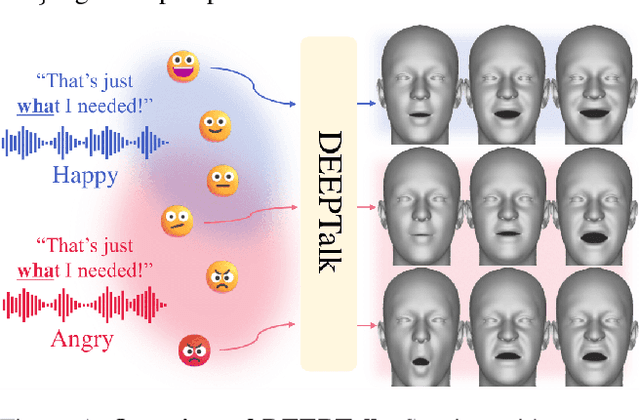

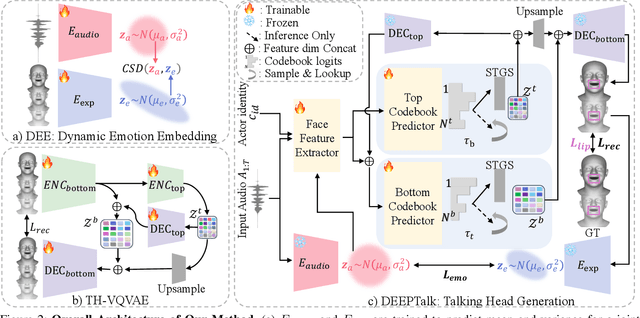
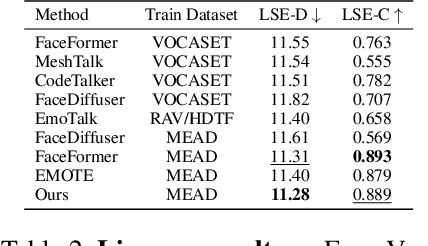
Speech-driven 3D facial animation has garnered lots of attention thanks to its broad range of applications. Despite recent advancements in achieving realistic lip motion, current methods fail to capture the nuanced emotional undertones conveyed through speech and produce monotonous facial motion. These limitations result in blunt and repetitive facial animations, reducing user engagement and hindering their applicability. To address these challenges, we introduce DEEPTalk, a novel approach that generates diverse and emotionally rich 3D facial expressions directly from speech inputs. To achieve this, we first train DEE (Dynamic Emotion Embedding), which employs probabilistic contrastive learning to forge a joint emotion embedding space for both speech and facial motion. This probabilistic framework captures the uncertainty in interpreting emotions from speech and facial motion, enabling the derivation of emotion vectors from its multifaceted space. Moreover, to generate dynamic facial motion, we design TH-VQVAE (Temporally Hierarchical VQ-VAE) as an expressive and robust motion prior overcoming limitations of VAEs and VQ-VAEs. Utilizing these strong priors, we develop DEEPTalk, A talking head generator that non-autoregressively predicts codebook indices to create dynamic facial motion, incorporating a novel emotion consistency loss. Extensive experiments on various datasets demonstrate the effectiveness of our approach in creating diverse, emotionally expressive talking faces that maintain accurate lip-sync. Source code will be made publicly available soon.
Measuring Human Assessed Complexity in Synthetic Aperture Sonar Imagery Using the Elo Rating System
Aug 15, 2018

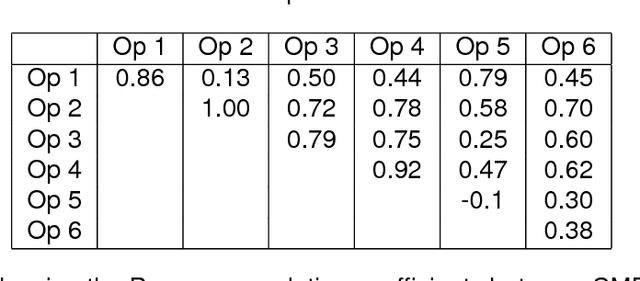

Performance of automatic target recognition from synthetic aperture sonar data is heavily dependent on the complexity of the beamformed imagery. Several mechanisms can contribute to this, including unwanted vehicle dynamics, the bathymetry of the scene, and the presence of natural and manmade clutter. To understand the impact of the environmental complexity on image perception, researchers have taken approaches rooted in information theory, or heuristics. Despite these efforts, a quantitative measure for complexity has not been related to the phenomenology from which it is derived. By using subject matter experts (SMEs) we derive a complexity metric for a set of imagery which accounts for the underlying phenomenology. The goal of this work is to develop an understanding of how several common information theoretic and heuristic measures are related to the SME perceived complexity in synthetic aperture sonar imagery. To achieve this, an ensemble of 10-meter x 10-meter images were cropped from a high-frequency SAS data set that spans multiple environments. The SME's were presented pairs of images from which they could rate the relative image complexity. These comparisons were then converted into the desired sequential ranking using a method first developed by A. Elo for establishing rankings of chess players. The Elo method produced a plausible rank ordering across the broad dataset. The heuristic and information theoretical metrics were then compared to the image rank from which they were derived. The metrics with the highest degree of correlation were those relating to spatial information, e.g. variations in pixel intensity, with an R-squared value of approximately 0.9. However, this agreement was dependent on the scale from which the spatial variation was measured. Results will also be presented for many other measures including lacunarity, image compression, and entropy.