 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDEEPTalk: Dynamic Emotion Embedding for Probabilistic Speech-Driven 3D Face Animation
Aug 12, 2024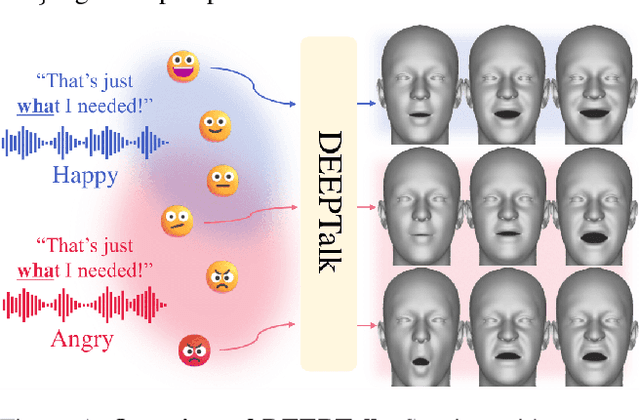

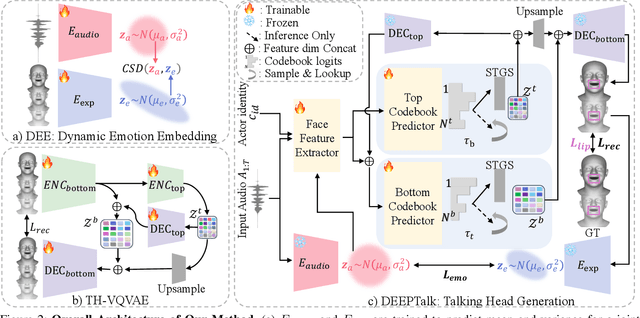
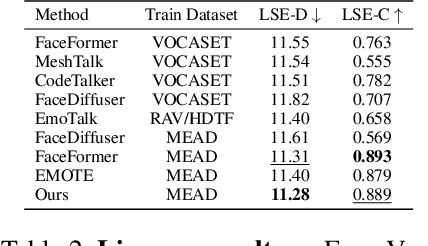
Speech-driven 3D facial animation has garnered lots of attention thanks to its broad range of applications. Despite recent advancements in achieving realistic lip motion, current methods fail to capture the nuanced emotional undertones conveyed through speech and produce monotonous facial motion. These limitations result in blunt and repetitive facial animations, reducing user engagement and hindering their applicability. To address these challenges, we introduce DEEPTalk, a novel approach that generates diverse and emotionally rich 3D facial expressions directly from speech inputs. To achieve this, we first train DEE (Dynamic Emotion Embedding), which employs probabilistic contrastive learning to forge a joint emotion embedding space for both speech and facial motion. This probabilistic framework captures the uncertainty in interpreting emotions from speech and facial motion, enabling the derivation of emotion vectors from its multifaceted space. Moreover, to generate dynamic facial motion, we design TH-VQVAE (Temporally Hierarchical VQ-VAE) as an expressive and robust motion prior overcoming limitations of VAEs and VQ-VAEs. Utilizing these strong priors, we develop DEEPTalk, A talking head generator that non-autoregressively predicts codebook indices to create dynamic facial motion, incorporating a novel emotion consistency loss. Extensive experiments on various datasets demonstrate the effectiveness of our approach in creating diverse, emotionally expressive talking faces that maintain accurate lip-sync. Source code will be made publicly available soon.
DOO-RE: A dataset of ambient sensors in a meeting room for activity recognition
Jan 17, 2024With the advancement of IoT technology, recognizing user activities with machine learning methods is a promising way to provide various smart services to users. High-quality data with privacy protection is essential for deploying such services in the real world. Data streams from surrounding ambient sensors are well suited to the requirement. Existing ambient sensor datasets only support constrained private spaces and those for public spaces have yet to be explored despite growing interest in research on them. To meet this need, we build a dataset collected from a meeting room equipped with ambient sensors. The dataset, DOO-RE, includes data streams from various ambient sensor types such as Sound and Projector. Each sensor data stream is segmented into activity units and multiple annotators provide activity labels through a cross-validation annotation process to improve annotation quality. We finally obtain 9 types of activities. To our best knowledge, DOO-RE is the first dataset to support the recognition of both single and group activities in a real meeting room with reliable annotations.
Unsupervised Missing Cone Deep Learning in Optical Diffraction Tomography
Mar 16, 2021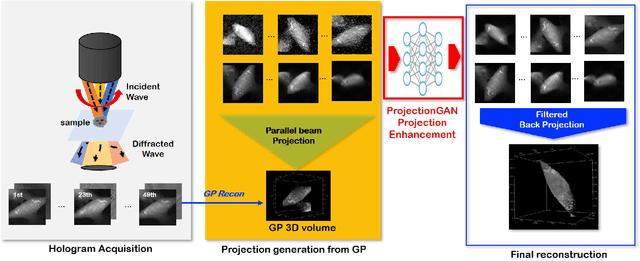
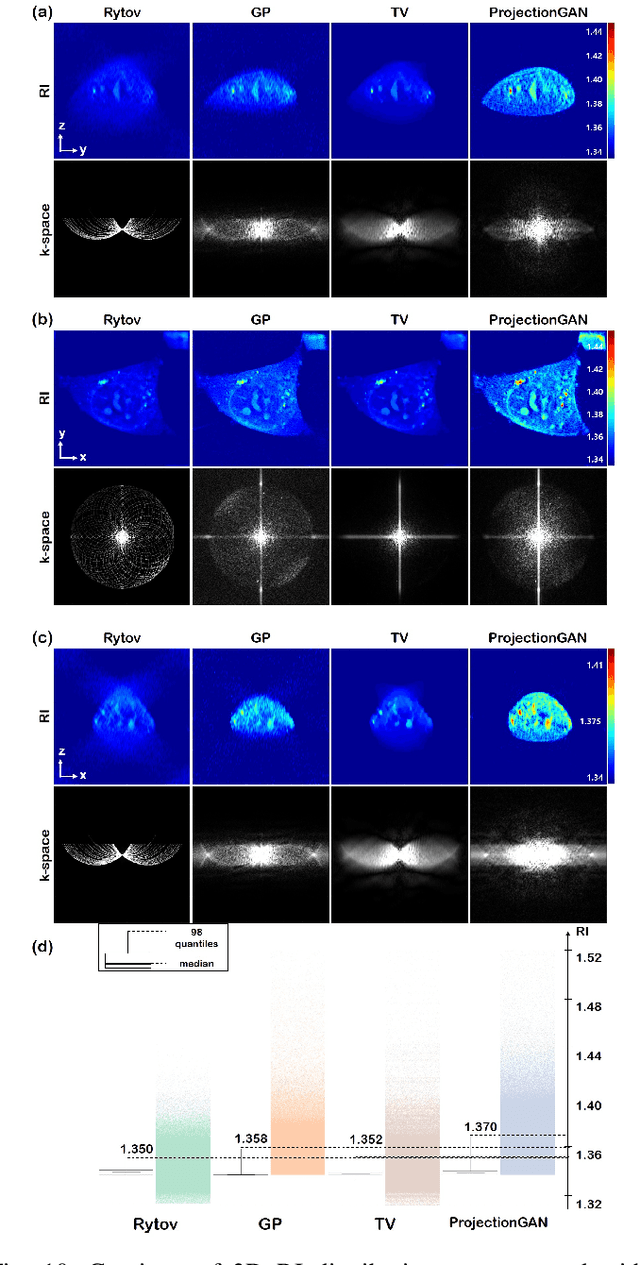
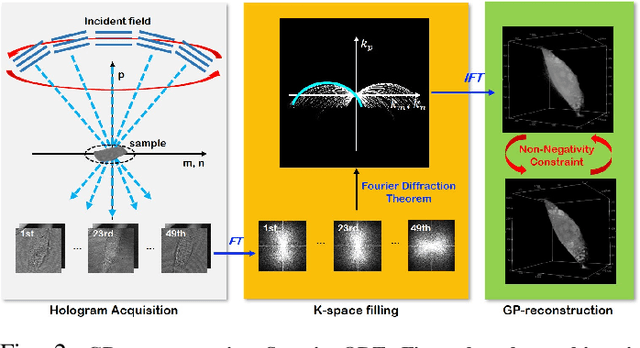

Optical diffraction tomography (ODT) produces three dimensional distribution of refractive index (RI) by measuring scattering fields at various angles. Although the distribution of RI index is highly informative, due to the missing cone problem stemming from the limited-angle acquisition of holograms, reconstructions have very poor resolution along axial direction compared to the horizontal imaging plane. To solve this issue, here we present a novel unsupervised deep learning framework, which learns the probability distribution of missing projection views through optimal transport driven cycleGAN. Experimental results show that missing cone artifact in ODT can be significantly resolved by the proposed method.
Quantitative Phase Imaging and Artificial Intelligence: A Review
Jul 13, 2018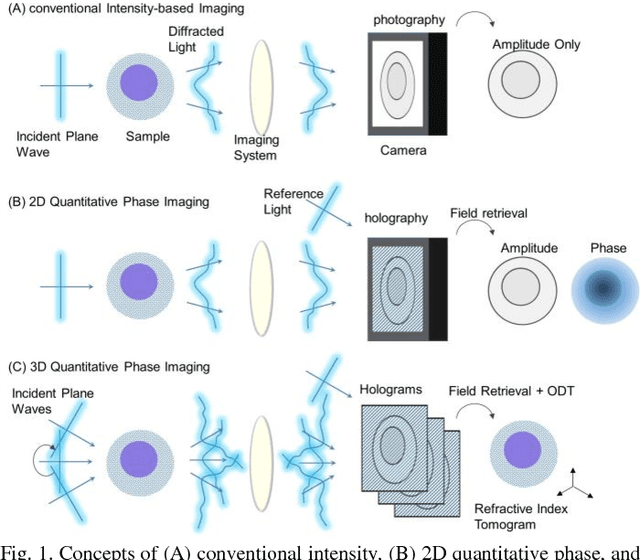
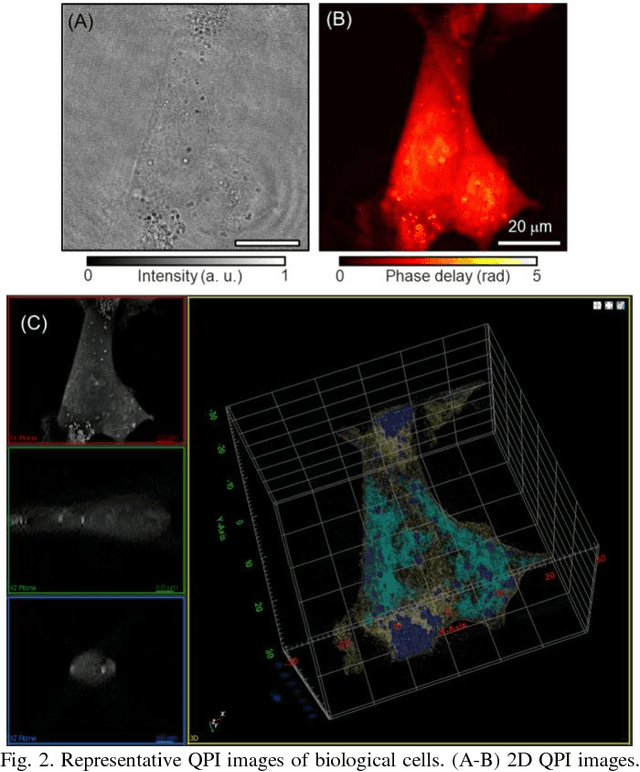

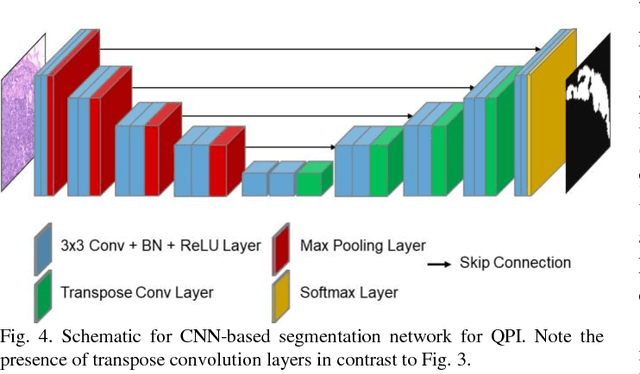
Recent advances in quantitative phase imaging (QPI) and artificial intelligence (AI) have opened up the possibility of an exciting frontier. The fast and label-free nature of QPI enables the rapid generation of large-scale and uniform-quality imaging data in two, three, and four dimensions. Subsequently, the AI-assisted interrogation of QPI data using data-driven machine learning techniques results in a variety of biomedical applications. Also, machine learning enhances QPI itself. Herein, we review the synergy between QPI and machine learning with a particular focus on deep learning. Further, we provide practical guidelines and perspectives for further development.