 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Study of Causal Confusion in Preference-Based Reward Learning
Paper and Code

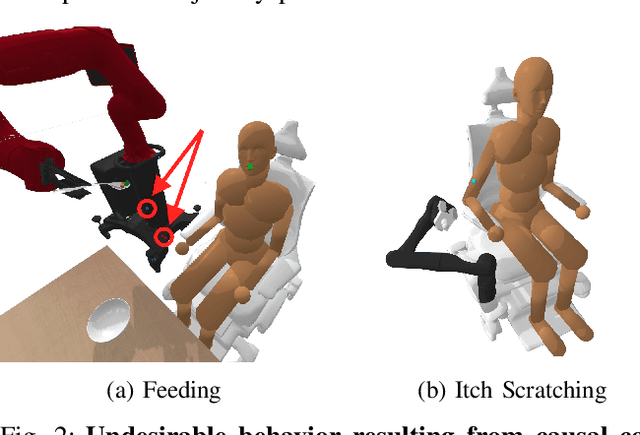
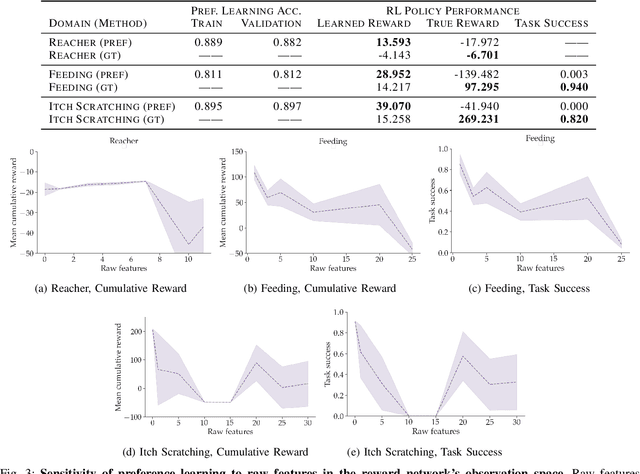

Learning robot policies via preference-based reward learning is an increasingly popular method for customizing robot behavior. However, in recent years, there has been a growing body of anecdotal evidence that learning reward functions from preferences is prone to spurious correlations and reward gaming or hacking behaviors. While there is much anecdotal, empirical, and theoretical analysis of causal confusion and reward gaming behaviors both in reinforcement learning and imitation learning approaches that directly map from states to actions, we provide the first systematic study of causal confusion in the context of learning reward functions from preferences. To facilitate this study, we identify a set of three preference learning benchmark domains where we observe causal confusion when learning from offline datasets of pairwise trajectory preferences: a simple reacher domain, an assistive feeding domain, and an itch-scratching domain. To gain insight into this observed causal confusion, we present a sensitivity analysis that explores the effect of different factors--including the type of training data, reward model capacity, and feature dimensionality--on the robustness of rewards learned from preferences. We find evidence that learning rewards from pairwise trajectory preferences is highly sensitive and non-robust to spurious features and increasing model capacity, but not as sensitive to the type of training data. Videos, code, and supplemental results are available at https://sites.google.com/view/causal-reward-confusion.