 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAMPLIFY: Actionless Motion Priors for Robot Learning from Videos
Jun 17, 2025Action-labeled data for robotics is scarce and expensive, limiting the generalization of learned policies. In contrast, vast amounts of action-free video data are readily available, but translating these observations into effective policies remains a challenge. We introduce AMPLIFY, a novel framework that leverages large-scale video data by encoding visual dynamics into compact, discrete motion tokens derived from keypoint trajectories. Our modular approach separates visual motion prediction from action inference, decoupling the challenges of learning what motion defines a task from how robots can perform it. We train a forward dynamics model on abundant action-free videos and an inverse dynamics model on a limited set of action-labeled examples, allowing for independent scaling. Extensive evaluations demonstrate that the learned dynamics are both accurate, achieving up to 3.7x better MSE and over 2.5x better pixel prediction accuracy compared to prior approaches, and broadly useful. In downstream policy learning, our dynamics predictions enable a 1.2-2.2x improvement in low-data regimes, a 1.4x average improvement by learning from action-free human videos, and the first generalization to LIBERO tasks from zero in-distribution action data. Beyond robotic control, we find the dynamics learned by AMPLIFY to be a versatile latent world model, enhancing video prediction quality. Our results present a novel paradigm leveraging heterogeneous data sources to build efficient, generalizable world models. More information can be found at https://amplify-robotics.github.io/.
Adapt3R: Adaptive 3D Scene Representation for Domain Transfer in Imitation Learning
Mar 06, 2025Imitation Learning (IL) has been very effective in training robots to perform complex and diverse manipulation tasks. However, its performance declines precipitously when the observations are out of the training distribution. 3D scene representations that incorporate observations from calibrated RGBD cameras have been proposed as a way to improve generalizability of IL policies, but our evaluations in cross-embodiment and novel camera pose settings found that they show only modest improvement. To address those challenges, we propose Adaptive 3D Scene Representation (Adapt3R), a general-purpose 3D observation encoder which uses a novel architecture to synthesize data from one or more RGBD cameras into a single vector that can then be used as conditioning for arbitrary IL algorithms. The key idea is to use a pretrained 2D backbone to extract semantic information about the scene, using 3D only as a medium for localizing this semantic information with respect to the end-effector. We show that when trained end-to-end with several SOTA multi-task IL algorithms, Adapt3R maintains these algorithms' multi-task learning capacity while enabling zero-shot transfer to novel embodiments and camera poses. Furthermore, we provide a detailed suite of ablation and sensitivity experiments to elucidate the design space for point cloud observation encoders.
QueST: Self-Supervised Skill Abstractions for Learning Continuous Control
Jul 23, 2024Generalization capabilities, or rather a lack thereof, is one of the most important unsolved problems in the field of robot learning, and while several large scale efforts have set out to tackle this problem, unsolved it remains. In this paper, we hypothesize that learning temporal action abstractions using latent variable models (LVMs), which learn to map data to a compressed latent space and back, is a promising direction towards low-level skills that can readily be used for new tasks. Although several works have attempted to show this, they have generally been limited by architectures that do not faithfully capture shareable representations. To address this we present Quantized Skill Transformer (QueST), which learns a larger and more flexible latent encoding that is more capable of modeling the breadth of low-level skills necessary for a variety of tasks. To make use of this extra flexibility, QueST imparts causal inductive bias from the action sequence data into the latent space, leading to more semantically useful and transferable representations. We compare to state-of-the-art imitation learning and LVM baselines and see that QueST's architecture leads to strong performance on several multitask and few-shot learning benchmarks. Further results and videos are available at https://quest-model.github.io/
Monte Carlo Augmented Actor-Critic for Sparse Reward Deep Reinforcement Learning from Suboptimal Demonstrations
Oct 14, 2022

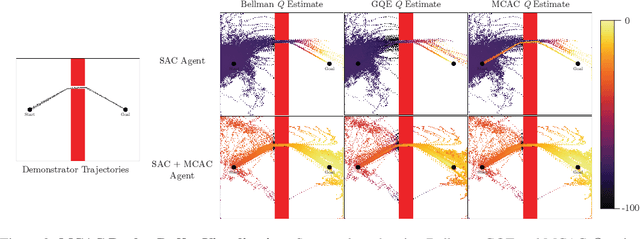

Providing densely shaped reward functions for RL algorithms is often exceedingly challenging, motivating the development of RL algorithms that can learn from easier-to-specify sparse reward functions. This sparsity poses new exploration challenges. One common way to address this problem is using demonstrations to provide initial signal about regions of the state space with high rewards. However, prior RL from demonstrations algorithms introduce significant complexity and many hyperparameters, making them hard to implement and tune. We introduce Monte Carlo Augmented Actor Critic (MCAC), a parameter free modification to standard actor-critic algorithms which initializes the replay buffer with demonstrations and computes a modified $Q$-value by taking the maximum of the standard temporal distance (TD) target and a Monte Carlo estimate of the reward-to-go. This encourages exploration in the neighborhood of high-performing trajectories by encouraging high $Q$-values in corresponding regions of the state space. Experiments across $5$ continuous control domains suggest that MCAC can be used to significantly increase learning efficiency across $6$ commonly used RL and RL-from-demonstrations algorithms. See https://sites.google.com/view/mcac-rl for code and supplementary material.
Learning Self-Supervised Representations from Vision and Touch for Active Sliding Perception of Deformable Surfaces
Sep 26, 2022
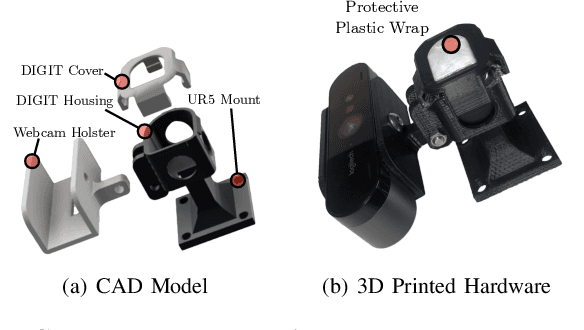


Humans make extensive use of vision and touch as complementary senses, with vision providing global information about the scene and touch measuring local information during manipulation without suffering from occlusions. In this work, we propose a novel framework for learning multi-task visuo-tactile representations in a self-supervised manner. We design a mechanism which enables a robot to autonomously collect spatially aligned visual and tactile data, a key property for downstream tasks. We then train visual and tactile encoders to embed these paired sensory inputs into a shared latent space using cross-modal contrastive loss. The learned representations are evaluated without fine-tuning on 5 perception and control tasks involving deformable surfaces: tactile classification, contact localization, anomaly detection (e.g., surgical phantom tumor palpation), tactile search from a visual query (e.g., garment feature localization under occlusion), and tactile servoing along cloth edges and cables. The learned representations achieve an 80% success rate on towel feature classification, a 73% average success rate on anomaly detection in surgical materials, a 100% average success rate on vision-guided tactile search, and 87.8% average servo distance along cables and garment seams. These results suggest the flexibility of the learned representations and pose a step toward task-agnostic visuo-tactile representation learning for robot control.
Learning to Localize, Grasp, and Hand Over Unmodified Surgical Needles
Dec 08, 2021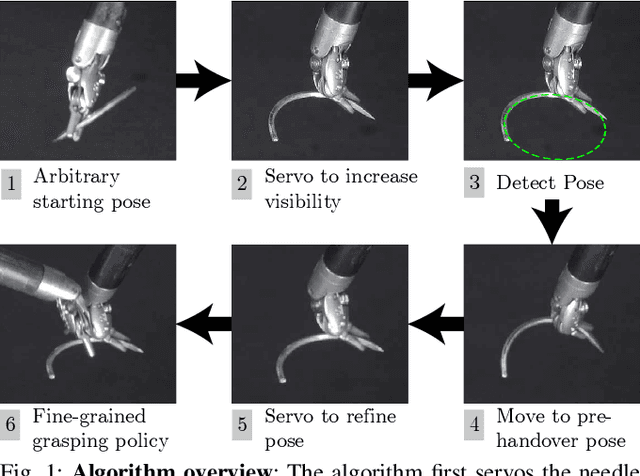
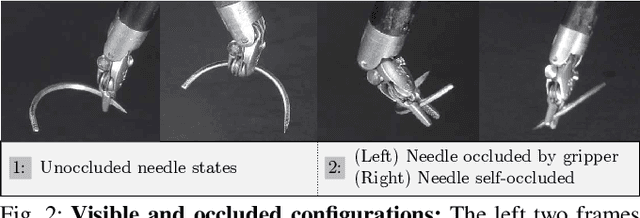
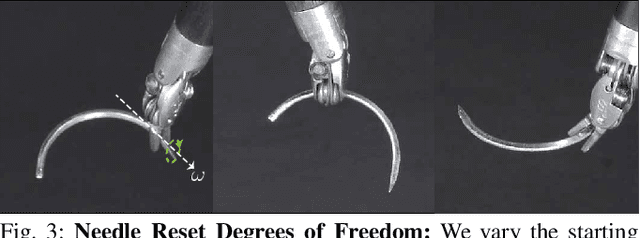

Robotic Surgical Assistants (RSAs) are commonly used to perform minimally invasive surgeries by expert surgeons. However, long procedures filled with tedious and repetitive tasks such as suturing can lead to surgeon fatigue, motivating the automation of suturing. As visual tracking of a thin reflective needle is extremely challenging, prior work has modified the needle with nonreflective contrasting paint. As a step towards automation of a suturing subtask without modifying the needle, we propose HOUSTON: Handoff of Unmodified, Surgical, Tool-Obstructed Needles, a problem and algorithm that uses a learned active sensing policy with a stereo camera to localize and align the needle into a visible and accessible pose for the other arm. To compensate for robot positioning and needle perception errors, the algorithm then executes a high-precision grasping motion that uses multiple cameras. In physical experiments using the da Vinci Research Kit (dVRK), HOUSTON successfully passes unmodified surgical needles with a success rate of 96.7% and is able to perform handover sequentially between the arms 32.4 times on average before failure. On needles unseen in training, HOUSTON achieves a success rate of 75 - 92.9%. To our knowledge, this work is the first to study handover of unmodified surgical needles. See https://tinyurl.com/houston-surgery for additional materials.
ThriftyDAgger: Budget-Aware Novelty and Risk Gating for Interactive Imitation Learning
Sep 17, 2021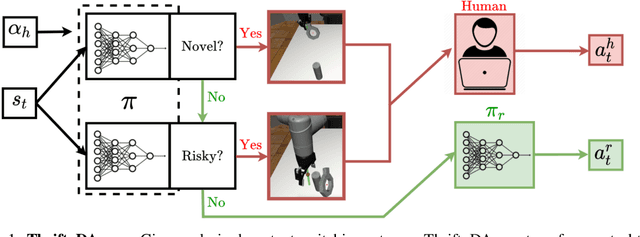


Effective robot learning often requires online human feedback and interventions that can cost significant human time, giving rise to the central challenge in interactive imitation learning: is it possible to control the timing and length of interventions to both facilitate learning and limit burden on the human supervisor? This paper presents ThriftyDAgger, an algorithm for actively querying a human supervisor given a desired budget of human interventions. ThriftyDAgger uses a learned switching policy to solicit interventions only at states that are sufficiently (1) novel, where the robot policy has no reference behavior to imitate, or (2) risky, where the robot has low confidence in task completion. To detect the latter, we introduce a novel metric for estimating risk under the current robot policy. Experiments in simulation and on a physical cable routing experiment suggest that ThriftyDAgger's intervention criteria balances task performance and supervisor burden more effectively than prior algorithms. ThriftyDAgger can also be applied at execution time, where it achieves a 100% success rate on both the simulation and physical tasks. A user study (N=10) in which users control a three-robot fleet while also performing a concentration task suggests that ThriftyDAgger increases human and robot performance by 58% and 80% respectively compared to the next best algorithm while reducing supervisor burden.
LS3: Latent Space Safe Sets for Long-Horizon Visuomotor Control of Iterative Tasks
Jul 10, 2021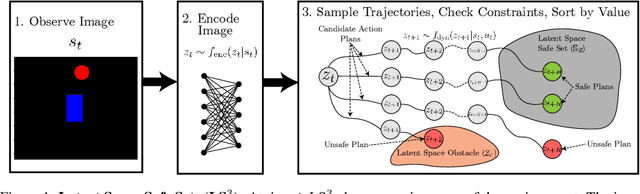



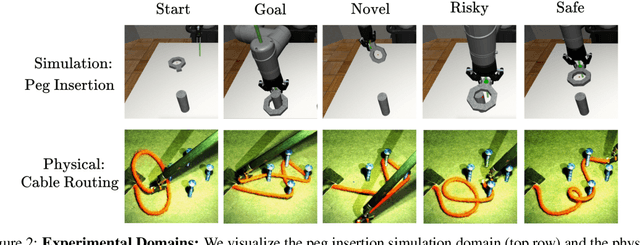
Reinforcement learning (RL) algorithms have shown impressive success in exploring high-dimensional environments to learn complex, long-horizon tasks, but can often exhibit unsafe behaviors and require extensive environment interaction when exploration is unconstrained. A promising strategy for safe learning in dynamically uncertain environments is requiring that the agent can robustly return to states where task success (and therefore safety) can be guaranteed. While this approach has been successful in low-dimensions, enforcing this constraint in environments with high-dimensional state spaces, such as images, is challenging. We present Latent Space Safe Sets (LS3), which extends this strategy to iterative, long-horizon tasks with image observations by using suboptimal demonstrations and a learned dynamics model to restrict exploration to the neighborhood of a learned Safe Set where task completion is likely. We evaluate LS3 on 4 domains, including a challenging sequential pushing task in simulation and a physical cable routing task. We find that LS3 can use prior task successes to restrict exploration and learn more efficiently than prior algorithms while satisfying constraints. See https://tinyurl.com/latent-ss for code and supplementary material.
Learning Accurate Long-term Dynamics for Model-based Reinforcement Learning
Dec 16, 2020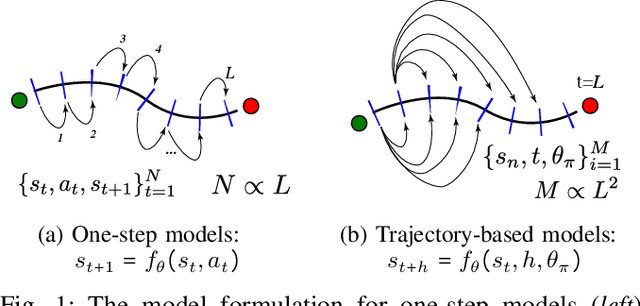
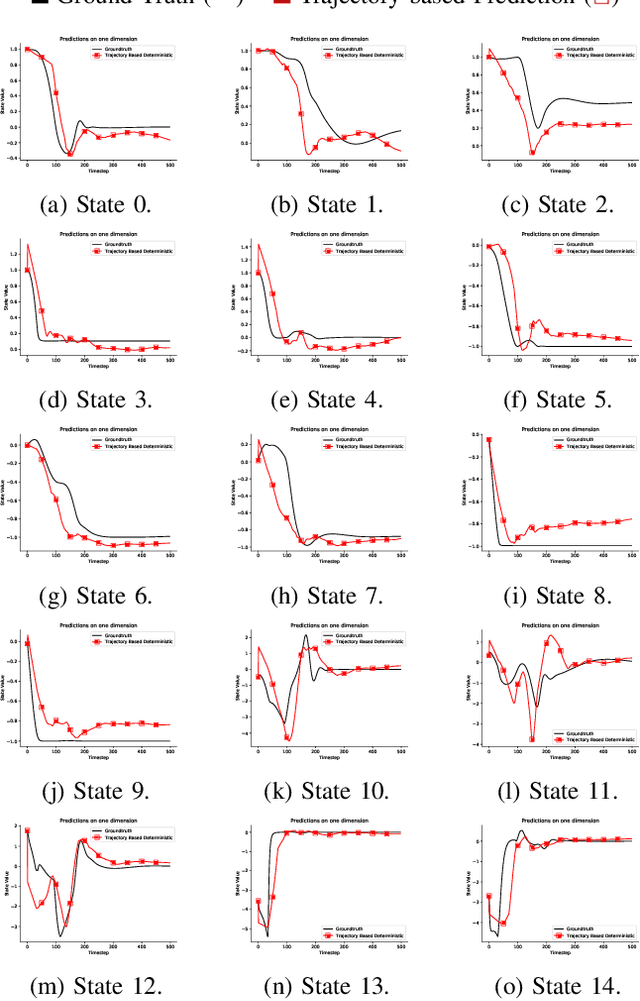
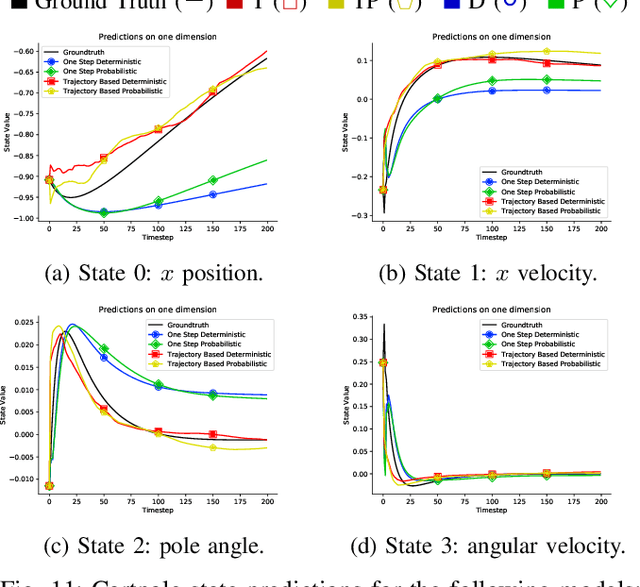
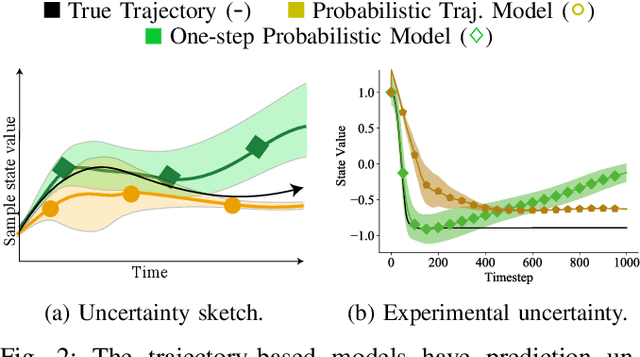
Accurately predicting the dynamics of robotic systems is crucial for model-based control and reinforcement learning. The most common way to estimate dynamics is by fitting a one-step ahead prediction model and using it to recursively propagate the predicted state distribution over long horizons. Unfortunately, this approach is known to compound even small prediction errors, making long-term predictions inaccurate. In this paper, we propose a new parametrization to supervised learning on state-action data to stably predict at longer horizons -- that we call a trajectory-based model. This trajectory-based model takes an initial state, a future time index, and control parameters as inputs, and predicts the state at the future time. Our results in simulated and experimental robotic tasks show that our trajectory-based models yield significantly more accurate long term predictions, improved sample efficiency, and ability to predict task reward.