 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaplacian Multi-scale Flow Matching for Generative Modeling
Feb 23, 2026In this paper, we present Laplacian multiscale flow matching (LapFlow), a novel framework that enhances flow matching by leveraging multi-scale representations for image generative modeling. Our approach decomposes images into Laplacian pyramid residuals and processes different scales in parallel through a mixture-of-transformers (MoT) architecture with causal attention mechanisms. Unlike previous cascaded approaches that require explicit renoising between scales, our model generates multi-scale representations in parallel, eliminating the need for bridging processes. The proposed multi-scale architecture not only improves generation quality but also accelerates the sampling process and promotes scaling flow matching methods. Through extensive experimentation on CelebA-HQ and ImageNet, we demonstrate that our method achieves superior sample quality with fewer GFLOPs and faster inference compared to single-scale and multi-scale flow matching baselines. The proposed model scales effectively to high-resolution generation (up to 1024$\times$1024) while maintaining lower computational overhead.
AutoRing: Imitation Learning--based Autonomous Intraocular Foreign Body Removal Manipulation with Eye Surgical Robot
Aug 27, 2025Intraocular foreign body removal demands millimeter-level precision in confined intraocular spaces, yet existing robotic systems predominantly rely on manual teleoperation with steep learning curves. To address the challenges of autonomous manipulation (particularly kinematic uncertainties from variable motion scaling and variation of the Remote Center of Motion (RCM) point), we propose AutoRing, an imitation learning framework for autonomous intraocular foreign body ring manipulation. Our approach integrates dynamic RCM calibration to resolve coordinate-system inconsistencies caused by intraocular instrument variation and introduces the RCM-ACT architecture, which combines action-chunking transformers with real-time kinematic realignment. Trained solely on stereo visual data and instrument kinematics from expert demonstrations in a biomimetic eye model, AutoRing successfully completes ring grasping and positioning tasks without explicit depth sensing. Experimental validation demonstrates end-to-end autonomy under uncalibrated microscopy conditions. The results provide a viable framework for developing intelligent eye-surgical systems capable of complex intraocular procedures.
QueST: Self-Supervised Skill Abstractions for Learning Continuous Control
Jul 23, 2024Generalization capabilities, or rather a lack thereof, is one of the most important unsolved problems in the field of robot learning, and while several large scale efforts have set out to tackle this problem, unsolved it remains. In this paper, we hypothesize that learning temporal action abstractions using latent variable models (LVMs), which learn to map data to a compressed latent space and back, is a promising direction towards low-level skills that can readily be used for new tasks. Although several works have attempted to show this, they have generally been limited by architectures that do not faithfully capture shareable representations. To address this we present Quantized Skill Transformer (QueST), which learns a larger and more flexible latent encoding that is more capable of modeling the breadth of low-level skills necessary for a variety of tasks. To make use of this extra flexibility, QueST imparts causal inductive bias from the action sequence data into the latent space, leading to more semantically useful and transferable representations. We compare to state-of-the-art imitation learning and LVM baselines and see that QueST's architecture leads to strong performance on several multitask and few-shot learning benchmarks. Further results and videos are available at https://quest-model.github.io/
Diffusion Policy Attacker: Crafting Adversarial Attacks for Diffusion-based Policies
May 29, 2024



Diffusion models (DMs) have emerged as a promising approach for behavior cloning (BC). Diffusion policies (DP) based on DMs have elevated BC performance to new heights, demonstrating robust efficacy across diverse tasks, coupled with their inherent flexibility and ease of implementation. Despite the increasing adoption of DP as a foundation for policy generation, the critical issue of safety remains largely unexplored. While previous attempts have targeted deep policy networks, DP used diffusion models as the policy network, making it ineffective to be attacked using previous methods because of its chained structure and randomness injected. In this paper, we undertake a comprehensive examination of DP safety concerns by introducing adversarial scenarios, encompassing offline and online attacks, and global and patch-based attacks. We propose DP-Attacker, a suite of algorithms that can craft effective adversarial attacks across all aforementioned scenarios. We conduct attacks on pre-trained diffusion policies across various manipulation tasks. Through extensive experiments, we demonstrate that DP-Attacker has the capability to significantly decrease the success rate of DP for all scenarios. Particularly in offline scenarios, DP-Attacker can generate highly transferable perturbations applicable to all frames. Furthermore, we illustrate the creation of adversarial physical patches that, when applied to the environment, effectively deceive the model. Video results are put in: https://sites.google.com/view/diffusion-policy-attacker.
RefDrop: Controllable Consistency in Image or Video Generation via Reference Feature Guidance
May 27, 2024
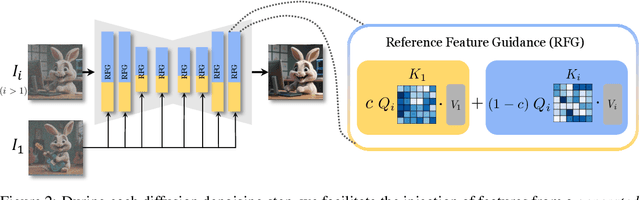
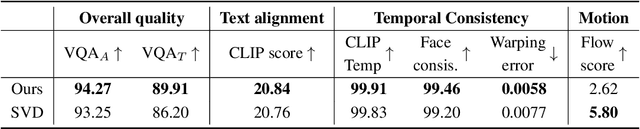

There is a rapidly growing interest in controlling consistency across multiple generated images using diffusion models. Among various methods, recent works have found that simply manipulating attention modules by concatenating features from multiple reference images provides an efficient approach to enhancing consistency without fine-tuning. Despite its popularity and success, few studies have elucidated the underlying mechanisms that contribute to its effectiveness. In this work, we reveal that the popular approach is a linear interpolation of image self-attention and cross-attention between synthesized content and reference features, with a constant rank-1 coefficient. Motivated by this observation, we find that a rank-1 coefficient is not necessary and simplifies the controllable generation mechanism. The resulting algorithm, which we coin as RefDrop, allows users to control the influence of reference context in a direct and precise manner. Besides further enhancing consistency in single-subject image generation, our method also enables more interesting applications, such as the consistent generation of multiple subjects, suppressing specific features to encourage more diverse content, and high-quality personalized video generation by boosting temporal consistency. Even compared with state-of-the-art image-prompt-based generators, such as IP-Adapter, RefDrop is competitive in terms of controllability and quality while avoiding the need to train a separate image encoder for feature injection from reference images, making it a versatile plug-and-play solution for any image or video diffusion model.
Pixel is a Barrier: Diffusion Models Are More Adversarially Robust Than We Think
May 02, 2024Adversarial examples for diffusion models are widely used as solutions for safety concerns. By adding adversarial perturbations to personal images, attackers can not edit or imitate them easily. However, it is essential to note that all these protections target the latent diffusion model (LDMs), the adversarial examples for diffusion models in the pixel space (PDMs) are largely overlooked. This may mislead us to think that the diffusion models are vulnerable to adversarial attacks like most deep models. In this paper, we show novel findings that: even though gradient-based white-box attacks can be used to attack the LDMs, they fail to attack PDMs. This finding is supported by extensive experiments of almost a wide range of attacking methods on various PDMs and LDMs with different model structures, which means diffusion models are indeed much more robust against adversarial attacks. We also find that PDMs can be used as an off-the-shelf purifier to effectively remove the adversarial patterns that were generated on LDMs to protect the images, which means that most protection methods nowadays, to some extent, cannot protect our images from malicious attacks. We hope that our insights will inspire the community to rethink the adversarial samples for diffusion models as protection methods and move forward to more effective protection. Codes are available in https://github.com/xavihart/PDM-Pure.
A Shared Control Approach Based on First-Order Dynamical Systems and Closed-Loop Variable Stiffness Control
Jul 19, 2023In this paper, we present a novel learning-based shared control framework. This framework deploys first-order Dynamical Systems (DS) as motion generators providing the desired reference motion, and a Variable Stiffness Dynamical Systems (VSDS) \cite{chen2021closed} for haptic guidance. We show how to shape several features of our controller in order to achieve authority allocation, local motion refinement, in addition to the inherent ability of the controller to automatically synchronize with the human state during joint task execution. We validate our approach in a teleoperated task scenario, where we also showcase the ability of our framework to deal with situations that require updating task knowledge due to possible changes in the task scenario, or changes in the environment. Finally, we conduct a user study to compare the performance of our VSDS controller for guidance generation to two state-of-the-art controllers in a target reaching task. The result shows that our VSDS controller has the highest successful rate of task execution among all conditions. Besides, our VSDS controller helps reduce the execution time and task load significantly, and was selected as the most favorable controller by participants.
Diffusion-Based Adversarial Sample Generation for Improved Stealthiness and Controllability
May 25, 2023Neural networks are known to be susceptible to adversarial samples: small variations of natural examples crafted to deliberately mislead the models. While they can be easily generated using gradient-based techniques in digital and physical scenarios, they often differ greatly from the actual data distribution of natural images, resulting in a trade-off between strength and stealthiness. In this paper, we propose a novel framework dubbed Diffusion-Based Projected Gradient Descent (Diff-PGD) for generating realistic adversarial samples. By exploiting a gradient guided by a diffusion model, Diff-PGD ensures that adversarial samples remain close to the original data distribution while maintaining their effectiveness. Moreover, our framework can be easily customized for specific tasks such as digital attacks, physical-world attacks, and style-based attacks. Compared with existing methods for generating natural-style adversarial samples, our framework enables the separation of optimizing adversarial loss from other surrogate losses (e.g., content/smoothness/style loss), making it more stable and controllable. Finally, we demonstrate that the samples generated using Diff-PGD have better transferability and anti-purification power than traditional gradient-based methods. Code will be released in https://github.com/xavihart/Diff-PGD
3D-IntPhys: Towards More Generalized 3D-grounded Visual Intuitive Physics under Challenging Scenes
Apr 22, 2023



Given a visual scene, humans have strong intuitions about how a scene can evolve over time under given actions. The intuition, often termed visual intuitive physics, is a critical ability that allows us to make effective plans to manipulate the scene to achieve desired outcomes without relying on extensive trial and error. In this paper, we present a framework capable of learning 3D-grounded visual intuitive physics models from videos of complex scenes with fluids. Our method is composed of a conditional Neural Radiance Field (NeRF)-style visual frontend and a 3D point-based dynamics prediction backend, using which we can impose strong relational and structural inductive bias to capture the structure of the underlying environment. Unlike existing intuitive point-based dynamics works that rely on the supervision of dense point trajectory from simulators, we relax the requirements and only assume access to multi-view RGB images and (imperfect) instance masks acquired using color prior. This enables the proposed model to handle scenarios where accurate point estimation and tracking are hard or impossible. We generate datasets including three challenging scenarios involving fluid, granular materials, and rigid objects in the simulation. The datasets do not include any dense particle information so most previous 3D-based intuitive physics pipelines can barely deal with that. We show our model can make long-horizon future predictions by learning from raw images and significantly outperforms models that do not employ an explicit 3D representation space. We also show that once trained, our model can achieve strong generalization in complex scenarios under extrapolate settings.
Bil-DOS: A Bi-lingual Dialogue Ordering System
Oct 11, 2022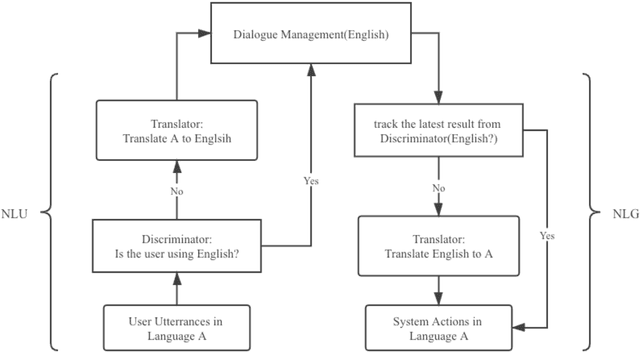
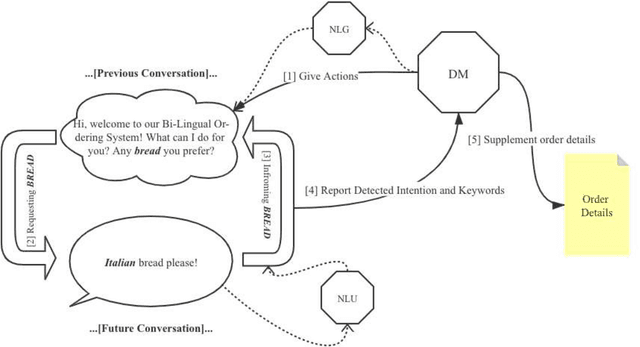

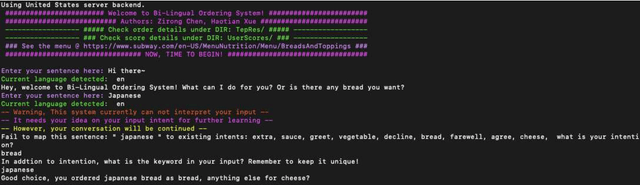
Due to the unfamiliarity to particular words(or proper nouns) for ingredients, non-native English speakers can be extremely confused about the ordering process in restaurants like Subway. Thus, We developed a dialogue system, which supports Chinese(Mandarin)1 and English2 at the same time. In other words, users can switch arbitrarily between Chinese(Mandarin) and English as the conversation is being conducted. This system is specifically designed for Subway ordering3. In BilDOS, we designed a Discriminator module to tell the language is being used in inputted user utterance, a Translator module to translate used language into English if it is not English, and a Dialogue Manager module to detect the intention within inputted user utterances, handle outlier inputs by throwing clarification requests, map detected Intention and detailed Keyword4 into a particular intention class, locate the current ordering process, continue to give queries to finish the order, conclude the order details once the order is completed, activate the evaluation process when the conversation is done.