 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysion++: Evaluating Physical Scene Understanding that Requires Online Inference of Different Physical Properties
Jun 27, 2023General physical scene understanding requires more than simply localizing and recognizing objects -- it requires knowledge that objects can have different latent properties (e.g., mass or elasticity), and that those properties affect the outcome of physical events. While there has been great progress in physical and video prediction models in recent years, benchmarks to test their performance typically do not require an understanding that objects have individual physical properties, or at best test only those properties that are directly observable (e.g., size or color). This work proposes a novel dataset and benchmark, termed Physion++, that rigorously evaluates visual physical prediction in artificial systems under circumstances where those predictions rely on accurate estimates of the latent physical properties of objects in the scene. Specifically, we test scenarios where accurate prediction relies on estimates of properties such as mass, friction, elasticity, and deformability, and where the values of those properties can only be inferred by observing how objects move and interact with other objects or fluids. We evaluate the performance of a number of state-of-the-art prediction models that span a variety of levels of learning vs. built-in knowledge, and compare that performance to a set of human predictions. We find that models that have been trained using standard regimes and datasets do not spontaneously learn to make inferences about latent properties, but also that models that encode objectness and physical states tend to make better predictions. However, there is still a huge gap between all models and human performance, and all models' predictions correlate poorly with those made by humans, suggesting that no state-of-the-art model is learning to make physical predictions in a human-like way. Project page: https://dingmyu.github.io/physion_v2/
3D-IntPhys: Towards More Generalized 3D-grounded Visual Intuitive Physics under Challenging Scenes
Apr 22, 2023



Given a visual scene, humans have strong intuitions about how a scene can evolve over time under given actions. The intuition, often termed visual intuitive physics, is a critical ability that allows us to make effective plans to manipulate the scene to achieve desired outcomes without relying on extensive trial and error. In this paper, we present a framework capable of learning 3D-grounded visual intuitive physics models from videos of complex scenes with fluids. Our method is composed of a conditional Neural Radiance Field (NeRF)-style visual frontend and a 3D point-based dynamics prediction backend, using which we can impose strong relational and structural inductive bias to capture the structure of the underlying environment. Unlike existing intuitive point-based dynamics works that rely on the supervision of dense point trajectory from simulators, we relax the requirements and only assume access to multi-view RGB images and (imperfect) instance masks acquired using color prior. This enables the proposed model to handle scenarios where accurate point estimation and tracking are hard or impossible. We generate datasets including three challenging scenarios involving fluid, granular materials, and rigid objects in the simulation. The datasets do not include any dense particle information so most previous 3D-based intuitive physics pipelines can barely deal with that. We show our model can make long-horizon future predictions by learning from raw images and significantly outperforms models that do not employ an explicit 3D representation space. We also show that once trained, our model can achieve strong generalization in complex scenarios under extrapolate settings.
Tactile-Filter: Interactive Tactile Perception for Part Mating
Mar 10, 2023Humans rely on touch and tactile sensing for a lot of dexterous manipulation tasks. Our tactile sensing provides us with a lot of information regarding contact formations as well as geometric information about objects during any interaction. With this motivation, vision-based tactile sensors are being widely used for various robotic perception and control tasks. In this paper, we present a method for interactive perception using vision-based tactile sensors for multi-object assembly. In particular, we are interested in tactile perception during part mating, where a robot can use tactile sensors and a feedback mechanism using particle filter to incrementally improve its estimate of objects that fit together for assembly. To do this, we first train a deep neural network that makes use of tactile images to predict the probabilistic correspondence between arbitrarily shaped objects that fit together. The trained model is used to design a particle filter which is used twofold. First, given one partial (or non-unique) observation of the hole, it incrementally improves the estimate of the correct peg by sampling more tactile observations. Second, it selects the next action for the robot to sample the next touch (and thus image) which results in maximum uncertainty reduction to minimize the number of interactions during the perception task. We evaluate our method on several part-mating tasks for assembly using a robot equipped with a vision-based tactile sensor. We also show the efficiency of the proposed action selection method against a naive method. See supplementary video at https://www.youtube.com/watch?v=jMVBg_e3gLw .
FluidLab: A Differentiable Environment for Benchmarking Complex Fluid Manipulation
Mar 04, 2023Humans manipulate various kinds of fluids in their everyday life: creating latte art, scooping floating objects from water, rolling an ice cream cone, etc. Using robots to augment or replace human labors in these daily settings remain as a challenging task due to the multifaceted complexities of fluids. Previous research in robotic fluid manipulation mostly consider fluids governed by an ideal, Newtonian model in simple task settings (e.g., pouring). However, the vast majority of real-world fluid systems manifest their complexities in terms of the fluid's complex material behaviors and multi-component interactions, both of which were well beyond the scope of the current literature. To evaluate robot learning algorithms on understanding and interacting with such complex fluid systems, a comprehensive virtual platform with versatile simulation capabilities and well-established tasks is needed. In this work, we introduce FluidLab, a simulation environment with a diverse set of manipulation tasks involving complex fluid dynamics. These tasks address interactions between solid and fluid as well as among multiple fluids. At the heart of our platform is a fully differentiable physics simulator, FluidEngine, providing GPU-accelerated simulations and gradient calculations for various material types and their couplings. We identify several challenges for fluid manipulation learning by evaluating a set of reinforcement learning and trajectory optimization methods on our platform. To address these challenges, we propose several domain-specific optimization schemes coupled with differentiable physics, which are empirically shown to be effective in tackling optimization problems featured by fluid system's non-convex and non-smooth properties. Furthermore, we demonstrate reasonable sim-to-real transfer by deploying optimized trajectories in real-world settings.
H-SAUR: Hypothesize, Simulate, Act, Update, and Repeat for Understanding Object Articulations from Interactions
Oct 22, 2022



The world is filled with articulated objects that are difficult to determine how to use from vision alone, e.g., a door might open inwards or outwards. Humans handle these objects with strategic trial-and-error: first pushing a door then pulling if that doesn't work. We enable these capabilities in autonomous agents by proposing "Hypothesize, Simulate, Act, Update, and Repeat" (H-SAUR), a probabilistic generative framework that simultaneously generates a distribution of hypotheses about how objects articulate given input observations, captures certainty over hypotheses over time, and infer plausible actions for exploration and goal-conditioned manipulation. We compare our model with existing work in manipulating objects after a handful of exploration actions, on the PartNet-Mobility dataset. We further propose a novel PuzzleBoxes benchmark that contains locked boxes that require multiple steps to solve. We show that the proposed model significantly outperforms the current state-of-the-art articulated object manipulation framework, despite using zero training data. We further improve the test-time efficiency of H-SAUR by integrating a learned prior from learning-based vision models.
HyperDynamics: Meta-Learning Object and Agent Dynamics with Hypernetworks
Mar 17, 2021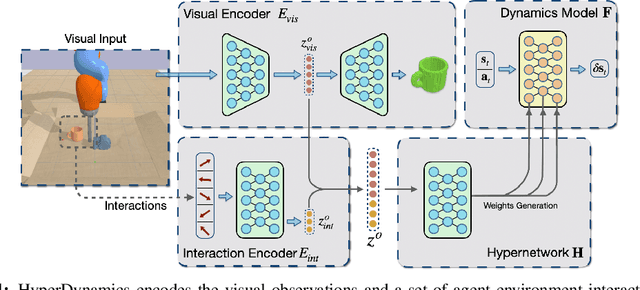
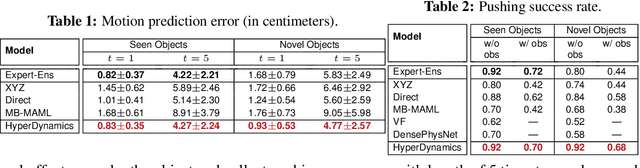
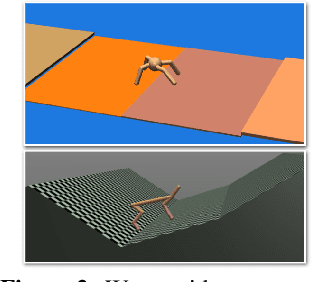

We propose HyperDynamics, a dynamics meta-learning framework that conditions on an agent's interactions with the environment and optionally its visual observations, and generates the parameters of neural dynamics models based on inferred properties of the dynamical system. Physical and visual properties of the environment that are not part of the low-dimensional state yet affect its temporal dynamics are inferred from the interaction history and visual observations, and are implicitly captured in the generated parameters. We test HyperDynamics on a set of object pushing and locomotion tasks. It outperforms existing dynamics models in the literature that adapt to environment variations by learning dynamics over high dimensional visual observations, capturing the interactions of the agent in recurrent state representations, or using gradient-based meta-optimization. We also show our method matches the performance of an ensemble of separately trained experts, while also being able to generalize well to unseen environment variations at test time. We attribute its good performance to the multiplicative interactions between the inferred system properties -- captured in the generated parameters -- and the low-dimensional state representation of the dynamical system.
Disentangling 3D Prototypical Networks For Few-Shot Concept Learning
Nov 06, 2020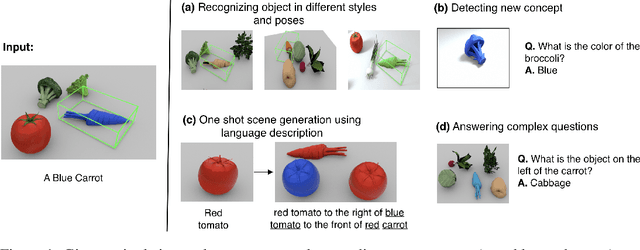
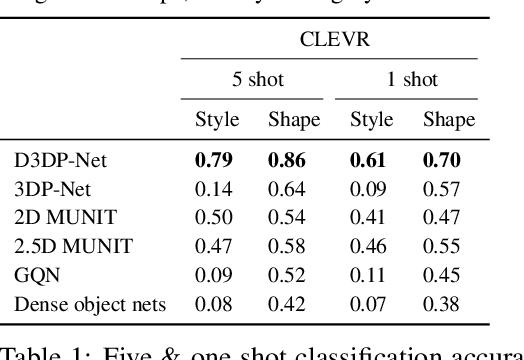
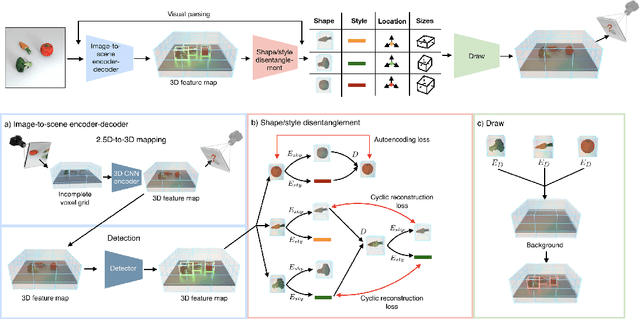
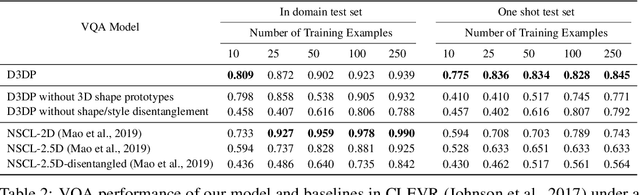
We present neural architectures that disentangle RGB-D images into objects' shapes and styles and a map of the background scene, and explore their applications for few-shot 3D object detection and few-shot concept classification. Our networks incorporate architectural biases that reflect the image formation process, 3D geometry of the world scene, and shape-style interplay. They are trained end-to-end self-supervised by predicting views in static scenes, alongside a small number of 3D object boxes. Objects and scenes are represented in terms of 3D feature grids in the bottleneck of the network. We show that the proposed 3D neural representations are compositional: they can generate novel 3D scene feature maps by mixing object shapes and styles, resizing and adding the resulting object 3D feature maps over background scene feature maps. We show that classifiers for object categories, color, materials, and spatial relationships trained over the disentangled 3D feature sub-spaces generalize better with dramatically fewer examples than the current state-of-the-art, and enable a visual question answering system that uses them as its modules to generalize one-shot to novel objects in the scene.
Generative Models and Model Criticism via Optimized Maximum Mean Discrepancy
Feb 10, 2017
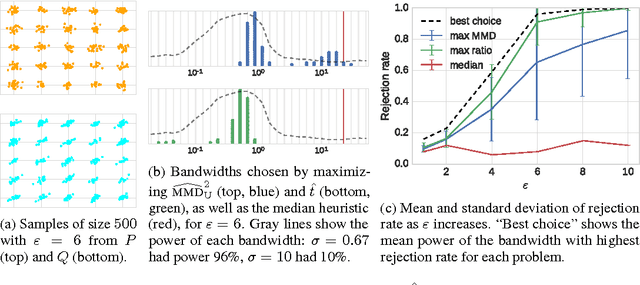
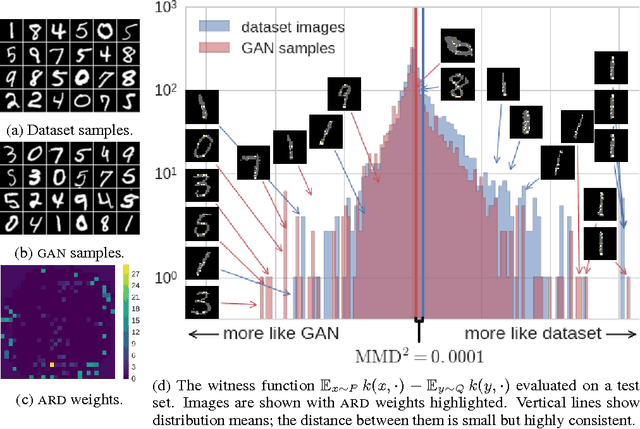

We propose a method to optimize the representation and distinguishability of samples from two probability distributions, by maximizing the estimated power of a statistical test based on the maximum mean discrepancy (MMD). This optimized MMD is applied to the setting of unsupervised learning by generative adversarial networks (GAN), in which a model attempts to generate realistic samples, and a discriminator attempts to tell these apart from data samples. In this context, the MMD may be used in two roles: first, as a discriminator, either directly on the samples, or on features of the samples. Second, the MMD can be used to evaluate the performance of a generative model, by testing the model's samples against a reference data set. In the latter role, the optimized MMD is particularly helpful, as it gives an interpretable indication of how the model and data distributions differ, even in cases where individual model samples are not easily distinguished either by eye or by classifier.
Fast and Guaranteed Tensor Decomposition via Sketching
Oct 20, 2015
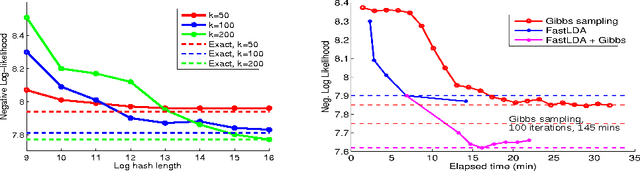

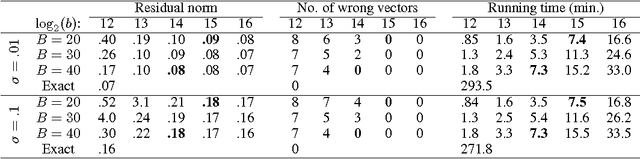
Tensor CANDECOMP/PARAFAC (CP) decomposition has wide applications in statistical learning of latent variable models and in data mining. In this paper, we propose fast and randomized tensor CP decomposition algorithms based on sketching. We build on the idea of count sketches, but introduce many novel ideas which are unique to tensors. We develop novel methods for randomized computation of tensor contractions via FFTs, without explicitly forming the tensors. Such tensor contractions are encountered in decomposition methods such as tensor power iterations and alternating least squares. We also design novel colliding hashes for symmetric tensors to further save time in computing the sketches. We then combine these sketching ideas with existing whitening and tensor power iterative techniques to obtain the fastest algorithm on both sparse and dense tensors. The quality of approximation under our method does not depend on properties such as sparsity, uniformity of elements, etc. We apply the method for topic modeling and obtain competitive results.