 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFreBIS: Frequency-Based Stratification for Neural Implicit Surface Representations
Apr 28, 2025Neural implicit surface representation techniques are in high demand for advancing technologies in augmented reality/virtual reality, digital twins, autonomous navigation, and many other fields. With their ability to model object surfaces in a scene as a continuous function, such techniques have made remarkable strides recently, especially over classical 3D surface reconstruction methods, such as those that use voxels or point clouds. However, these methods struggle with scenes that have varied and complex surfaces principally because they model any given scene with a single encoder network that is tasked to capture all of low through high-surface frequency information in the scene simultaneously. In this work, we propose a novel, neural implicit surface representation approach called FreBIS to overcome this challenge. FreBIS works by stratifying the scene based on the frequency of surfaces into multiple frequency levels, with each level (or a group of levels) encoded by a dedicated encoder. Moreover, FreBIS encourages these encoders to capture complementary information by promoting mutual dissimilarity of the encoded features via a novel, redundancy-aware weighting module. Empirical evaluations on the challenging BlendedMVS dataset indicate that replacing the standard encoder in an off-the-shelf neural surface reconstruction method with our frequency-stratified encoders yields significant improvements. These enhancements are evident both in the quality of the reconstructed 3D surfaces and in the fidelity of their renderings from any viewpoint.
Multimodal Diffusion Bridge with Attention-Based SAR Fusion for Satellite Image Cloud Removal
Apr 04, 2025Deep learning has achieved some success in addressing the challenge of cloud removal in optical satellite images, by fusing with synthetic aperture radar (SAR) images. Recently, diffusion models have emerged as powerful tools for cloud removal, delivering higher-quality estimation by sampling from cloud-free distributions, compared to earlier methods. However, diffusion models initiate sampling from pure Gaussian noise, which complicates the sampling trajectory and results in suboptimal performance. Also, current methods fall short in effectively fusing SAR and optical data. To address these limitations, we propose Diffusion Bridges for Cloud Removal, DB-CR, which directly bridges between the cloudy and cloud-free image distributions. In addition, we propose a novel multimodal diffusion bridge architecture with a two-branch backbone for multimodal image restoration, incorporating an efficient backbone and dedicated cross-modality fusion blocks to effectively extract and fuse features from synthetic aperture radar (SAR) and optical images. By formulating cloud removal as a diffusion-bridge problem and leveraging this tailored architecture, DB-CR achieves high-fidelity results while being computationally efficient. We evaluated DB-CR on the SEN12MS-CR cloud-removal dataset, demonstrating that it achieves state-of-the-art results.
Recovering Pulse Waves from Video Using Deep Unrolling and Deep Equilibrium Models
Mar 21, 2025Camera-based monitoring of vital signs, also known as imaging photoplethysmography (iPPG), has seen applications in driver-monitoring, perfusion assessment in surgical settings, affective computing, and more. iPPG involves sensing the underlying cardiac pulse from video of the skin and estimating vital signs such as the heart rate or a full pulse waveform. Some previous iPPG methods impose model-based sparse priors on the pulse signals and use iterative optimization for pulse wave recovery, while others use end-to-end black-box deep learning methods. In contrast, we introduce methods that combine signal processing and deep learning methods in an inverse problem framework. Our methods estimate the underlying pulse signal and heart rate from facial video by learning deep-network-based denoising operators that leverage deep algorithm unfolding and deep equilibrium models. Experiments show that our methods can denoise an acquired signal from the face and infer the correct underlying pulse rate, achieving state-of-the-art heart rate estimation performance on well-known benchmarks, all with less than one-fifth the number of learnable parameters as the closest competing method.
Time-Series U-Net with Recurrence for Noise-Robust Imaging Photoplethysmography
Mar 21, 2025Remote estimation of vital signs enables health monitoring for situations in which contact-based devices are either not available, too intrusive, or too expensive. In this paper, we present a modular, interpretable pipeline for pulse signal estimation from video of the face that achieves state-of-the-art results on publicly available datasets.Our imaging photoplethysmography (iPPG) system consists of three modules: face and landmark detection, time-series extraction, and pulse signal/pulse rate estimation. Unlike many deep learning methods that make use of a single black-box model that maps directly from input video to output signal or heart rate, our modular approach enables each of the three parts of the pipeline to be interpreted individually. The pulse signal estimation module, which we call TURNIP (Time-Series U-Net with Recurrence for Noise-Robust Imaging Photoplethysmography), allows the system to faithfully reconstruct the underlying pulse signal waveform and uses it to measure heart rate and pulse rate variability metrics, even in the presence of motion. When parts of the face are occluded due to extreme head poses, our system explicitly detects such "self-occluded" regions and maintains estimation robustness despite the missing information. Our algorithm provides reliable heart rate estimates without the need for specialized sensors or contact with the skin, outperforming previous iPPG methods on both color (RGB) and near-infrared (NIR) datasets.
Disentangled Acoustic Fields For Multimodal Physical Scene Understanding
Jul 16, 2024



We study the problem of multimodal physical scene understanding, where an embodied agent needs to find fallen objects by inferring object properties, direction, and distance of an impact sound source. Previous works adopt feed-forward neural networks to directly regress the variables from sound, leading to poor generalization and domain adaptation issues. In this paper, we illustrate that learning a disentangled model of acoustic formation, referred to as disentangled acoustic field (DAF), to capture the sound generation and propagation process, enables the embodied agent to construct a spatial uncertainty map over where the objects may have fallen. We demonstrate that our analysis-by-synthesis framework can jointly infer sound properties by explicitly decomposing and factorizing the latent space of the disentangled model. We further show that the spatial uncertainty map can significantly improve the success rate for the localization of fallen objects by proposing multiple plausible exploration locations.
TI2V-Zero: Zero-Shot Image Conditioning for Text-to-Video Diffusion Models
Apr 25, 2024



Text-conditioned image-to-video generation (TI2V) aims to synthesize a realistic video starting from a given image (e.g., a woman's photo) and a text description (e.g., "a woman is drinking water."). Existing TI2V frameworks often require costly training on video-text datasets and specific model designs for text and image conditioning. In this paper, we propose TI2V-Zero, a zero-shot, tuning-free method that empowers a pretrained text-to-video (T2V) diffusion model to be conditioned on a provided image, enabling TI2V generation without any optimization, fine-tuning, or introducing external modules. Our approach leverages a pretrained T2V diffusion foundation model as the generative prior. To guide video generation with the additional image input, we propose a "repeat-and-slide" strategy that modulates the reverse denoising process, allowing the frozen diffusion model to synthesize a video frame-by-frame starting from the provided image. To ensure temporal continuity, we employ a DDPM inversion strategy to initialize Gaussian noise for each newly synthesized frame and a resampling technique to help preserve visual details. We conduct comprehensive experiments on both domain-specific and open-domain datasets, where TI2V-Zero consistently outperforms a recent open-domain TI2V model. Furthermore, we show that TI2V-Zero can seamlessly extend to other tasks such as video infilling and prediction when provided with more images. Its autoregressive design also supports long video generation.
Steered Diffusion: A Generalized Framework for Plug-and-Play Conditional Image Synthesis
Sep 30, 2023
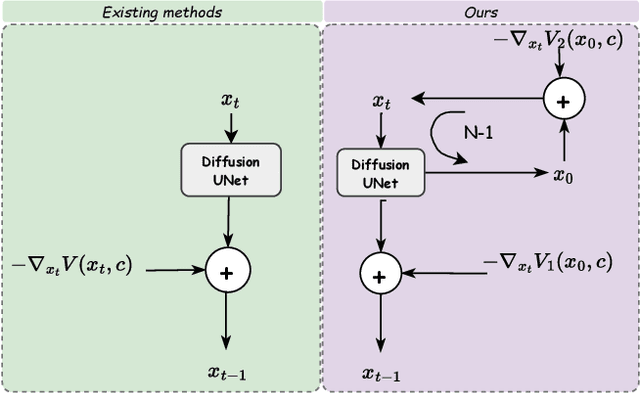
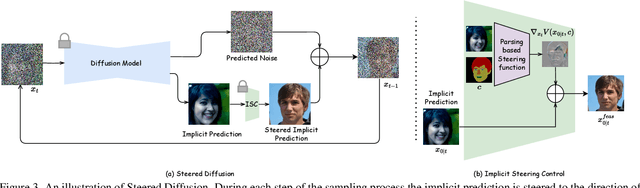
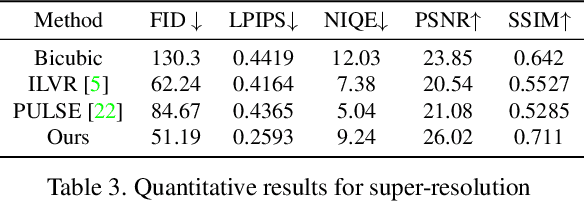
Conditional generative models typically demand large annotated training sets to achieve high-quality synthesis. As a result, there has been significant interest in designing models that perform plug-and-play generation, i.e., to use a predefined or pretrained model, which is not explicitly trained on the generative task, to guide the generative process (e.g., using language). However, such guidance is typically useful only towards synthesizing high-level semantics rather than editing fine-grained details as in image-to-image translation tasks. To this end, and capitalizing on the powerful fine-grained generative control offered by the recent diffusion-based generative models, we introduce Steered Diffusion, a generalized framework for photorealistic zero-shot conditional image generation using a diffusion model trained for unconditional generation. The key idea is to steer the image generation of the diffusion model at inference time via designing a loss using a pre-trained inverse model that characterizes the conditional task. This loss modulates the sampling trajectory of the diffusion process. Our framework allows for easy incorporation of multiple conditions during inference. We present experiments using steered diffusion on several tasks including inpainting, colorization, text-guided semantic editing, and image super-resolution. Our results demonstrate clear qualitative and quantitative improvements over state-of-the-art diffusion-based plug-and-play models while adding negligible additional computational cost.
H-SAUR: Hypothesize, Simulate, Act, Update, and Repeat for Understanding Object Articulations from Interactions
Oct 22, 2022



The world is filled with articulated objects that are difficult to determine how to use from vision alone, e.g., a door might open inwards or outwards. Humans handle these objects with strategic trial-and-error: first pushing a door then pulling if that doesn't work. We enable these capabilities in autonomous agents by proposing "Hypothesize, Simulate, Act, Update, and Repeat" (H-SAUR), a probabilistic generative framework that simultaneously generates a distribution of hypotheses about how objects articulate given input observations, captures certainty over hypotheses over time, and infer plausible actions for exploration and goal-conditioned manipulation. We compare our model with existing work in manipulating objects after a handful of exploration actions, on the PartNet-Mobility dataset. We further propose a novel PuzzleBoxes benchmark that contains locked boxes that require multiple steps to solve. We show that the proposed model significantly outperforms the current state-of-the-art articulated object manipulation framework, despite using zero training data. We further improve the test-time efficiency of H-SAUR by integrating a learned prior from learning-based vision models.
D Spatio-Temporal Scene Graphs for Video Question Answering
Feb 18, 2022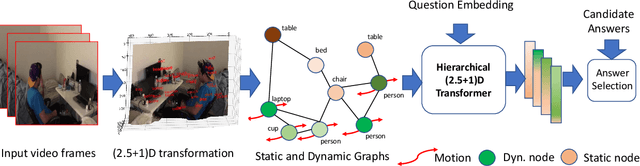
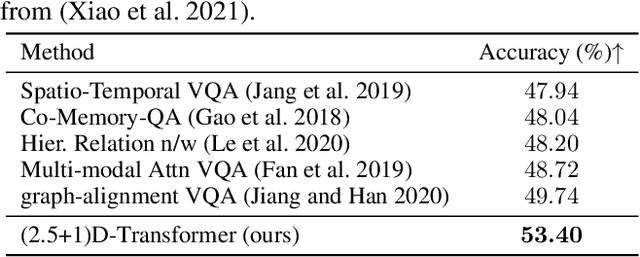
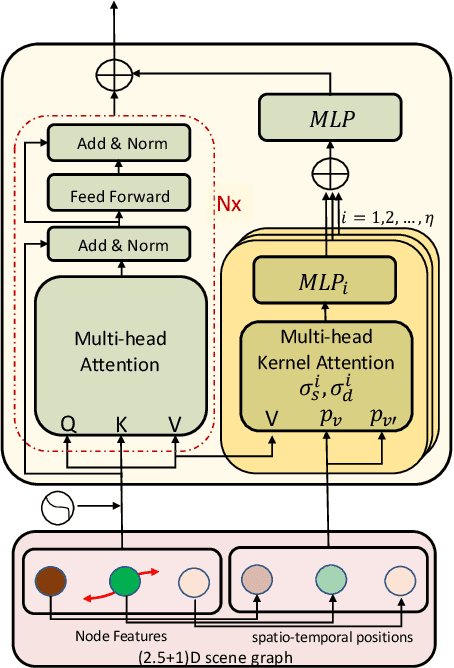
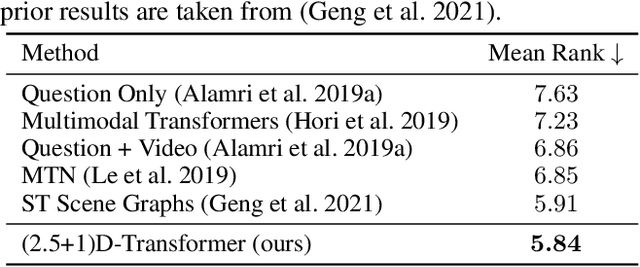
Spatio-temporal scene-graph approaches to video-based reasoning tasks such as video question-answering (QA) typically construct such graphs for every video frame. Such approaches often ignore the fact that videos are essentially sequences of 2D "views" of events happening in a 3D space, and that the semantics of the 3D scene can thus be carried over from frame to frame. Leveraging this insight, we propose a (2.5+1)D scene graph representation to better capture the spatio-temporal information flows inside the videos. Specifically, we first create a 2.5D (pseudo-3D) scene graph by transforming every 2D frame to have an inferred 3D structure using an off-the-shelf 2D-to-3D transformation module, following which we register the video frames into a shared (2.5+1)D spatio-temporal space and ground each 2D scene graph within it. Such a (2.5+1)D graph is then segregated into a static sub-graph and a dynamic sub-graph, corresponding to whether the objects within them usually move in the world. The nodes in the dynamic graph are enriched with motion features capturing their interactions with other graph nodes. Next, for the video QA task, we present a novel transformer-based reasoning pipeline that embeds the (2.5+1)D graph into a spatio-temporal hierarchical latent space, where the sub-graphs and their interactions are captured at varied granularity. To demonstrate the effectiveness of our approach, we present experiments on the NExT-QA and AVSD-QA datasets. Our results show that our proposed (2.5+1)D representation leads to faster training and inference, while our hierarchical model showcases superior performance on the video QA task versus the state of the art.
MOST-GAN: 3D Morphable StyleGAN for Disentangled Face Image Manipulation
Nov 01, 2021

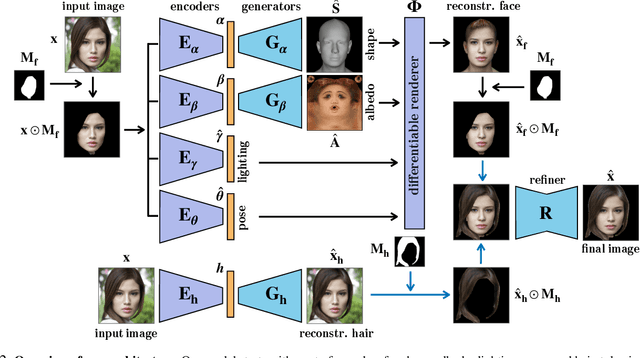

Recent advances in generative adversarial networks (GANs) have led to remarkable achievements in face image synthesis. While methods that use style-based GANs can generate strikingly photorealistic face images, it is often difficult to control the characteristics of the generated faces in a meaningful and disentangled way. Prior approaches aim to achieve such semantic control and disentanglement within the latent space of a previously trained GAN. In contrast, we propose a framework that a priori models physical attributes of the face such as 3D shape, albedo, pose, and lighting explicitly, thus providing disentanglement by design. Our method, MOST-GAN, integrates the expressive power and photorealism of style-based GANs with the physical disentanglement and flexibility of nonlinear 3D morphable models, which we couple with a state-of-the-art 2D hair manipulation network. MOST-GAN achieves photorealistic manipulation of portrait images with fully disentangled 3D control over their physical attributes, enabling extreme manipulation of lighting, facial expression, and pose variations up to full profile view.