 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScale-Wise VAR is Secretly Discrete Diffusion
Sep 26, 2025Autoregressive (AR) transformers have emerged as a powerful paradigm for visual generation, largely due to their scalability, computational efficiency and unified architecture with language and vision. Among them, next scale prediction Visual Autoregressive Generation (VAR) has recently demonstrated remarkable performance, even surpassing diffusion-based models. In this work, we revisit VAR and uncover a theoretical insight: when equipped with a Markovian attention mask, VAR is mathematically equivalent to a discrete diffusion. We term this reinterpretation as Scalable Visual Refinement with Discrete Diffusion (SRDD), establishing a principled bridge between AR transformers and diffusion models. Leveraging this new perspective, we show how one can directly import the advantages of diffusion such as iterative refinement and reduce architectural inefficiencies into VAR, yielding faster convergence, lower inference cost, and improved zero-shot reconstruction. Across multiple datasets, we show that the diffusion based perspective of VAR leads to consistent gains in efficiency and generation.
Scaling Transformer-Based Novel View Synthesis Models with Token Disentanglement and Synthetic Data
Sep 08, 2025Large transformer-based models have made significant progress in generalizable novel view synthesis (NVS) from sparse input views, generating novel viewpoints without the need for test-time optimization. However, these models are constrained by the limited diversity of publicly available scene datasets, making most real-world (in-the-wild) scenes out-of-distribution. To overcome this, we incorporate synthetic training data generated from diffusion models, which improves generalization across unseen domains. While synthetic data offers scalability, we identify artifacts introduced during data generation as a key bottleneck affecting reconstruction quality. To address this, we propose a token disentanglement process within the transformer architecture, enhancing feature separation and ensuring more effective learning. This refinement not only improves reconstruction quality over standard transformers but also enables scalable training with synthetic data. As a result, our method outperforms existing models on both in-dataset and cross-dataset evaluations, achieving state-of-the-art results across multiple benchmarks while significantly reducing computational costs. Project page: https://scaling3dnvs.github.io/
PETALface: Parameter Efficient Transfer Learning for Low-resolution Face Recognition
Dec 10, 2024



Pre-training on large-scale datasets and utilizing margin-based loss functions have been highly successful in training models for high-resolution face recognition. However, these models struggle with low-resolution face datasets, in which the faces lack the facial attributes necessary for distinguishing different faces. Full fine-tuning on low-resolution datasets, a naive method for adapting the model, yields inferior performance due to catastrophic forgetting of pre-trained knowledge. Additionally the domain difference between high-resolution (HR) gallery images and low-resolution (LR) probe images in low resolution datasets leads to poor convergence for a single model to adapt to both gallery and probe after fine-tuning. To this end, we propose PETALface, a Parameter-Efficient Transfer Learning approach for low-resolution face recognition. Through PETALface, we attempt to solve both the aforementioned problems. (1) We solve catastrophic forgetting by leveraging the power of parameter efficient fine-tuning(PEFT). (2) We introduce two low-rank adaptation modules to the backbone, with weights adjusted based on the input image quality to account for the difference in quality for the gallery and probe images. To the best of our knowledge, PETALface is the first work leveraging the powers of PEFT for low resolution face recognition. Extensive experiments demonstrate that the proposed method outperforms full fine-tuning on low-resolution datasets while preserving performance on high-resolution and mixed-quality datasets, all while using only 0.48% of the parameters. Code: https://kartik-3004.github.io/PETALface/
GenDeg: Diffusion-Based Degradation Synthesis for Generalizable All-in-One Image Restoration
Nov 26, 2024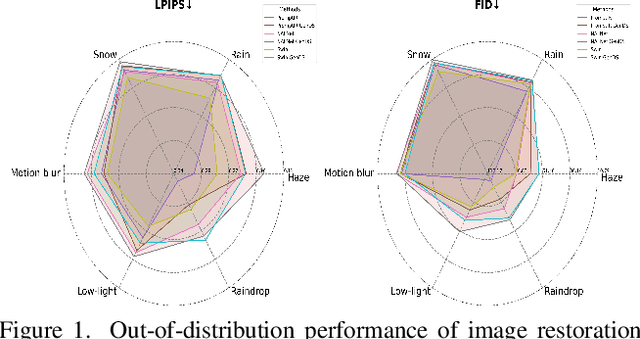
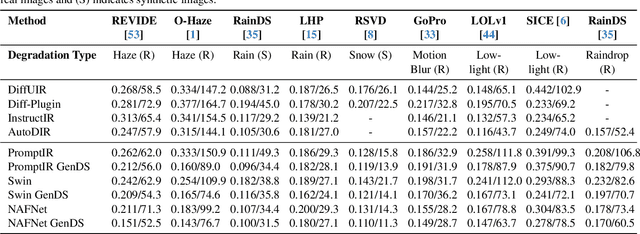
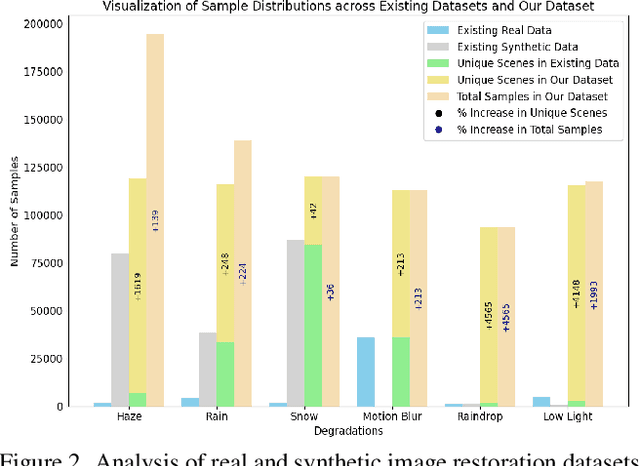
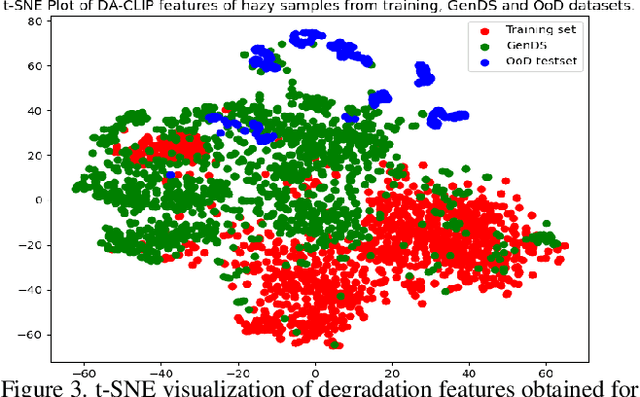
Deep learning-based models for All-In-One Image Restoration (AIOR) have achieved significant advancements in recent years. However, their practical applicability is limited by poor generalization to samples outside the training distribution. This limitation arises primarily from insufficient diversity in degradation variations and scenes within existing datasets, resulting in inadequate representations of real-world scenarios. Additionally, capturing large-scale real-world paired data for degradations such as haze, low-light, and raindrops is often cumbersome and sometimes infeasible. In this paper, we leverage the generative capabilities of latent diffusion models to synthesize high-quality degraded images from their clean counterparts. Specifically, we introduce GenDeg, a degradation and intensity-aware conditional diffusion model capable of producing diverse degradation patterns on clean images. Using GenDeg, we synthesize over 550k samples across six degradation types: haze, rain, snow, motion blur, low-light, and raindrops. These generated samples are integrated with existing datasets to form the GenDS dataset, comprising over 750k samples. Our experiments reveal that image restoration models trained on the GenDS dataset exhibit significant improvements in out-of-distribution performance compared to those trained solely on existing datasets. Furthermore, we provide comprehensive analyses on the implications of diffusion model-based synthetic degradations for AIOR. The code will be made publicly available.
Dreamguider: Improved Training free Diffusion-based Conditional Generation
Jun 04, 2024
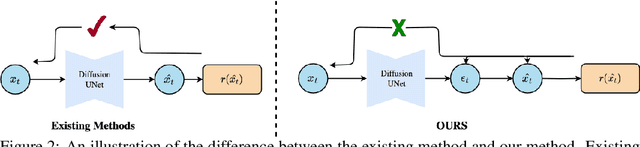

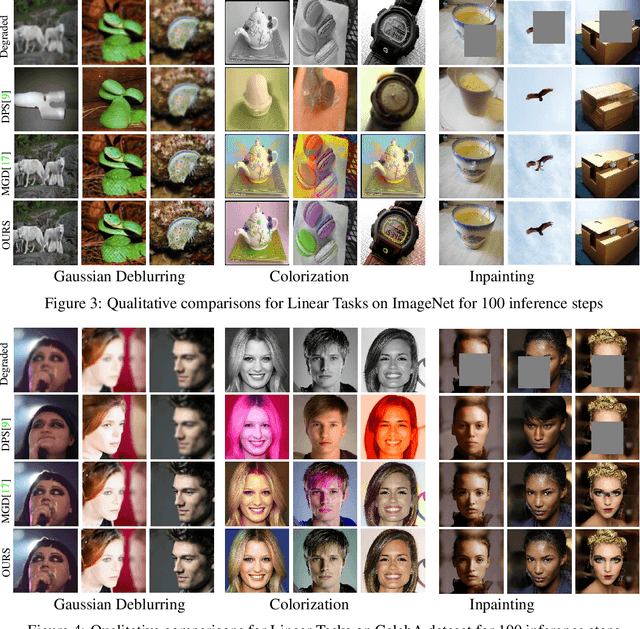
Diffusion models have emerged as a formidable tool for training-free conditional generation.However, a key hurdle in inference-time guidance techniques is the need for compute-heavy backpropagation through the diffusion network for estimating the guidance direction. Moreover, these techniques often require handcrafted parameter tuning on a case-by-case basis. Although some recent works have introduced minimal compute methods for linear inverse problems, a generic lightweight guidance solution to both linear and non-linear guidance problems is still missing. To this end, we propose Dreamguider, a method that enables inference-time guidance without compute-heavy backpropagation through the diffusion network. The key idea is to regulate the gradient flow through a time-varying factor. Moreover, we propose an empirical guidance scale that works for a wide variety of tasks, hence removing the need for handcrafted parameter tuning. We further introduce an effective lightweight augmentation strategy that significantly boosts the performance during inference-time guidance. We present experiments using Dreamguider on multiple tasks across multiple datasets and models to show the effectiveness of the proposed modules. To facilitate further research, we will make the code public after the review process.
Diffscaler: Enhancing the Generative Prowess of Diffusion Transformers
Apr 15, 2024Recently, diffusion transformers have gained wide attention with its excellent performance in text-to-image and text-to-vidoe models, emphasizing the need for transformers as backbone for diffusion models. Transformer-based models have shown better generalization capability compared to CNN-based models for general vision tasks. However, much less has been explored in the existing literature regarding the capabilities of transformer-based diffusion backbones and expanding their generative prowess to other datasets. This paper focuses on enabling a single pre-trained diffusion transformer model to scale across multiple datasets swiftly, allowing for the completion of diverse generative tasks using just one model. To this end, we propose DiffScaler, an efficient scaling strategy for diffusion models where we train a minimal amount of parameters to adapt to different tasks. In particular, we learn task-specific transformations at each layer by incorporating the ability to utilize the learned subspaces of the pre-trained model, as well as the ability to learn additional task-specific subspaces, which may be absent in the pre-training dataset. As these parameters are independent, a single diffusion model with these task-specific parameters can be used to perform multiple tasks simultaneously. Moreover, we find that transformer-based diffusion models significantly outperform CNN-based diffusion models methods while performing fine-tuning over smaller datasets. We perform experiments on four unconditional image generation datasets. We show that using our proposed method, a single pre-trained model can scale up to perform these conditional and unconditional tasks, respectively, with minimal parameter tuning while performing as close as fine-tuning an entire diffusion model for that particular task.
MaxFusion: Plug&Play Multi-Modal Generation in Text-to-Image Diffusion Models
Apr 15, 2024



Large diffusion-based Text-to-Image (T2I) models have shown impressive generative powers for text-to-image generation as well as spatially conditioned image generation. For most applications, we can train the model end-toend with paired data to obtain photorealistic generation quality. However, to add an additional task, one often needs to retrain the model from scratch using paired data across all modalities to retain good generation performance. In this paper, we tackle this issue and propose a novel strategy to scale a generative model across new tasks with minimal compute. During our experiments, we discovered that the variance maps of intermediate feature maps of diffusion models capture the intensity of conditioning. Utilizing this prior information, we propose MaxFusion, an efficient strategy to scale up text-to-image generation models to accommodate new modality conditions. Specifically, we combine aligned features of multiple models, hence bringing a compositional effect. Our fusion strategy can be integrated into off-the-shelf models to enhance their generative prowess.
Steered Diffusion: A Generalized Framework for Plug-and-Play Conditional Image Synthesis
Sep 30, 2023
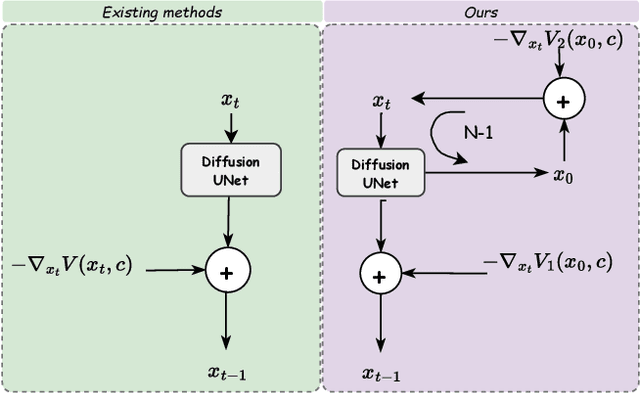
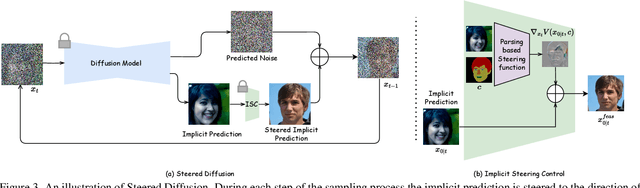
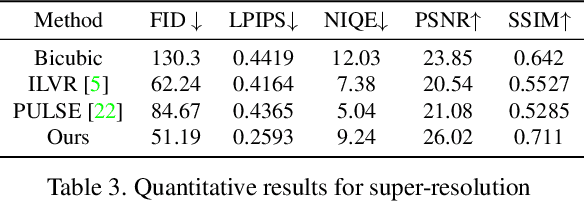
Conditional generative models typically demand large annotated training sets to achieve high-quality synthesis. As a result, there has been significant interest in designing models that perform plug-and-play generation, i.e., to use a predefined or pretrained model, which is not explicitly trained on the generative task, to guide the generative process (e.g., using language). However, such guidance is typically useful only towards synthesizing high-level semantics rather than editing fine-grained details as in image-to-image translation tasks. To this end, and capitalizing on the powerful fine-grained generative control offered by the recent diffusion-based generative models, we introduce Steered Diffusion, a generalized framework for photorealistic zero-shot conditional image generation using a diffusion model trained for unconditional generation. The key idea is to steer the image generation of the diffusion model at inference time via designing a loss using a pre-trained inverse model that characterizes the conditional task. This loss modulates the sampling trajectory of the diffusion process. Our framework allows for easy incorporation of multiple conditions during inference. We present experiments using steered diffusion on several tasks including inpainting, colorization, text-guided semantic editing, and image super-resolution. Our results demonstrate clear qualitative and quantitative improvements over state-of-the-art diffusion-based plug-and-play models while adding negligible additional computational cost.
AdaptiveSAM: Towards Efficient Tuning of SAM for Surgical Scene Segmentation
Aug 07, 2023Segmentation is a fundamental problem in surgical scene analysis using artificial intelligence. However, the inherent data scarcity in this domain makes it challenging to adapt traditional segmentation techniques for this task. To tackle this issue, current research employs pretrained models and finetunes them on the given data. Even so, these require training deep networks with millions of parameters every time new data becomes available. A recently published foundation model, Segment-Anything (SAM), generalizes well to a large variety of natural images, hence tackling this challenge to a reasonable extent. However, SAM does not generalize well to the medical domain as is without utilizing a large amount of compute resources for fine-tuning and using task-specific prompts. Moreover, these prompts are in the form of bounding-boxes or foreground/background points that need to be annotated explicitly for every image, making this solution increasingly tedious with higher data size. In this work, we propose AdaptiveSAM - an adaptive modification of SAM that can adjust to new datasets quickly and efficiently, while enabling text-prompted segmentation. For finetuning AdaptiveSAM, we propose an approach called bias-tuning that requires a significantly smaller number of trainable parameters than SAM (less than 2\%). At the same time, AdaptiveSAM requires negligible expert intervention since it uses free-form text as prompt and can segment the object of interest with just the label name as prompt. Our experiments show that AdaptiveSAM outperforms current state-of-the-art methods on various medical imaging datasets including surgery, ultrasound and X-ray. Code is available at https://github.com/JayParanjape/biastuning
Diffuse-Denoise-Count: Accurate Crowd-Counting with Diffusion Models
Mar 22, 2023Crowd counting is a key aspect of crowd analysis and has been typically accomplished by estimating a crowd-density map and summing over the density values. However, this approach suffers from background noise accumulation and loss of density due to the use of broad Gaussian kernels to create the ground truth density maps. This issue can be overcome by narrowing the Gaussian kernel. However, existing approaches perform poorly when trained with such ground truth density maps. To overcome this limitation, we propose using conditional diffusion models to predict density maps, as diffusion models are known to model complex distributions well and show high fidelity to training data during crowd-density map generation. Furthermore, as the intermediate time steps of the diffusion process are noisy, we incorporate a regression branch for direct crowd estimation only during training to improve the feature learning. In addition, owing to the stochastic nature of the diffusion model, we introduce producing multiple density maps to improve the counting performance contrary to the existing crowd counting pipelines. Further, we also differ from the density summation and introduce contour detection followed by summation as the counting operation, which is more immune to background noise. We conduct extensive experiments on public datasets to validate the effectiveness of our method. Specifically, our novel crowd-counting pipeline improves the error of crowd-counting by up to $6\%$ on JHU-CROWD++ and up to $7\%$ on UCF-QNRF.