 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYour Pre-trained Diffusion Model Secretly Knows Restoration
Apr 06, 2026Pre-trained diffusion models have enabled significant advancements in All-in-One Restoration (AiOR), offering improved perceptual quality and generalization. However, diffusion-based restoration methods primarily rely on fine-tuning or Control-Net style modules to leverage the pre-trained diffusion model's priors for AiOR. In this work, we show that these pre-trained diffusion models inherently possess restoration behavior, which can be unlocked by directly learning prompt embeddings at the output of the text encoder. Interestingly, this behavior is largely inaccessible through text prompts and text-token embedding optimization. Furthermore, we observe that naive prompt learning is unstable because the forward noising process using degraded images is misaligned with the reverse sampling trajectory. To resolve this, we train prompts within a diffusion bridge formulation that aligns training and inference dynamics, enforcing a coherent denoising path from noisy degraded states to clean images. Building on these insights, we introduce our lightweight learned prompts on the pre-trained WAN video model and FLUX image models, converting them into high-performing restoration models. Extensive experiments demonstrate that our approach achieves competitive performance and generalization across diverse degradations, while avoiding fine-tuning and restoration-specific control modules.
RestoreVAR: Visual Autoregressive Generation for All-in-One Image Restoration
May 23, 2025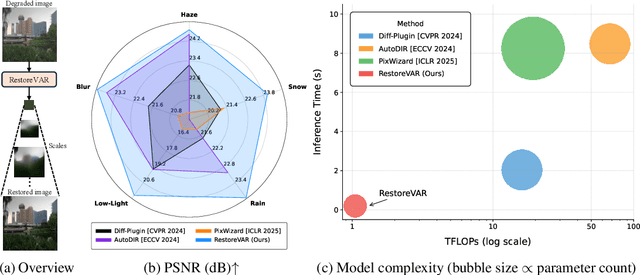
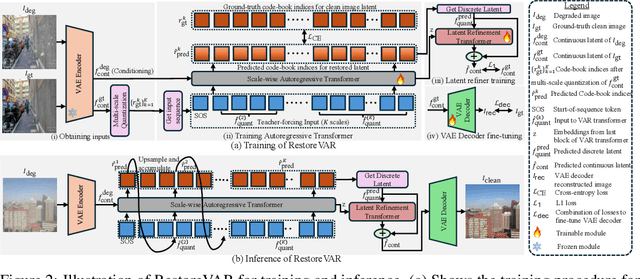
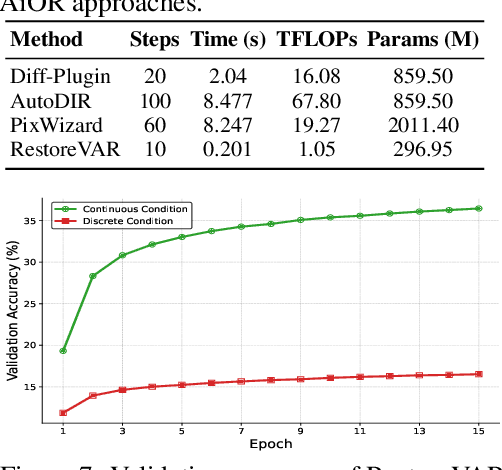
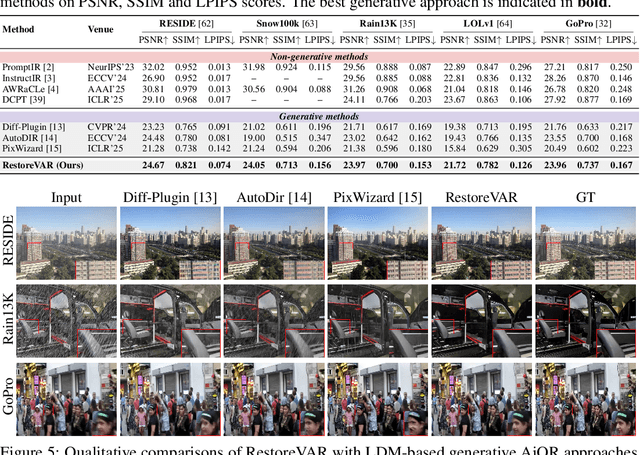
The use of latent diffusion models (LDMs) such as Stable Diffusion has significantly improved the perceptual quality of All-in-One image Restoration (AiOR) methods, while also enhancing their generalization capabilities. However, these LDM-based frameworks suffer from slow inference due to their iterative denoising process, rendering them impractical for time-sensitive applications. To address this, we propose RestoreVAR, a novel generative approach for AiOR that significantly outperforms LDM-based models in restoration performance while achieving over $\mathbf{10\times}$ faster inference. RestoreVAR leverages visual autoregressive modeling (VAR), a recently introduced approach which performs scale-space autoregression for image generation. VAR achieves comparable performance to that of state-of-the-art diffusion transformers with drastically reduced computational costs. To optimally exploit these advantages of VAR for AiOR, we propose architectural modifications and improvements, including intricately designed cross-attention mechanisms and a latent-space refinement module, tailored for the AiOR task. Extensive experiments show that RestoreVAR achieves state-of-the-art performance among generative AiOR methods, while also exhibiting strong generalization capabilities.
SINR: Sparsity Driven Compressed Implicit Neural Representations
Mar 25, 2025



Implicit Neural Representations (INRs) are increasingly recognized as a versatile data modality for representing discretized signals, offering benefits such as infinite query resolution and reduced storage requirements. Existing signal compression approaches for INRs typically employ one of two strategies: 1. direct quantization with entropy coding of the trained INR; 2. deriving a latent code on top of the INR through a learnable transformation. Thus, their performance is heavily dependent on the quantization and entropy coding schemes employed. In this paper, we introduce SINR, an innovative compression algorithm that leverages the patterns in the vector spaces formed by weights of INRs. We compress these vector spaces using a high-dimensional sparse code within a dictionary. Further analysis reveals that the atoms of the dictionary used to generate the sparse code do not need to be learned or transmitted to successfully recover the INR weights. We demonstrate that the proposed approach can be integrated with any existing INR-based signal compression technique. Our results indicate that SINR achieves substantial reductions in storage requirements for INRs across various configurations, outperforming conventional INR-based compression baselines. Furthermore, SINR maintains high-quality decoding across diverse data modalities, including images, occupancy fields, and Neural Radiance Fields.
GenDeg: Diffusion-Based Degradation Synthesis for Generalizable All-in-One Image Restoration
Nov 26, 2024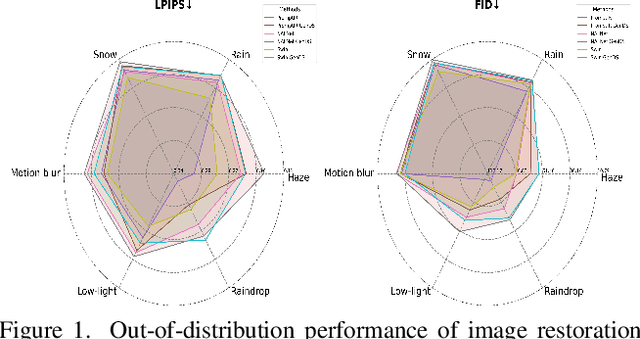
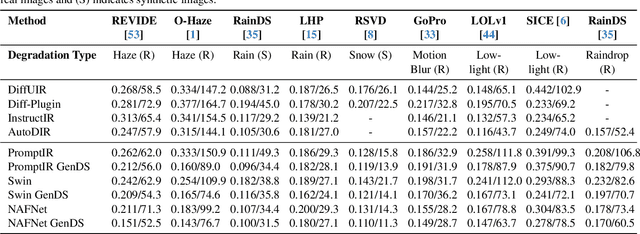
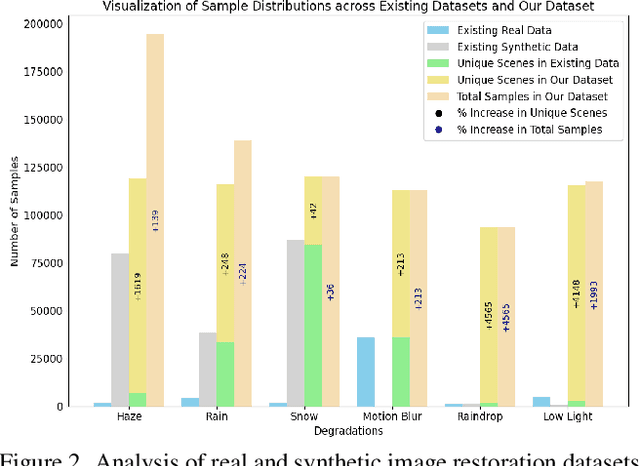
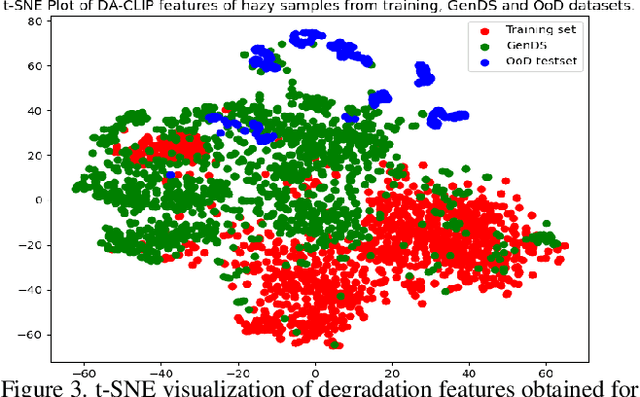
Deep learning-based models for All-In-One Image Restoration (AIOR) have achieved significant advancements in recent years. However, their practical applicability is limited by poor generalization to samples outside the training distribution. This limitation arises primarily from insufficient diversity in degradation variations and scenes within existing datasets, resulting in inadequate representations of real-world scenarios. Additionally, capturing large-scale real-world paired data for degradations such as haze, low-light, and raindrops is often cumbersome and sometimes infeasible. In this paper, we leverage the generative capabilities of latent diffusion models to synthesize high-quality degraded images from their clean counterparts. Specifically, we introduce GenDeg, a degradation and intensity-aware conditional diffusion model capable of producing diverse degradation patterns on clean images. Using GenDeg, we synthesize over 550k samples across six degradation types: haze, rain, snow, motion blur, low-light, and raindrops. These generated samples are integrated with existing datasets to form the GenDS dataset, comprising over 750k samples. Our experiments reveal that image restoration models trained on the GenDS dataset exhibit significant improvements in out-of-distribution performance compared to those trained solely on existing datasets. Furthermore, we provide comprehensive analyses on the implications of diffusion model-based synthetic degradations for AIOR. The code will be made publicly available.
Low-rank Adaptation-based All-Weather Removal for Autonomous Navigation
Nov 26, 2024All-weather image restoration (AWIR) is crucial for reliable autonomous navigation under adverse weather conditions. AWIR models are trained to address a specific set of weather conditions such as fog, rain, and snow. But this causes them to often struggle with out-of-distribution (OoD) samples or unseen degradations which limits their effectiveness for real-world autonomous navigation. To overcome this issue, existing models must either be retrained or fine-tuned, both of which are inefficient and impractical, with retraining needing access to large datasets, and fine-tuning involving many parameters. In this paper, we propose using Low-Rank Adaptation (LoRA) to efficiently adapt a pre-trained all-weather model to novel weather restoration tasks. Furthermore, we observe that LoRA lowers the performance of the adapted model on the pre-trained restoration tasks. To address this issue, we introduce a LoRA-based fine-tuning method called LoRA-Align (LoRA-A) which seeks to align the singular vectors of the fine-tuned and pre-trained weight matrices using Singular Value Decomposition (SVD). This alignment helps preserve the model's knowledge of its original tasks while adapting it to unseen tasks. We show that images restored with LoRA and LoRA-A can be effectively used for computer vision tasks in autonomous navigation, such as semantic segmentation and depth estimation.
AWRaCLe: All-Weather Image Restoration using Visual In-Context Learning
Aug 30, 2024



All-Weather Image Restoration (AWIR) under adverse weather conditions is a challenging task due to the presence of different types of degradations. Prior research in this domain relies on extensive training data but lacks the utilization of additional contextual information for restoration guidance. Consequently, the performance of existing methods is limited by the degradation cues that are learnt from individual training samples. Recent advancements in visual in-context learning have introduced generalist models that are capable of addressing multiple computer vision tasks simultaneously by using the information present in the provided context as a prior. In this paper, we propose All-Weather Image Restoration using Visual In-Context Learning (AWRaCLe), a novel approach for AWIR that innovatively utilizes degradation-specific visual context information to steer the image restoration process. To achieve this, AWRaCLe incorporates Degradation Context Extraction (DCE) and Context Fusion (CF) to seamlessly integrate degradation-specific features from the context into an image restoration network. The proposed DCE and CF blocks leverage CLIP features and incorporate attention mechanisms to adeptly learn and fuse contextual information. These blocks are specifically designed for visual in-context learning under all-weather conditions and are crucial for effective context utilization. Through extensive experiments, we demonstrate the effectiveness of AWRaCLe for all-weather restoration and show that our method advances the state-of-the-art in AWIR.
Remote Task-oriented Grasp Area Teaching By Non-Experts through Interactive Segmentation and Few-Shot Learning
Mar 17, 2023



A robot operating in unstructured environments must be able to discriminate between different grasping styles depending on the prospective manipulation task. Having a system that allows learning from remote non-expert demonstrations can very feasibly extend the cognitive skills of a robot for task-oriented grasping. We propose a novel two-step framework towards this aim. The first step involves grasp area estimation by segmentation. We receive grasp area demonstrations for a new task via interactive segmentation, and learn from these few demonstrations to estimate the required grasp area on an unseen scene for the given task. The second step is autonomous grasp estimation in the segmented region. To train the segmentation network for few-shot learning, we built a grasp area segmentation (GAS) dataset with 10089 images grouped into 1121 segmentation tasks. We benefit from an efficient meta learning algorithm for training for few-shot adaptation. Experimental evaluation showed that our method successfully detects the correct grasp area on the respective objects in unseen test scenes and effectively allows remote teaching of new grasp strategies by non-experts.
Spectrum-inspired Low-light Image Translation for Saliency Detection
Mar 17, 2023

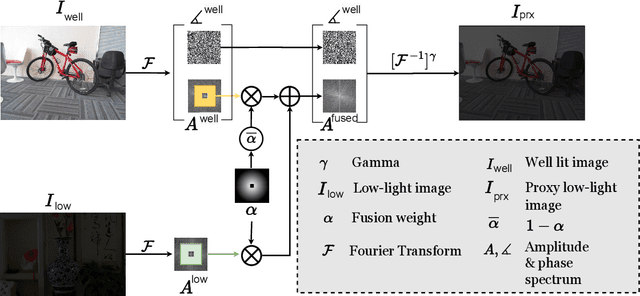

Saliency detection methods are central to several real-world applications such as robot navigation and satellite imagery. However, the performance of existing methods deteriorate under low-light conditions because training datasets mostly comprise of well-lit images. One possible solution is to collect a new dataset for low-light conditions. This involves pixel-level annotations, which is not only tedious and time-consuming but also infeasible if a huge training corpus is required. We propose a technique that performs classical band-pass filtering in the Fourier space to transform well-lit images to low-light images and use them as a proxy for real low-light images. Unlike popular deep learning approaches which require learning thousands of parameters and enormous amounts of training data, the proposed transformation is fast and simple and easy to extend to other tasks such as low-light depth estimation. Our experiments show that the state-of-the-art saliency detection and depth estimation networks trained on our proxy low-light images perform significantly better on real low-light images than networks trained using existing strategies.