 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSINR: Sparsity Driven Compressed Implicit Neural Representations
Mar 25, 2025



Implicit Neural Representations (INRs) are increasingly recognized as a versatile data modality for representing discretized signals, offering benefits such as infinite query resolution and reduced storage requirements. Existing signal compression approaches for INRs typically employ one of two strategies: 1. direct quantization with entropy coding of the trained INR; 2. deriving a latent code on top of the INR through a learnable transformation. Thus, their performance is heavily dependent on the quantization and entropy coding schemes employed. In this paper, we introduce SINR, an innovative compression algorithm that leverages the patterns in the vector spaces formed by weights of INRs. We compress these vector spaces using a high-dimensional sparse code within a dictionary. Further analysis reveals that the atoms of the dictionary used to generate the sparse code do not need to be learned or transmitted to successfully recover the INR weights. We demonstrate that the proposed approach can be integrated with any existing INR-based signal compression technique. Our results indicate that SINR achieves substantial reductions in storage requirements for INRs across various configurations, outperforming conventional INR-based compression baselines. Furthermore, SINR maintains high-quality decoding across diverse data modalities, including images, occupancy fields, and Neural Radiance Fields.
Deep filter bank regression for super-resolution of anisotropic MR brain images
Sep 06, 2022
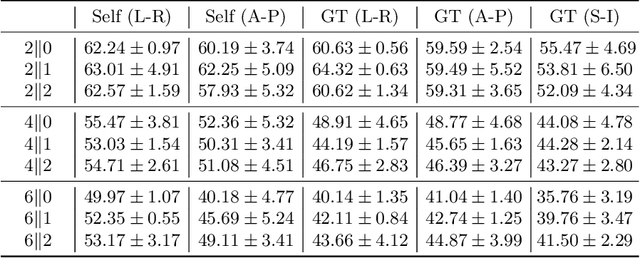
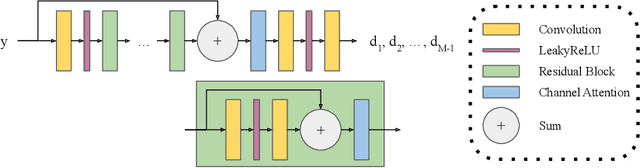

In 2D multi-slice magnetic resonance (MR) acquisition, the through-plane signals are typically of lower resolution than the in-plane signals. While contemporary super-resolution (SR) methods aim to recover the underlying high-resolution volume, the estimated high-frequency information is implicit via end-to-end data-driven training rather than being explicitly stated and sought. To address this, we reframe the SR problem statement in terms of perfect reconstruction filter banks, enabling us to identify and directly estimate the missing information. In this work, we propose a two-stage approach to approximate the completion of a perfect reconstruction filter bank corresponding to the anisotropic acquisition of a particular scan. In stage 1, we estimate the missing filters using gradient descent and in stage 2, we use deep networks to learn the mapping from coarse coefficients to detail coefficients. In addition, the proposed formulation does not rely on external training data, circumventing the need for domain shift correction. Under our approach, SR performance is improved particularly in "slice gap" scenarios, likely due to the constrained solution space imposed by the framework.
Approximate Message Passing with Parameter Estimation for Heavily Quantized Measurements
May 20, 2022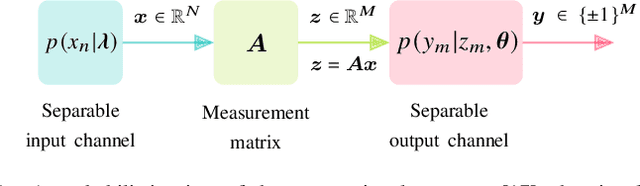
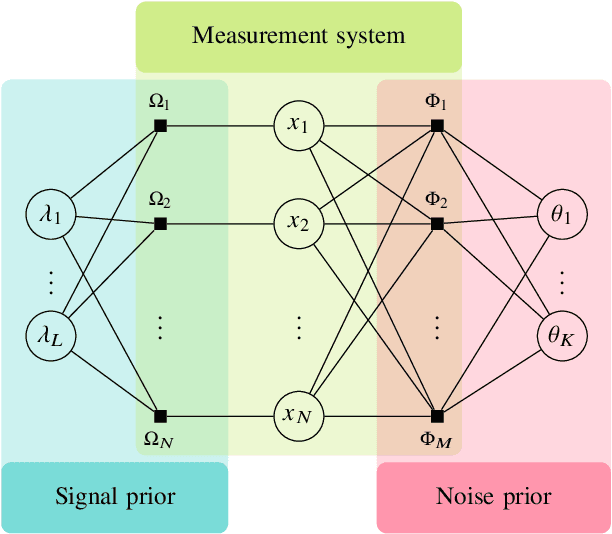
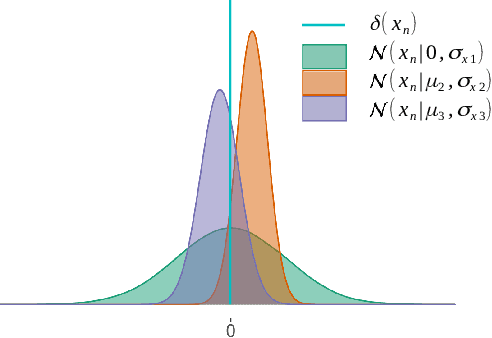
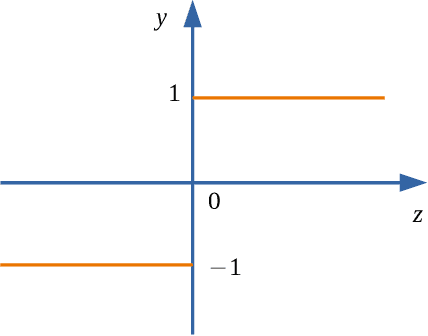
Designing efficient sparse recovery algorithms that could handle noisy quantized measurements is important in a variety of applications -- from radar to source localization, spectrum sensing and wireless networking. We take advantage of the approximate message passing (AMP) framework to achieve this goal given its high computational efficiency and state-of-the-art performance. In AMP, the signal of interest is assumed to follow certain prior distribution with unknown parameters. Previous works focused on finding the parameters that maximize the measurement likelihood via expectation maximization -- an increasingly difficult problem to solve in cases involving complicated probability models. In this paper, we treat the parameters as unknown variables and compute their posteriors via AMP. The parameters and signal of interest can then be jointly recovered. Compared to previous methods, the proposed approach leads to a simple and elegant parameter estimation scheme, allowing us to directly work with 1-bit quantization noise model. We then further extend our approach to general multi-bit quantization noise model. Experimental results show that the proposed framework provides significant improvement over state-of-the-art methods across a wide range of sparsity and noise levels.
* arXiv admin note: text overlap with arXiv:2007.07679
Optical Flow Estimation via Motion Feature Recovery
Jan 16, 2021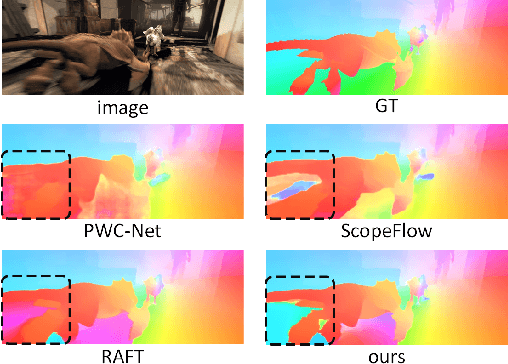
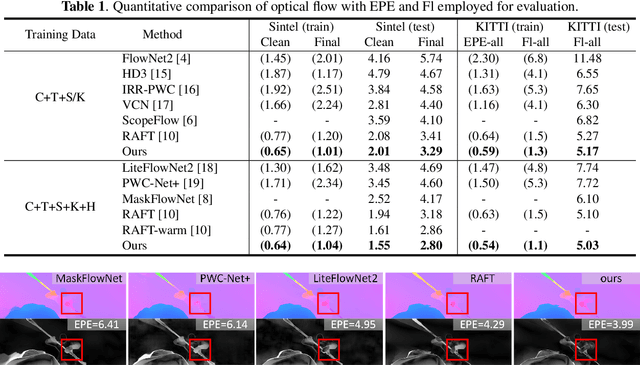
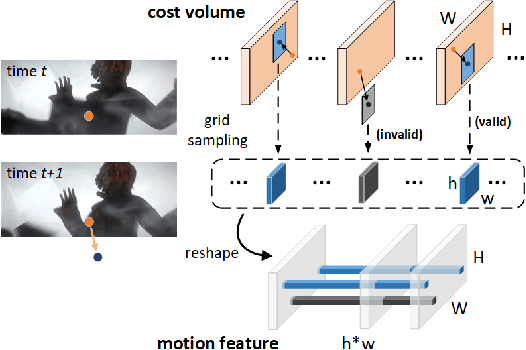
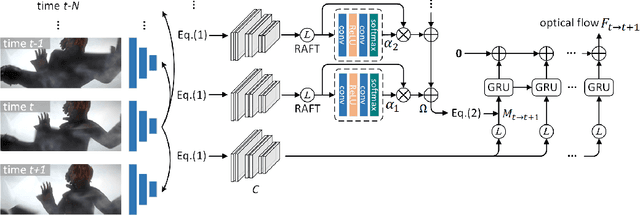
Optical flow estimation with occlusion or large displacement is a problematic challenge due to the lost of corresponding pixels between consecutive frames. In this paper, we discover that the lost information is related to a large quantity of motion features (more than 40%) computed from the popular discriminative cost-volume feature would completely vanish due to invalid sampling, leading to the low efficiency of optical flow learning. We call this phenomenon the Vanishing Cost Volume Problem. Inspired by the fact that local motion tends to be highly consistent within a short temporal window, we propose a novel iterative Motion Feature Recovery (MFR) method to address the vanishing cost volume via modeling motion consistency across multiple frames. In each MFR iteration, invalid entries from original motion features are first determined based on the current flow. Then, an efficient network is designed to adaptively learn the motion correlation to recover invalid features for lost-information restoration. The final optical flow is then decoded from the recovered motion features. Experimental results on Sintel and KITTI show that our method achieves state-of-the-art performances. In fact, MFR currently ranks second on Sintel public website.
2D+3D Facial Expression Recognition via Discriminative Dynamic Range Enhancement and Multi-Scale Learning
Nov 16, 2020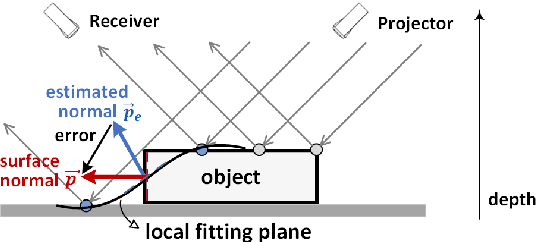
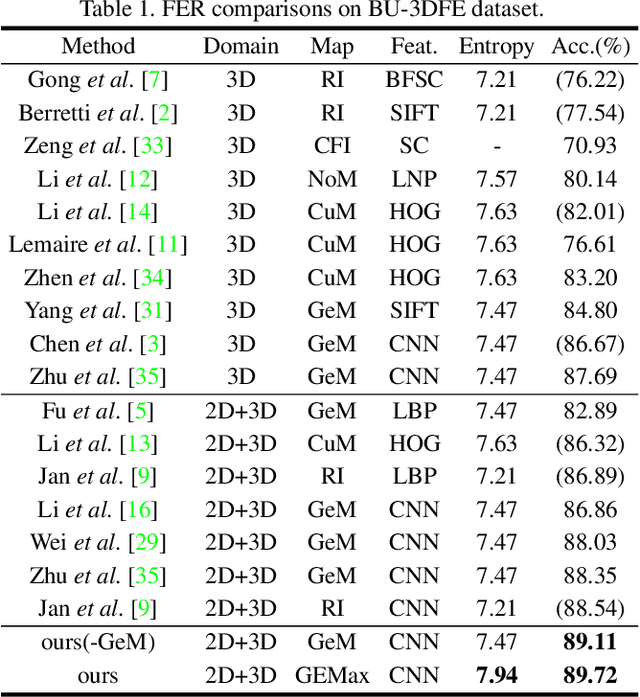


In 2D+3D facial expression recognition (FER), existing methods generate multi-view geometry maps to enhance the depth feature representation. However, this may introduce false estimations due to local plane fitting from incomplete point clouds. In this paper, we propose a novel Map Generation technique from the viewpoint of information theory, to boost the slight 3D expression differences from strong personality variations. First, we examine the HDR depth data to extract the discriminative dynamic range $r_{dis}$, and maximize the entropy of $r_{dis}$ to a global optimum. Then, to prevent the large deformation caused by over-enhancement, we introduce a depth distortion constraint and reduce the complexity from $O(KN^2)$ to $O(KN\tau)$. Furthermore, the constrained optimization is modeled as a $K$-edges maximum weight path problem in a directed acyclic graph, and we solve it efficiently via dynamic programming. Finally, we also design an efficient Facial Attention structure to automatically locate subtle discriminative facial parts for multi-scale learning, and train it with a proposed loss function $\mathcal{L}_{FA}$ without any facial landmarks. Experimental results on different datasets show that the proposed method is effective and outperforms the state-of-the-art 2D+3D FER methods in both FER accuracy and the output entropy of the generated maps.
EffiScene: Efficient Per-Pixel Rigidity Inference for Unsupervised Joint Learning of Optical Flow, Depth, Camera Pose and Motion Segmentation
Nov 16, 2020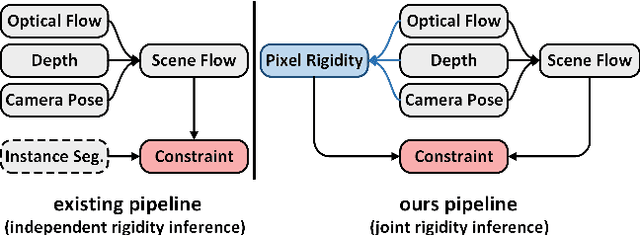
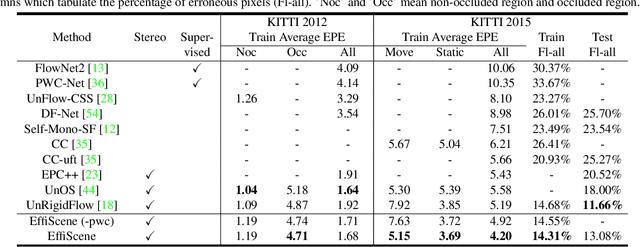
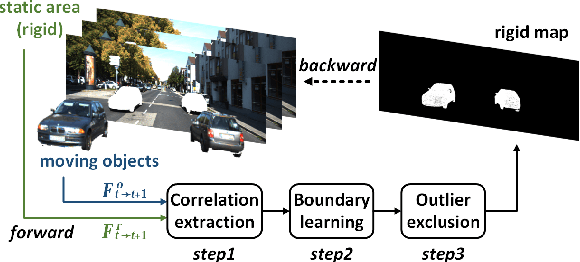
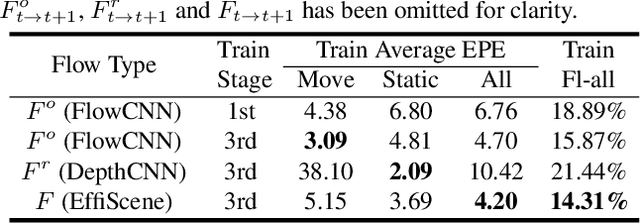
This paper addresses the challenging unsupervised scene flow estimation problem by jointly learning four low-level vision sub-tasks: optical flow $\textbf{F}$, stereo-depth $\textbf{D}$, camera pose $\textbf{P}$ and motion segmentation $\textbf{S}$. Our key insight is that the rigidity of the scene shares the same inherent geometrical structure with object movements and scene depth. Hence, rigidity from $\textbf{S}$ can be inferred by jointly coupling $\textbf{F}$, $\textbf{D}$ and $\textbf{P}$ to achieve more robust estimation. To this end, we propose a novel scene flow framework named EffiScene with efficient joint rigidity learning, going beyond existing pipeline with independent auxiliary structures. In EffiScene, we first estimate optical flow and depth at the coarse level and then compute camera pose by Perspective-$n$-Points method. To jointly learn local rigidity, we design a novel Rigidity From Motion (RfM) layer with three principal components: (i) correlation extraction; (ii) boundary learning; and (iii) outlier exclusion. Final outputs are fused based on the rigid map $M_R$ from RfM at finer level. To efficiently train EffiScene, two new losses $\mathcal{L}_{bnd}$ and $\mathcal{L}_{unc}$ are designed to prevent trivial solutions and to regularize the flow boundary discontinuity. Extensive experiments on scene flow benchmark KITTI show that our method is effective and significantly improves the state-of-the-art approaches for all sub-tasks, i.e. optical flow (5.19 $\rightarrow$ 4.20), depth estimation (3.78 $\rightarrow$ 3.46), visual odometry (0.012 $\rightarrow$ 0.011) and motion segmentation (0.57 $\rightarrow$ 0.62).
A Scale Invariant Flatness Measure for Deep Network Minima
Feb 06, 2019



It has been empirically observed that the flatness of minima obtained from training deep networks seems to correlate with better generalization. However, for deep networks with positively homogeneous activations, most measures of sharpness/flatness are not invariant to rescaling of the network parameters, corresponding to the same function. This means that the measure of flatness/sharpness can be made as small or as large as possible through rescaling, rendering the quantitative measures meaningless. In this paper we show that for deep networks with positively homogenous activations, these rescalings constitute equivalence relations, and that these equivalence relations induce a quotient manifold structure in the parameter space. Using this manifold structure and an appropriate metric, we propose a Hessian-based measure for flatness that is invariant to rescaling. We use this new measure to confirm the proposition that Large-Batch SGD minima are indeed sharper than Small-Batch SGD minima.
Reducing Sampling Ratios and Increasing Number of Estimates Improve Bagging in Sparse Regression
Dec 20, 2018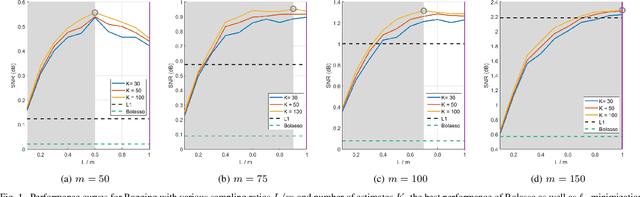

Bagging, a powerful ensemble method from machine learning, improves the performance of unstable predictors. Although the power of Bagging has been shown mostly in classification problems, we demonstrate the success of employing Bagging in sparse regression over the baseline method (L1 minimization). The framework employs the generalized version of the original Bagging with various bootstrap ratios. The performance limits associated with different choices of bootstrap sampling ratio L/m and number of estimates K is analyzed theoretically. Simulation shows that the proposed method yields state-of-the-art recovery performance, outperforming L1 minimization and Bolasso in the challenging case of low levels of measurements. A lower L/m ratio (60% - 90%) leads to better performance, especially with a small number of measurements. With the reduced sampling rate, SNR improves over the original Bagging by up to 24%. With a properly chosen sampling ratio, a reasonably small number of estimates K = 30 gives satisfying result, even though increasing K is discovered to always improve or at least maintain the performance.
Generative Adversarial Networks for Recovering Missing Spectral Information
Dec 13, 2018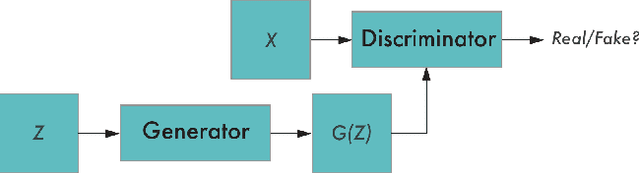
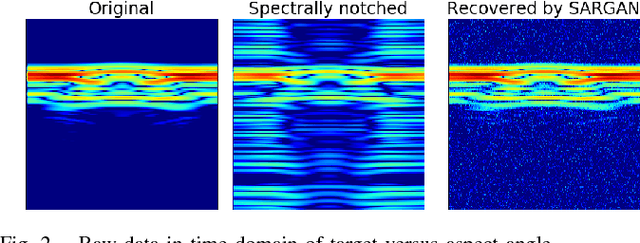

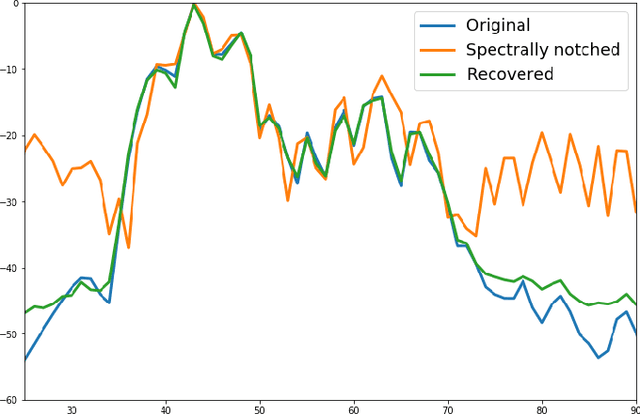
Ultra-wideband (UWB) radar systems nowadays typical operate in the low frequency spectrum to achieve penetration capability. However, this spectrum is also shared by many others communication systems, which causes missing information in the frequency bands. To recover this missing spectral information, we propose a generative adversarial network, called SARGAN, that learns the relationship between original and missing band signals by observing these training pairs in a clever way. Initial results shows that this approach is promising in tackling this challenging missing band problem.
JOBS: Joint-Sparse Optimization from Bootstrap Samples
Oct 08, 2018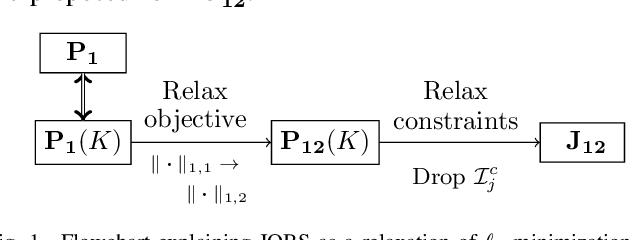
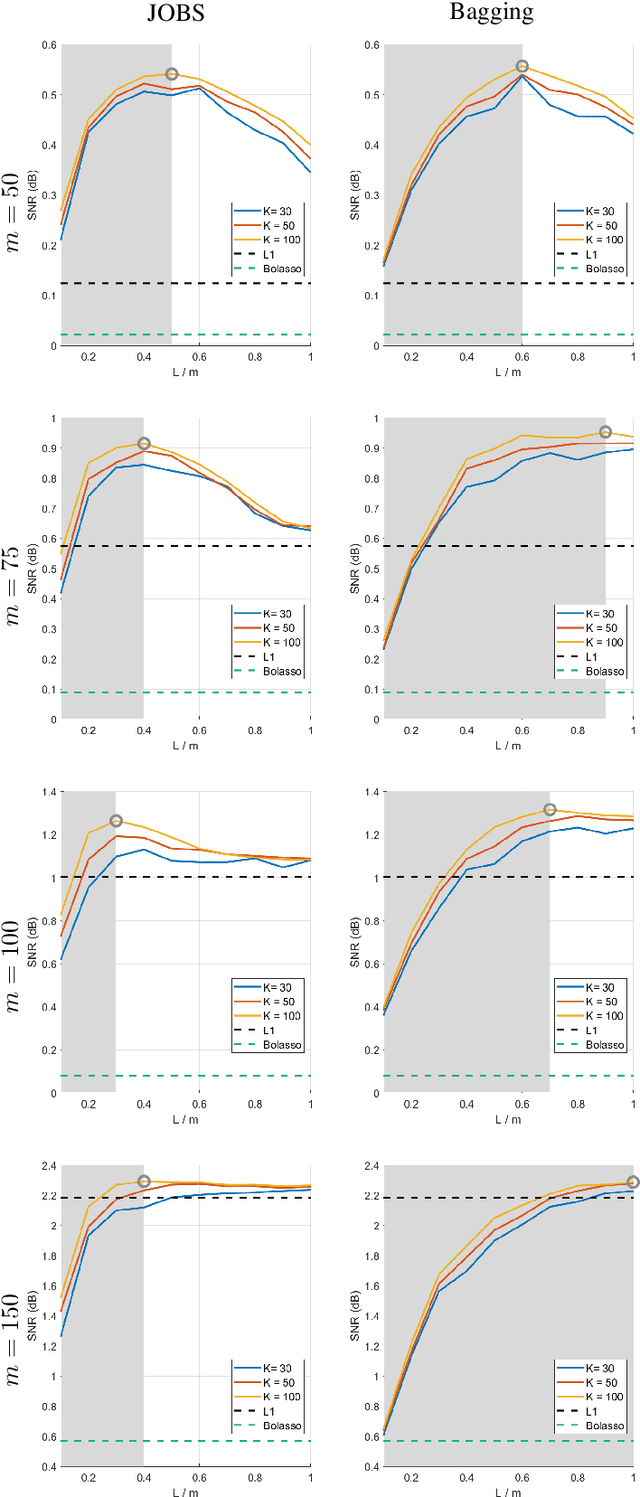
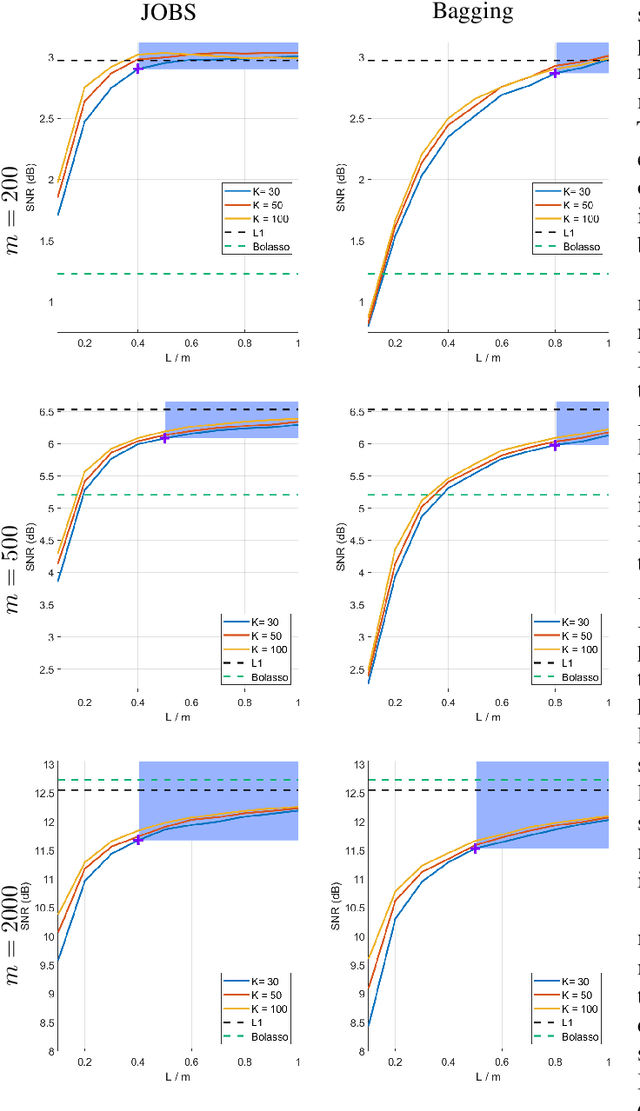
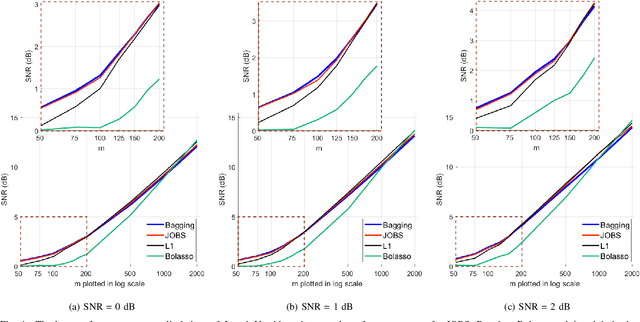
Classical signal recovery based on $\ell_1$ minimization solves the least squares problem with all available measurements via sparsity-promoting regularization. In practice, it is often the case that not all measurements are available or required for recovery. Measurements might be corrupted/missing or they arrive sequentially in streaming fashion. In this paper, we propose a global sparse recovery strategy based on subsets of measurements, named JOBS, in which multiple measurements vectors are generated from the original pool of measurements via bootstrapping, and then a joint-sparse constraint is enforced to ensure support consistency among multiple predictors. The final estimate is obtained by averaging over the $K$ predictors. The performance limits associated with different choices of number of bootstrap samples $L$ and number of estimates $K$ is analyzed theoretically. Simulation results validate some of the theoretical analysis, and show that the proposed method yields state-of-the-art recovery performance, outperforming $\ell_1$ minimization and a few other existing bootstrap-based techniques in the challenging case of low levels of measurements and is preferable over other bagging-based methods in the streaming setting since it performs better with small $K$ and $L$ for data-sets with large sizes.