 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectrum-inspired Low-light Image Translation for Saliency Detection
Mar 17, 2023

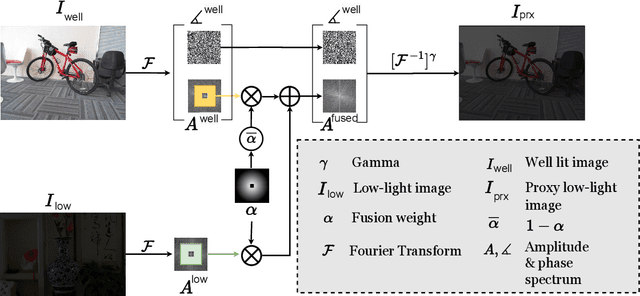

Saliency detection methods are central to several real-world applications such as robot navigation and satellite imagery. However, the performance of existing methods deteriorate under low-light conditions because training datasets mostly comprise of well-lit images. One possible solution is to collect a new dataset for low-light conditions. This involves pixel-level annotations, which is not only tedious and time-consuming but also infeasible if a huge training corpus is required. We propose a technique that performs classical band-pass filtering in the Fourier space to transform well-lit images to low-light images and use them as a proxy for real low-light images. Unlike popular deep learning approaches which require learning thousands of parameters and enormous amounts of training data, the proposed transformation is fast and simple and easy to extend to other tasks such as low-light depth estimation. Our experiments show that the state-of-the-art saliency detection and depth estimation networks trained on our proxy low-light images perform significantly better on real low-light images than networks trained using existing strategies.
Towards Fast and Light-Weight Restoration of Dark Images
Nov 28, 2020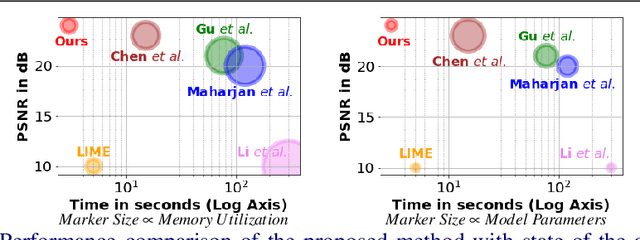



The ability to capture good quality images in the dark and near-zero lux conditions has been a long-standing pursuit of the computer vision community. The seminal work by Chen et al. [5] has especially caused renewed interest in this area, resulting in methods that build on top of their work in a bid to improve the reconstruction. However, for practical utility and deployment of low-light enhancement algorithms on edge devices such as embedded systems, surveillance cameras, autonomous robots and smartphones, the solution must respect additional constraints such as limited GPU memory and processing power. With this in mind, we propose a deep neural network architecture that aims to strike a balance between the network latency, memory utilization, model parameters, and reconstruction quality. The key idea is to forbid computations in the High-Resolution (HR) space and limit them to a Low-Resolution (LR) space. However, doing the bulk of computations in the LR space causes artifacts in the restored image. We thus propose Pack and UnPack operations, which allow us to effectively transit between the HR and LR spaces without incurring much artifacts in the restored image. We show that we can enhance a full resolution, 2848 x 4256, extremely dark single-image in the ballpark of 3 seconds even on a CPU. We achieve this with 2 - 7x fewer model parameters, 2 - 3x lower memory utilization, 5 - 20x speed up and yet maintain a competitive image reconstruction quality compared to the state-of-the-art algorithms.
Roommate Compatibility Detection Through Machine Learning Techniques
Apr 15, 2020

Our objective is to develop an artificially intelligent system which aims at checking the compatibility between the roommates of same or different sex sharing a common area of residence. There are a few key factors determining one's compatibility with the other person. Interpersonal behaviour , situational awareness, communication skills. Here we are trying to build a system that evaluates user on these key factors not via pen paper test but through a highly engaging set of questions and answers. Hence using these scores as an input to our machine learning algorithm which is based on previous trends to come up with percentage probability of user being compatible with another user. With the growing population there is always a challenge for organisation and educational institutions to make the students and their employees more and more productive and in such cases a person's social environment comes into play. A person may be a genius but as long as he is not able to work well with his peers there will always be a chance of more productive performance. It is a well-established fact that human are and have always been a social animal and this has helped in creating communities of like-minded people. Many times, even when there are a large no of people employed to do a particular task the result may not be as expected as people may not compatible in working with one another. This at the end creates performance gaps, hinders organisation success and in many cases loss of precious resources. Our intent is not to remove the non-compatible people from the picture but to find out the perfect compatible match for the person elsewhere that will not only save the resources will also enable effective use of resources. Through the use of various machine learning classification techniques, we intent to do this.
Harnessing Multi-View Perspective of Light Fields for Low-Light Imaging
Mar 05, 2020



Light Field (LF) offers unique advantages such as post-capture refocusing and depth estimation, but low-light conditions limit these capabilities. To restore low-light LFs we should harness the geometric cues present in different LF views, which is not possible using single-frame low-light enhancement techniques. We, therefore, propose a deep neural network for Low-Light Light Field (L3F) restoration, which we refer to as L3Fnet. The proposed L3Fnet not only performs the necessary visual enhancement of each LF view but also preserves the epipolar geometry across views. We achieve this by adopting a two-stage architecture for L3Fnet. Stage-I looks at all the LF views to encode the LF geometry. This encoded information is then used in Stage-II to reconstruct each LF view. To facilitate learning-based techniques for low-light LF imaging, we collected a comprehensive LF dataset of various scenes. For each scene, we captured four LFs, one with near-optimal exposure and ISO settings and the others at different levels of low-light conditions varying from low to extreme low-light settings. The effectiveness of the proposed L3Fnet is supported by both visual and numerical comparisons on this dataset. To further analyze the performance of low-light reconstruction methods, we also propose an L3F-wild dataset that contains LF captured late at night with almost zero lux values. No ground truth is available in this dataset. To perform well on the L3F-wild dataset, any method must adapt to the light level of the captured scene. To do this we propose a novel pre-processing block that makes L3Fnet robust to various degrees of low-light conditions. Lastly, we show that L3Fnet can also be used for low-light enhancement of single-frame images, despite it being engineered for LF data. We do so by converting the single-frame DSLR image into a form suitable to L3Fnet, which we call as pseudo-LF.
multi-patch aggregation models for resampling detection
Mar 03, 2020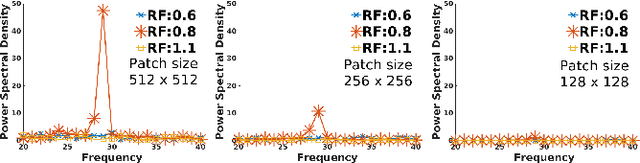

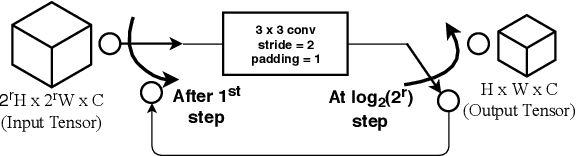

Images captured nowadays are of varying dimensions with smartphones and DSLR's allowing users to choose from a list of available image resolutions. It is therefore imperative for forensic algorithms such as resampling detection to scale well for images of varying dimensions. However, in our experiments, we observed that many state-of-the-art forensic algorithms are sensitive to image size and their performance quickly degenerates when operated on images of diverse dimensions despite re-training them using multiple image sizes. To handle this issue, we propose a novel pooling strategy called ITERATIVE POOLING. This pooling strategy can dynamically adjust input tensors in a discrete without much loss of information as in ROI Max-pooling. This pooling strategy can be used with any of the existing deep models and for demonstration purposes, we show its utility on Resnet-18 for the case of resampling detection a fundamental operation for any image sought of image manipulation. Compared to existing strategies and Max-pooling it gives up to 7-8% improvement on public datasets.