 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarnessing Multi-View Perspective of Light Fields for Low-Light Imaging
Mar 05, 2020



Light Field (LF) offers unique advantages such as post-capture refocusing and depth estimation, but low-light conditions limit these capabilities. To restore low-light LFs we should harness the geometric cues present in different LF views, which is not possible using single-frame low-light enhancement techniques. We, therefore, propose a deep neural network for Low-Light Light Field (L3F) restoration, which we refer to as L3Fnet. The proposed L3Fnet not only performs the necessary visual enhancement of each LF view but also preserves the epipolar geometry across views. We achieve this by adopting a two-stage architecture for L3Fnet. Stage-I looks at all the LF views to encode the LF geometry. This encoded information is then used in Stage-II to reconstruct each LF view. To facilitate learning-based techniques for low-light LF imaging, we collected a comprehensive LF dataset of various scenes. For each scene, we captured four LFs, one with near-optimal exposure and ISO settings and the others at different levels of low-light conditions varying from low to extreme low-light settings. The effectiveness of the proposed L3Fnet is supported by both visual and numerical comparisons on this dataset. To further analyze the performance of low-light reconstruction methods, we also propose an L3F-wild dataset that contains LF captured late at night with almost zero lux values. No ground truth is available in this dataset. To perform well on the L3F-wild dataset, any method must adapt to the light level of the captured scene. To do this we propose a novel pre-processing block that makes L3Fnet robust to various degrees of low-light conditions. Lastly, we show that L3Fnet can also be used for low-light enhancement of single-frame images, despite it being engineered for LF data. We do so by converting the single-frame DSLR image into a form suitable to L3Fnet, which we call as pseudo-LF.
Watch to Edit: Video Retargeting using Gaze
Jun 27, 2018


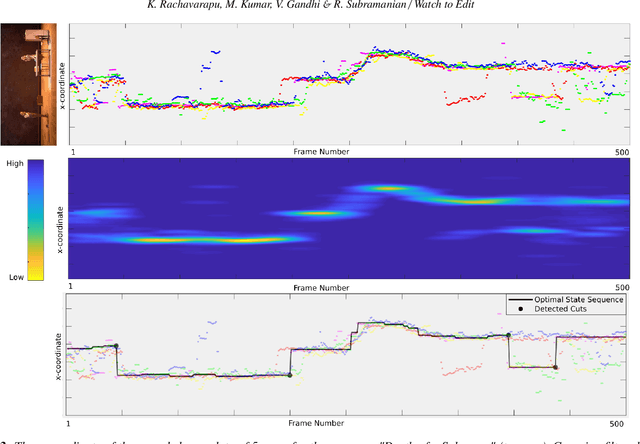
We present a novel approach to optimally retarget videos for varied displays with differing aspect ratios by preserving salient scene content discovered via eye tracking. Our algorithm performs editing with cut, pan and zoom operations by optimizing the path of a cropping window within the original video while seeking to (i) preserve salient regions, and (ii) adhere to the principles of cinematography. Our approach is (a) content agnostic as the same methodology is employed to re-edit a wide-angle video recording or a close-up movie sequence captured with a static or moving camera, and (b) independent of video length and can in principle re-edit an entire movie in one shot. Our algorithm consists of two steps. The first step employs gaze transition cues to detect time stamps where new cuts are to be introduced in the original video via dynamic programming. A subsequent step optimizes the cropping window path (to create pan and zoom effects), while accounting for the original and new cuts. The cropping window path is designed to include maximum gaze information, and is composed of piecewise constant, linear and parabolic segments. It is obtained via L(1) regularized convex optimization which ensures a smooth viewing experience. We test our approach on a wide variety of videos and demonstrate significant improvement over the state-of-the-art, both in terms of computational complexity and qualitative aspects. A study performed with 16 users confirms that our approach results in a superior viewing experience as compared to gaze driven re-editing and letterboxing methods, especially for wide-angle static camera recordings.