 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStable Diffusion Models are Secretly Good at Visual In-Context Learning
Aug 13, 2025Large language models (LLM) in natural language processing (NLP) have demonstrated great potential for in-context learning (ICL) -- the ability to leverage a few sets of example prompts to adapt to various tasks without having to explicitly update the model weights. ICL has recently been explored for computer vision tasks with promising early outcomes. These approaches involve specialized training and/or additional data that complicate the process and limit its generalizability. In this work, we show that off-the-shelf Stable Diffusion models can be repurposed for visual in-context learning (V-ICL). Specifically, we formulate an in-place attention re-computation within the self-attention layers of the Stable Diffusion architecture that explicitly incorporates context between the query and example prompts. Without any additional fine-tuning, we show that this repurposed Stable Diffusion model is able to adapt to six different tasks: foreground segmentation, single object detection, semantic segmentation, keypoint detection, edge detection, and colorization. For example, the proposed approach improves the mean intersection over union (mIoU) for the foreground segmentation task on Pascal-5i dataset by 8.9% and 3.2% over recent methods such as Visual Prompting and IMProv, respectively. Additionally, we show that the proposed method is able to effectively leverage multiple prompts through ensembling to infer the task better and further improve the performance.
$\mathsf{CSMAE~}$:~Cataract Surgical Masked Autoencoder (MAE) based Pre-training
Feb 12, 2025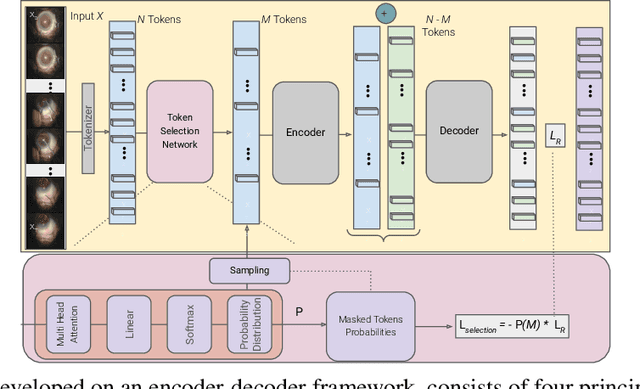


Automated analysis of surgical videos is crucial for improving surgical training, workflow optimization, and postoperative assessment. We introduce a CSMAE, Masked Autoencoder (MAE)-based pretraining approach, specifically developed for Cataract Surgery video analysis, where instead of randomly selecting tokens for masking, they are selected based on the spatiotemporal importance of the token. We created a large dataset of cataract surgery videos to improve the model's learning efficiency and expand its robustness in low-data regimes. Our pre-trained model can be easily adapted for specific downstream tasks via fine-tuning, serving as a robust backbone for further analysis. Through rigorous testing on a downstream step-recognition task on two Cataract Surgery video datasets, D99 and Cataract-101, our approach surpasses current state-of-the-art self-supervised pretraining and adapter-based transfer learning methods by a significant margin. This advancement not only demonstrates the potential of our MAE-based pretraining in the field of surgical video analysis but also sets a new benchmark for future research.
Attention Prompt Tuning: Parameter-efficient Adaptation of Pre-trained Models for Spatiotemporal Modeling
Mar 11, 2024In this paper, we introduce Attention Prompt Tuning (APT) - a computationally efficient variant of prompt tuning for video-based applications such as action recognition. Prompt tuning approaches involve injecting a set of learnable prompts along with data tokens during fine-tuning while keeping the backbone frozen. This approach greatly reduces the number of learnable parameters compared to full tuning. For image-based downstream tasks, normally a couple of learnable prompts achieve results close to those of full tuning. However, videos, which contain more complex spatiotemporal information, require hundreds of tunable prompts to achieve reasonably good results. This reduces the parameter efficiency observed in images and significantly increases latency and the number of floating-point operations (FLOPs) during inference. To tackle these issues, we directly inject the prompts into the keys and values of the non-local attention mechanism within the transformer block. Additionally, we introduce a novel prompt reparameterization technique to make APT more robust against hyperparameter selection. The proposed APT approach greatly reduces the number of FLOPs and latency while achieving a significant performance boost over the existing parameter-efficient tuning methods on UCF101, HMDB51, and SSv2 datasets for action recognition. The code and pre-trained models are available at https://github.com/wgcban/apt
Guarding Barlow Twins Against Overfitting with Mixed Samples
Dec 04, 2023



Self-supervised Learning (SSL) aims to learn transferable feature representations for downstream applications without relying on labeled data. The Barlow Twins algorithm, renowned for its widespread adoption and straightforward implementation compared to its counterparts like contrastive learning methods, minimizes feature redundancy while maximizing invariance to common corruptions. Optimizing for the above objective forces the network to learn useful representations, while avoiding noisy or constant features, resulting in improved downstream task performance with limited adaptation. Despite Barlow Twins' proven effectiveness in pre-training, the underlying SSL objective can inadvertently cause feature overfitting due to the lack of strong interaction between the samples unlike the contrastive learning approaches. From our experiments, we observe that optimizing for the Barlow Twins objective doesn't necessarily guarantee sustained improvements in representation quality beyond a certain pre-training phase, and can potentially degrade downstream performance on some datasets. To address this challenge, we introduce Mixed Barlow Twins, which aims to improve sample interaction during Barlow Twins training via linearly interpolated samples. This results in an additional regularization term to the original Barlow Twins objective, assuming linear interpolation in the input space translates to linearly interpolated features in the feature space. Pre-training with this regularization effectively mitigates feature overfitting and further enhances the downstream performance on CIFAR-10, CIFAR-100, TinyImageNet, STL-10, and ImageNet datasets. The code and checkpoints are available at: https://github.com/wgcban/mix-bt.git
Diffuse-Denoise-Count: Accurate Crowd-Counting with Diffusion Models
Mar 22, 2023Crowd counting is a key aspect of crowd analysis and has been typically accomplished by estimating a crowd-density map and summing over the density values. However, this approach suffers from background noise accumulation and loss of density due to the use of broad Gaussian kernels to create the ground truth density maps. This issue can be overcome by narrowing the Gaussian kernel. However, existing approaches perform poorly when trained with such ground truth density maps. To overcome this limitation, we propose using conditional diffusion models to predict density maps, as diffusion models are known to model complex distributions well and show high fidelity to training data during crowd-density map generation. Furthermore, as the intermediate time steps of the diffusion process are noisy, we incorporate a regression branch for direct crowd estimation only during training to improve the feature learning. In addition, owing to the stochastic nature of the diffusion model, we introduce producing multiple density maps to improve the counting performance contrary to the existing crowd counting pipelines. Further, we also differ from the density summation and introduce contour detection followed by summation as the counting operation, which is more immune to background noise. We conduct extensive experiments on public datasets to validate the effectiveness of our method. Specifically, our novel crowd-counting pipeline improves the error of crowd-counting by up to $6\%$ on JHU-CROWD++ and up to $7\%$ on UCF-QNRF.
Deep Metric Learning for Unsupervised Remote Sensing Change Detection
Mar 16, 2023Remote Sensing Change Detection (RS-CD) aims to detect relevant changes from Multi-Temporal Remote Sensing Images (MT-RSIs), which aids in various RS applications such as land cover, land use, human development analysis, and disaster response. The performance of existing RS-CD methods is attributed to training on large annotated datasets. Furthermore, most of these models are less transferable in the sense that the trained model often performs very poorly when there is a domain gap between training and test datasets. This paper proposes an unsupervised CD method based on deep metric learning that can deal with both of these issues. Given an MT-RSI, the proposed method generates corresponding change probability map by iteratively optimizing an unsupervised CD loss without training it on a large dataset. Our unsupervised CD method consists of two interconnected deep networks, namely Deep-Change Probability Generator (D-CPG) and Deep-Feature Extractor (D-FE). The D-CPG is designed to predict change and no change probability maps for a given MT-RSI, while D-FE is used to extract deep features of MT-RSI that will be further used in the proposed unsupervised CD loss. We use transfer learning capability to initialize the parameters of D-FE. We iteratively optimize the parameters of D-CPG and D-FE for a given MT-RSI by minimizing the proposed unsupervised ``similarity-dissimilarity loss''. This loss is motivated by the principle of metric learning where we simultaneously maximize the distance between change pair-wise pixels while minimizing the distance between no-change pair-wise pixels in bi-temporal image domain and their deep feature domain. The experiments conducted on three CD datasets show that our unsupervised CD method achieves significant improvements over the state-of-the-art supervised and unsupervised CD methods. Code available at https://github.com/wgcban/Metric-CD
Unite and Conquer: Cross Dataset Multimodal Synthesis using Diffusion Models
Dec 01, 2022Generating photos satisfying multiple constraints find broad utility in the content creation industry. A key hurdle to accomplishing this task is the need for paired data consisting of all modalities (i.e., constraints) and their corresponding output. Moreover, existing methods need retraining using paired data across all modalities to introduce a new condition. This paper proposes a solution to this problem based on denoising diffusion probabilistic models (DDPMs). Our motivation for choosing diffusion models over other generative models comes from the flexible internal structure of diffusion models. Since each sampling step in the DDPM follows a Gaussian distribution, we show that there exists a closed-form solution for generating an image given various constraints. Our method can unite multiple diffusion models trained on multiple sub-tasks and conquer the combined task through our proposed sampling strategy. We also introduce a novel reliability parameter that allows using different off-the-shelf diffusion models trained across various datasets during sampling time alone to guide it to the desired outcome satisfying multiple constraints. We perform experiments on various standard multimodal tasks to demonstrate the effectiveness of our approach. More details can be found in https://nithin-gk.github.io/projectpages/Multidiff/index.html
AdaMAE: Adaptive Masking for Efficient Spatiotemporal Learning with Masked Autoencoders
Nov 16, 2022



Masked Autoencoders (MAEs) learn generalizable representations for image, text, audio, video, etc., by reconstructing masked input data from tokens of the visible data. Current MAE approaches for videos rely on random patch, tube, or frame-based masking strategies to select these tokens. This paper proposes AdaMAE, an adaptive masking strategy for MAEs that is end-to-end trainable. Our adaptive masking strategy samples visible tokens based on the semantic context using an auxiliary sampling network. This network estimates a categorical distribution over spacetime-patch tokens. The tokens that increase the expected reconstruction error are rewarded and selected as visible tokens, motivated by the policy gradient algorithm in reinforcement learning. We show that AdaMAE samples more tokens from the high spatiotemporal information regions, thereby allowing us to mask 95% of tokens, resulting in lower memory requirements and faster pre-training. We conduct ablation studies on the Something-Something v2 (SSv2) dataset to demonstrate the efficacy of our adaptive sampling approach and report state-of-the-art results of 70.0% and 81.7% in top-1 accuracy on SSv2 and Kinetics-400 action classification datasets with a ViT-Base backbone and 800 pre-training epochs.
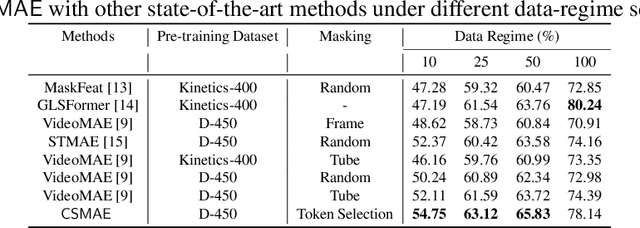
DDPM-CD: Remote Sensing Change Detection using Denoising Diffusion Probabilistic Models
Jun 27, 2022
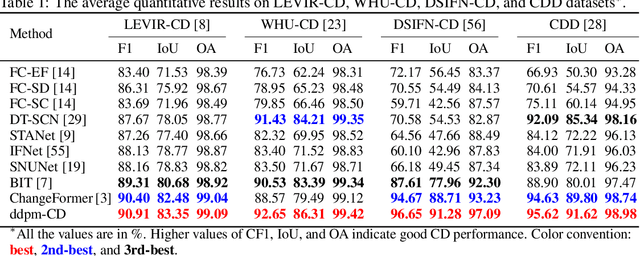


Human civilization has an increasingly powerful influence on the earth system, and earth observations are an invaluable tool for assessing and mitigating the negative impacts. To this end, observing precisely defined changes on Earth's surface is essential, and we propose an effective way to achieve this goal. Notably, our change detection (CD)/ segmentation method proposes a novel way to incorporate the millions of off-the-shelf, unlabeled, remote sensing images available through different earth observation programs into the training process through denoising diffusion probabilistic models. We first leverage the information from these off-the-shelf, uncurated, and unlabeled remote sensing images by using a pre-trained denoising diffusion probabilistic model and then employ the multi-scale feature representations from the diffusion model decoder to train a lightweight CD classifier to detect precise changes. The experiments performed on four publically available CD datasets show that the proposed approach achieves remarkably better results than the state-of-the-art methods in F1, IoU, and overall accuracy. Code and pre-trained models are available at: https://github.com/wgcban/ddpm-cd
Orientation-guided Graph Convolutional Network for Bone Surface Segmentation
Jun 16, 2022
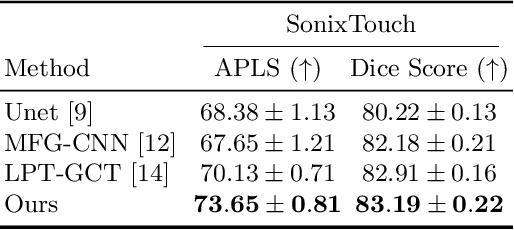
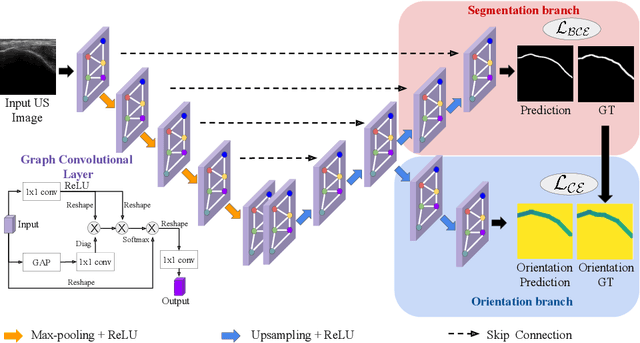
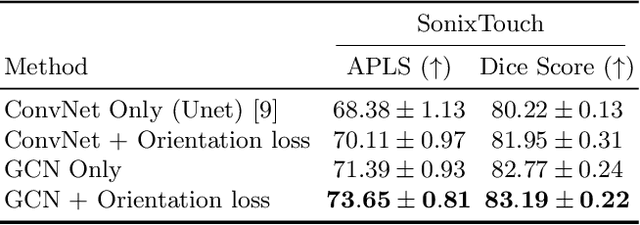
Due to imaging artifacts and low signal-to-noise ratio in ultrasound images, automatic bone surface segmentation networks often produce fragmented predictions that can hinder the success of ultrasound-guided computer-assisted surgical procedures. Existing pixel-wise predictions often fail to capture the accurate topology of bone tissues due to a lack of supervision to enforce connectivity. In this work, we propose an orientation-guided graph convolutional network to improve connectivity while segmenting the bone surface. We also propose an additional supervision on the orientation of the bone surface to further impose connectivity. We validated our approach on 1042 vivo US scans of femur, knee, spine, and distal radius. Our approach improves over the state-of-the-art methods by 5.01% in connectivity metric.