 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-space posterior sampling for Bayesian inference in constrained inverse problems
Feb 28, 2026Inverse problems constrained by partial differential equations are often ill-conditioned due to noisy and incomplete data or inherent non-uniqueness. A prominent example is full waveform inversion, which estimates Earth's subsurface properties by fitting seismic measurements subject to the wave equation, where ill-conditioning is inherent to noisy, band-limited, finite-aperture data and shadow zones. Casting the inverse problem into a Bayesian framework allows for a more comprehensive description of its solution, where instead of a single estimate, the posterior distribution characterizes non-uniqueness and can be sampled to quantify uncertainty. However, no clear procedure exists for translating hard physical constraints, such as the wave equation, into prior distributions amenable to existing sampling techniques. To address this, we perform posterior sampling in the dual space using an augmented Lagrangian formulation, which translates hard constraints into penalties amenable to sampling algorithms while ensuring their exact satisfaction. We achieve this by seamlessly integrating the alternating direction method of multipliers (ADMM) with Stein variational gradient descent (SVGD) -- a particle-based sampler -- where the constraint is relaxed at each iteration and multiplier updates progressively enforce satisfaction. This enables constrained posterior sampling while inheriting the favorable conditioning properties of dual-space solvers, where partial constraint relaxation allows productive updates even when the current model is far from the true solution. We validate the method on a stylized Rosenbrock conditional inference problem and on frequency-domain full waveform inversion for a Gaussian anomaly model and the Marmousi~II benchmark, demonstrating well-calibrated uncertainty estimates and posterior contraction with increasing data coverage.
AdaMAE: Adaptive Masking for Efficient Spatiotemporal Learning with Masked Autoencoders
Nov 16, 2022



Masked Autoencoders (MAEs) learn generalizable representations for image, text, audio, video, etc., by reconstructing masked input data from tokens of the visible data. Current MAE approaches for videos rely on random patch, tube, or frame-based masking strategies to select these tokens. This paper proposes AdaMAE, an adaptive masking strategy for MAEs that is end-to-end trainable. Our adaptive masking strategy samples visible tokens based on the semantic context using an auxiliary sampling network. This network estimates a categorical distribution over spacetime-patch tokens. The tokens that increase the expected reconstruction error are rewarded and selected as visible tokens, motivated by the policy gradient algorithm in reinforcement learning. We show that AdaMAE samples more tokens from the high spatiotemporal information regions, thereby allowing us to mask 95% of tokens, resulting in lower memory requirements and faster pre-training. We conduct ablation studies on the Something-Something v2 (SSv2) dataset to demonstrate the efficacy of our adaptive sampling approach and report state-of-the-art results of 70.0% and 81.7% in top-1 accuracy on SSv2 and Kinetics-400 action classification datasets with a ViT-Base backbone and 800 pre-training epochs.
MaskTune: Mitigating Spurious Correlations by Forcing to Explore
Oct 08, 2022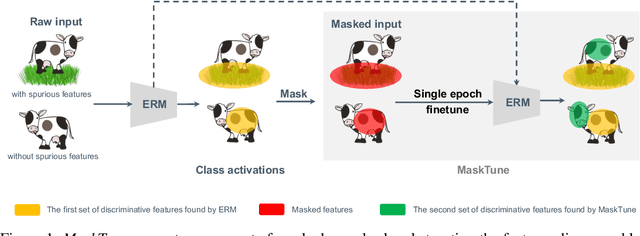
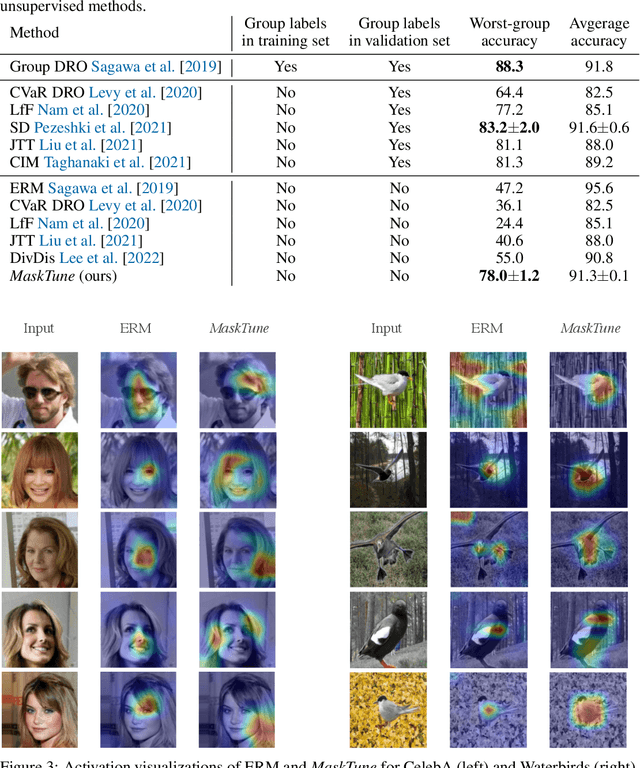
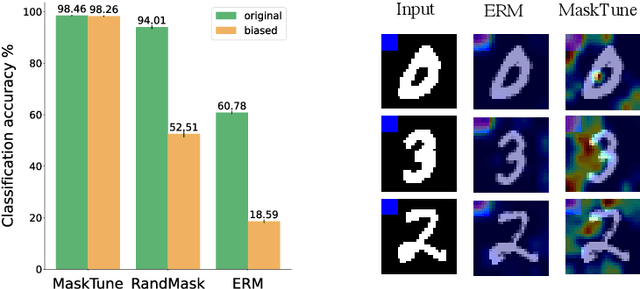

A fundamental challenge of over-parameterized deep learning models is learning meaningful data representations that yield good performance on a downstream task without over-fitting spurious input features. This work proposes MaskTune, a masking strategy that prevents over-reliance on spurious (or a limited number of) features. MaskTune forces the trained model to explore new features during a single epoch finetuning by masking previously discovered features. MaskTune, unlike earlier approaches for mitigating shortcut learning, does not require any supervision, such as annotating spurious features or labels for subgroup samples in a dataset. Our empirical results on biased MNIST, CelebA, Waterbirds, and ImagenNet-9L datasets show that MaskTune is effective on tasks that often suffer from the existence of spurious correlations. Finally, we show that MaskTune outperforms or achieves similar performance to the competing methods when applied to the selective classification (classification with rejection option) task. Code for MaskTune is available at https://github.com/aliasgharkhani/Masktune.
Counterbalancing Teacher: Regularizing Batch Normalized Models for Robustness
Jul 04, 2022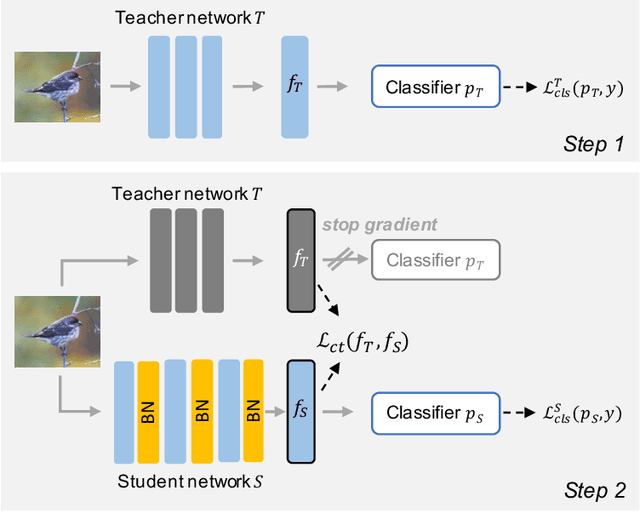
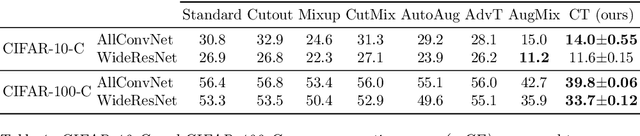
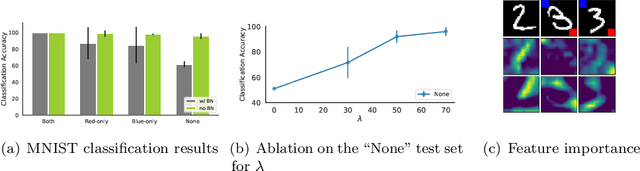
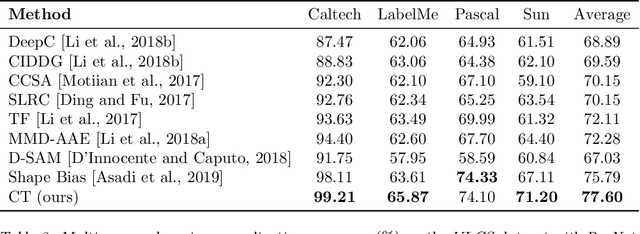
Batch normalization (BN) is a ubiquitous technique for training deep neural networks that accelerates their convergence to reach higher accuracy. However, we demonstrate that BN comes with a fundamental drawback: it incentivizes the model to rely on low-variance features that are highly specific to the training (in-domain) data, hurting generalization performance on out-of-domain examples. In this work, we investigate this phenomenon by first showing that removing BN layers across a wide range of architectures leads to lower out-of-domain and corruption errors at the cost of higher in-domain errors. We then propose Counterbalancing Teacher (CT), a method which leverages a frozen copy of the same model without BN as a teacher to enforce the student network's learning of robust representations by substantially adapting its weights through a consistency loss function. This regularization signal helps CT perform well in unforeseen data shifts, even without information from the target domain as in prior works. We theoretically show in an overparameterized linear regression setting why normalization leads to a model's reliance on such in-domain features, and empirically demonstrate the efficacy of CT by outperforming several baselines on robustness benchmarks such as CIFAR-10-C, CIFAR-100-C, and VLCS.
Scan2Cap: Context-aware Dense Captioning in RGB-D Scans
Dec 03, 2020
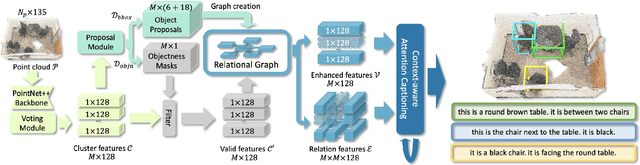

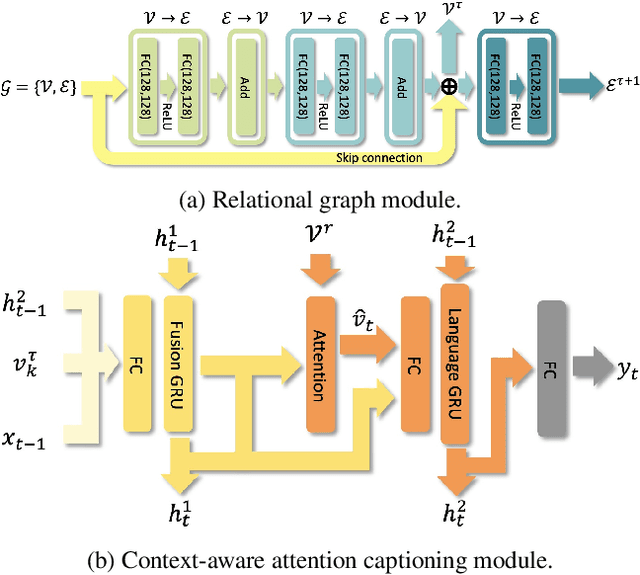
We introduce the task of dense captioning in 3D scans from commodity RGB-D sensors. As input, we assume a point cloud of a 3D scene; the expected output is the bounding boxes along with the descriptions for the underlying objects. To address the 3D object detection and description problems, we propose Scan2Cap, an end-to-end trained method, to detect objects in the input scene and describe them in natural language. We use an attention mechanism that generates descriptive tokens while referring to the related components in the local context. To reflect object relations (i.e. relative spatial relations) in the generated captions, we use a message passing graph module to facilitate learning object relation features. Our method can effectively localize and describe 3D objects in scenes from the ScanRefer dataset, outperforming 2D baseline methods by a significant margin (27.61% CiDEr@0.5IoUimprovement).