 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-like Object Grouping in Self-supervised Vision Transformers
Mar 14, 2026Vision foundation models trained with self-supervised objectives achieve strong performance across diverse tasks and exhibit emergent object segmentation properties. However, their alignment with human object perception remains poorly understood. Here, we introduce a behavioral benchmark in which participants make same/different object judgments for dot pairs on naturalistic scenes, scaling up a classical psychophysics paradigm to over 1000 trials. We test a diverse set of vision models using a simple readout from their representations to predict subjects' reaction times. We observe a steady improvement across model generations, with both architecture and training objective contributing to alignment, and transformer-based models trained with the DINO self-supervised objective showing the strongest performance. To investigate the source of this improvement, we propose a novel metric to quantify the object-centric component of representations by measuring patch similarity within and between objects. Across models, stronger object-centric structure predicts human segmentation behavior more accurately. We further show that matching the Gram matrix of supervised transformer models, capturing similarity structure across image patches, with that of a self-supervised model through distillation improves their alignment with human behavior, converging with the prior finding that Gram anchoring improves DINOv3's feature quality. Together, these results demonstrate that self-supervised vision models capture object structure in a behaviorally human-like manner, and that Gram matrix structure plays a role in driving perceptual alignment.
Disentangled Acoustic Fields For Multimodal Physical Scene Understanding
Jul 16, 2024



We study the problem of multimodal physical scene understanding, where an embodied agent needs to find fallen objects by inferring object properties, direction, and distance of an impact sound source. Previous works adopt feed-forward neural networks to directly regress the variables from sound, leading to poor generalization and domain adaptation issues. In this paper, we illustrate that learning a disentangled model of acoustic formation, referred to as disentangled acoustic field (DAF), to capture the sound generation and propagation process, enables the embodied agent to construct a spatial uncertainty map over where the objects may have fallen. We demonstrate that our analysis-by-synthesis framework can jointly infer sound properties by explicitly decomposing and factorizing the latent space of the disentangled model. We further show that the spatial uncertainty map can significantly improve the success rate for the localization of fallen objects by proposing multiple plausible exploration locations.
DiffusionPID: Interpreting Diffusion via Partial Information Decomposition
Jun 07, 2024
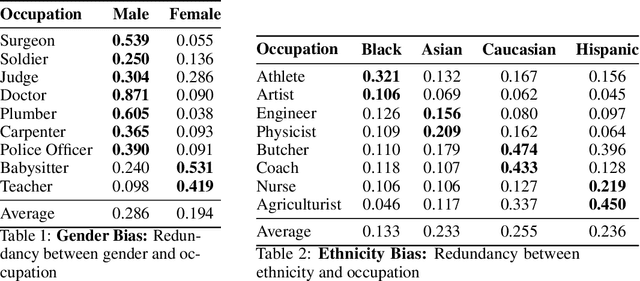


Text-to-image diffusion models have made significant progress in generating naturalistic images from textual inputs, and demonstrate the capacity to learn and represent complex visual-semantic relationships. While these diffusion models have achieved remarkable success, the underlying mechanisms driving their performance are not yet fully accounted for, with many unanswered questions surrounding what they learn, how they represent visual-semantic relationships, and why they sometimes fail to generalize. Our work presents Diffusion Partial Information Decomposition (DiffusionPID), a novel technique that applies information-theoretic principles to decompose the input text prompt into its elementary components, enabling a detailed examination of how individual tokens and their interactions shape the generated image. We introduce a formal approach to analyze the uniqueness, redundancy, and synergy terms by applying PID to the denoising model at both the image and pixel level. This approach enables us to characterize how individual tokens and their interactions affect the model output. We first present a fine-grained analysis of characteristics utilized by the model to uniquely localize specific concepts, we then apply our approach in bias analysis and show it can recover gender and ethnicity biases. Finally, we use our method to visually characterize word ambiguity and similarity from the model's perspective and illustrate the efficacy of our method for prompt intervention. Our results show that PID is a potent tool for evaluating and diagnosing text-to-image diffusion models.
Learning Neural Acoustic Fields
Apr 04, 2022
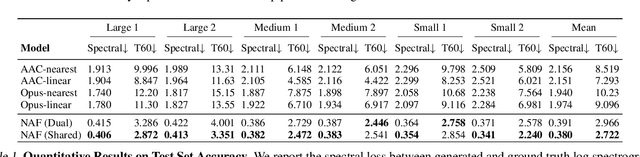

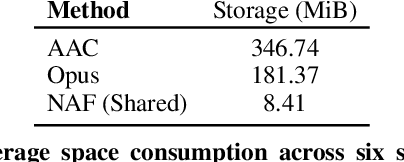
Our environment is filled with rich and dynamic acoustic information. When we walk into a cathedral, the reverberations as much as appearance inform us of the sanctuary's wide open space. Similarly, as an object moves around us, we expect the sound emitted to also exhibit this movement. While recent advances in learned implicit functions have led to increasingly higher quality representations of the visual world, there have not been commensurate advances in learning spatial auditory representations. To address this gap, we introduce Neural Acoustic Fields (NAFs), an implicit representation that captures how sounds propagate in a physical scene. By modeling acoustic propagation in a scene as a linear time-invariant system, NAFs learn to continuously map all emitter and listener location pairs to a neural impulse response function that can then be applied to arbitrary sounds. We demonstrate that the continuous nature of NAFs enables us to render spatial acoustics for a listener at an arbitrary location, and can predict sound propagation at novel locations. We further show that the representation learned by NAFs can help improve visual learning with sparse views. Finally, we show that a representation informative of scene structure emerges during the learning of NAFs.
SurfGen: Adversarial 3D Shape Synthesis with Explicit Surface Discriminators
Jan 01, 2022
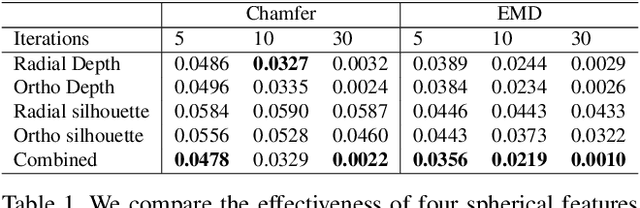

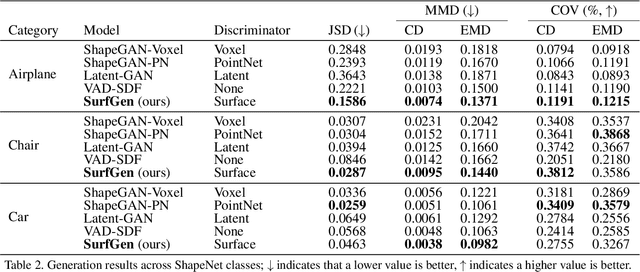
Recent advances in deep generative models have led to immense progress in 3D shape synthesis. While existing models are able to synthesize shapes represented as voxels, point-clouds, or implicit functions, these methods only indirectly enforce the plausibility of the final 3D shape surface. Here we present a 3D shape synthesis framework (SurfGen) that directly applies adversarial training to the object surface. Our approach uses a differentiable spherical projection layer to capture and represent the explicit zero isosurface of an implicit 3D generator as functions defined on the unit sphere. By processing the spherical representation of 3D object surfaces with a spherical CNN in an adversarial setting, our generator can better learn the statistics of natural shape surfaces. We evaluate our model on large-scale shape datasets, and demonstrate that the end-to-end trained model is capable of generating high fidelity 3D shapes with diverse topology.
End-to-End Optimization of Scene Layout
Jul 23, 2020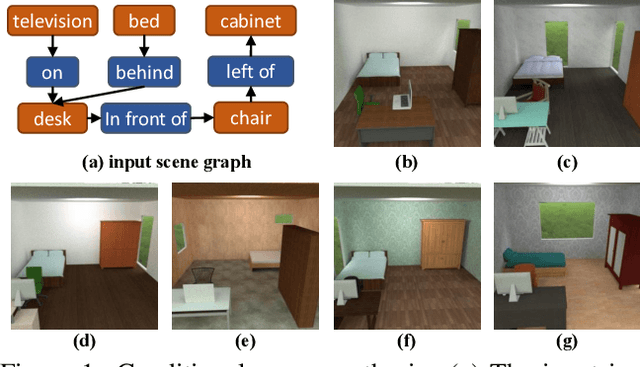
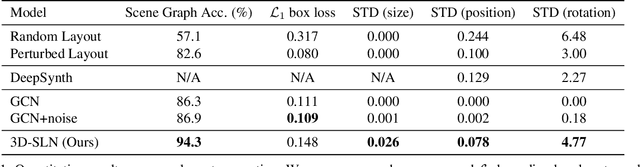
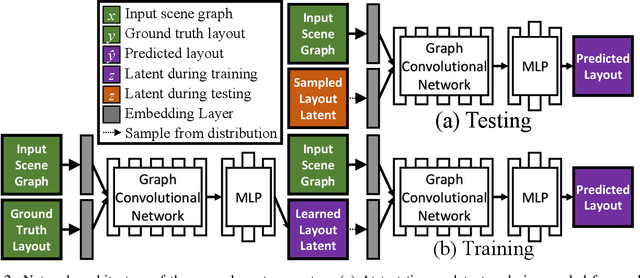
We propose an end-to-end variational generative model for scene layout synthesis conditioned on scene graphs. Unlike unconditional scene layout generation, we use scene graphs as an abstract but general representation to guide the synthesis of diverse scene layouts that satisfy relationships included in the scene graph. This gives rise to more flexible control over the synthesis process, allowing various forms of inputs such as scene layouts extracted from sentences or inferred from a single color image. Using our conditional layout synthesizer, we can generate various layouts that share the same structure of the input example. In addition to this conditional generation design, we also integrate a differentiable rendering module that enables layout refinement using only 2D projections of the scene. Given a depth and a semantics map, the differentiable rendering module enables optimizing over the synthesized layout to fit the given input in an analysis-by-synthesis fashion. Experiments suggest that our model achieves higher accuracy and diversity in conditional scene synthesis and allows exemplar-based scene generation from various input forms.
Learning to Infer and Execute 3D Shape Programs
Jan 09, 2019

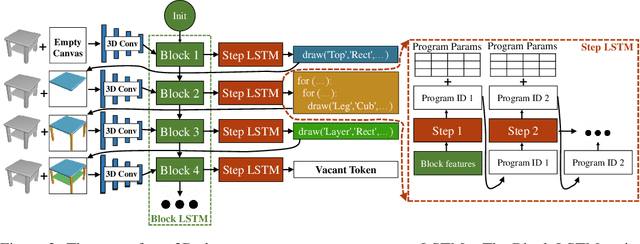
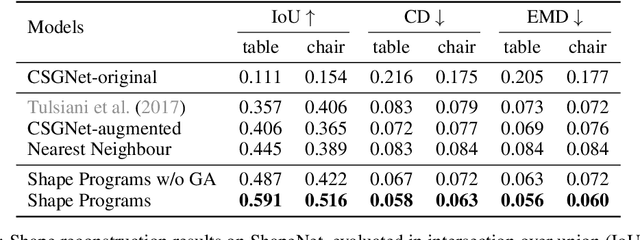
Human perception of 3D shapes goes beyond reconstructing them as a set of points or a composition of geometric primitives: we also effortlessly understand higher-level shape structure such as the repetition and reflective symmetry of object parts. In contrast, recent advances in 3D shape sensing focus more on low-level geometry but less on these higher-level relationships. In this paper, we propose 3D shape programs, integrating bottom-up recognition systems with top-down, symbolic program structure to capture both low-level geometry and high-level structural priors for 3D shapes. Because there are no annotations of shape programs for real shapes, we develop neural modules that not only learn to infer 3D shape programs from raw, unannotated shapes, but also to execute these programs for shape reconstruction. After initial bootstrapping, our end-to-end differentiable model learns 3D shape programs by reconstructing shapes in a self-supervised manner. Experiments demonstrate that our model accurately infers and executes 3D shape programs for highly complex shapes from various categories. It can also be integrated with an image-to-shape module to infer 3D shape programs directly from an RGB image, leading to 3D shape reconstructions that are both more accurate and more physically plausible.