 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Pneumatic Non-Prehensile Manipulation with a Mobile Blower
Apr 05, 2022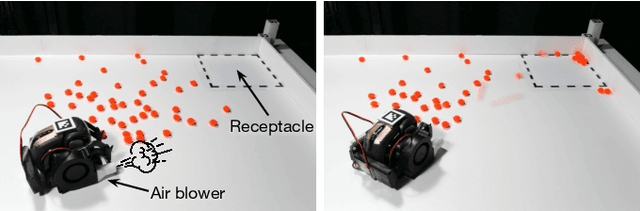
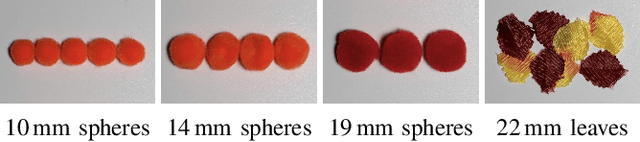

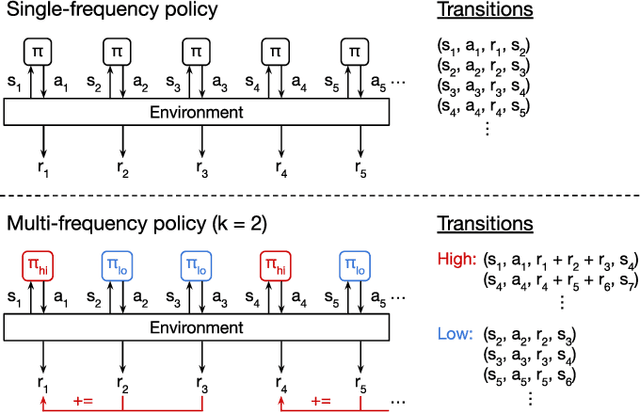
We investigate pneumatic non-prehensile manipulation (i.e., blowing) as a means of efficiently moving scattered objects into a target receptacle. Due to the chaotic nature of aerodynamic forces, a blowing controller must (i) continually adapt to unexpected changes from its actions, (ii) maintain fine-grained control, since the slightest misstep can result in large unintended consequences (e.g., scatter objects already in a pile), and (iii) infer long-range plans (e.g., move the robot to strategic blowing locations). We tackle these challenges in the context of deep reinforcement learning, introducing a multi-frequency version of the spatial action maps framework. This allows for efficient learning of vision-based policies that effectively combine high-level planning and low-level closed-loop control for dynamic mobile manipulation. Experiments show that our system learns efficient behaviors for the task, demonstrating in particular that blowing achieves better downstream performance than pushing, and that our policies improve performance over baselines. Moreover, we show that our system naturally encourages emergent specialization between the different subpolicies spanning low-level fine-grained control and high-level planning. On a real mobile robot equipped with a miniature air blower, we show that our simulation-trained policies transfer well to a real environment and can generalize to novel objects.
Amortized Synthesis of Constrained Configurations Using a Differentiable Surrogate
Jun 16, 2021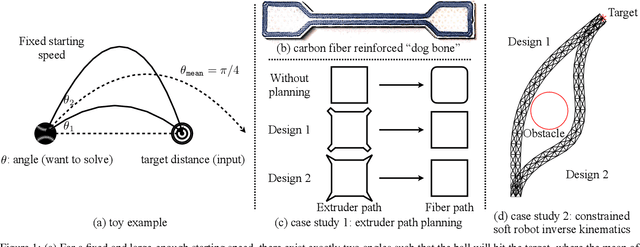

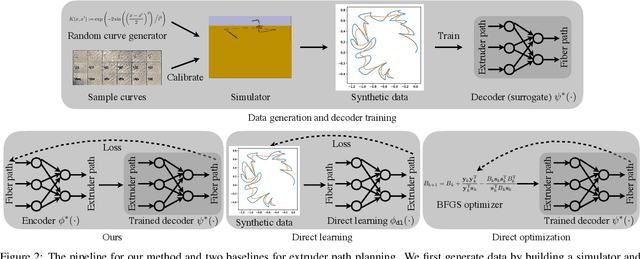
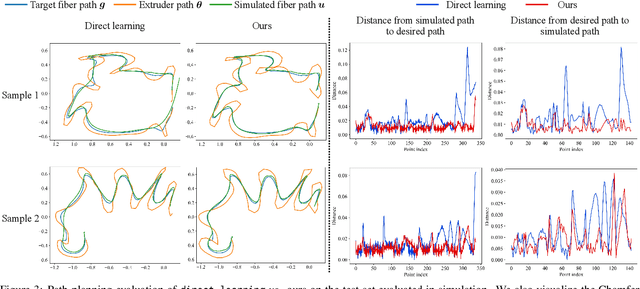
In design, fabrication, and control problems, we are often faced with the task of synthesis, in which we must generate an object or configuration that satisfies a set of constraints while maximizing one or more objective functions. The synthesis problem is typically characterized by a physical process in which many different realizations may achieve the goal. This many-to-one map presents challenges to the supervised learning of feed-forward synthesis, as the set of viable designs may have a complex structure. In addition, the non-differentiable nature of many physical simulations prevents direct optimization. We address both of these problems with a two-stage neural network architecture that we may consider to be an autoencoder. We first learn the decoder: a differentiable surrogate that approximates the many-to-one physical realization process. We then learn the encoder, which maps from goal to design, while using the fixed decoder to evaluate the quality of the realization. We evaluate the approach on two case studies: extruder path planning in additive manufacturing and constrained soft robot inverse kinematics. We compare our approach to direct optimization of design using the learned surrogate, and to supervised learning of the synthesis problem. We find that our approach produces higher quality solutions than supervised learning, while being competitive in quality with direct optimization, at a greatly reduced computational cost.
Spatial Intention Maps for Multi-Agent Mobile Manipulation
Mar 23, 2021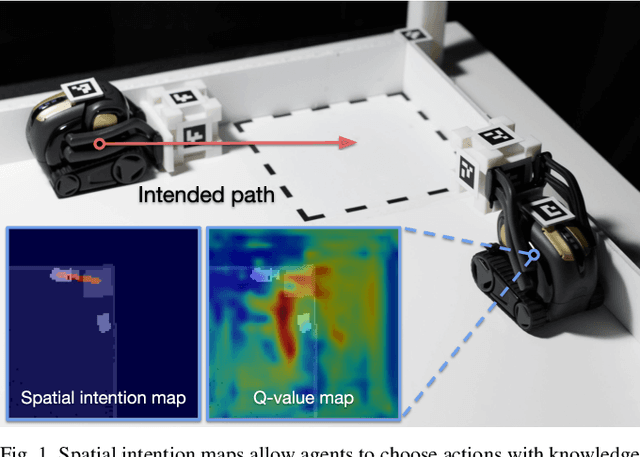
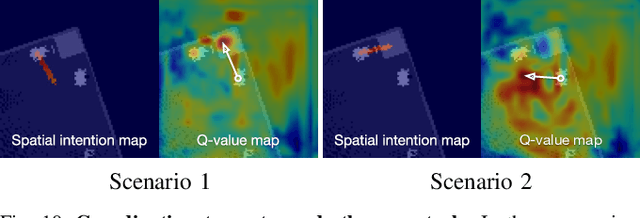
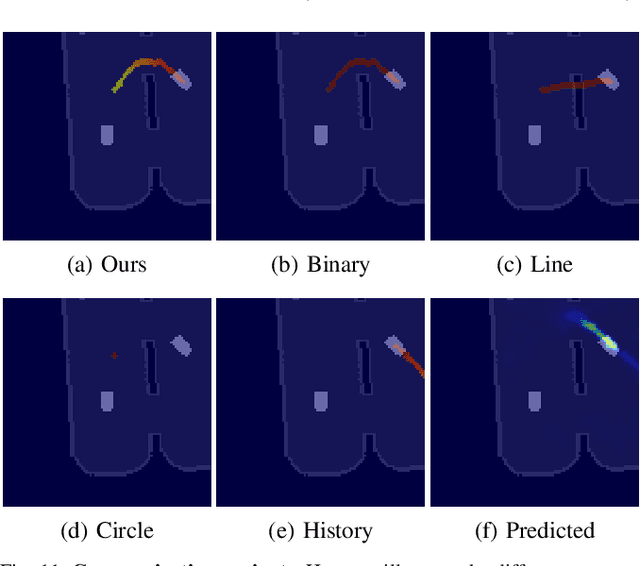
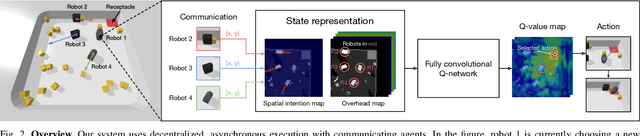
The ability to communicate intention enables decentralized multi-agent robots to collaborate while performing physical tasks. In this work, we present spatial intention maps, a new intention representation for multi-agent vision-based deep reinforcement learning that improves coordination between decentralized mobile manipulators. In this representation, each agent's intention is provided to other agents, and rendered into an overhead 2D map aligned with visual observations. This synergizes with the recently proposed spatial action maps framework, in which state and action representations are spatially aligned, providing inductive biases that encourage emergent cooperative behaviors requiring spatial coordination, such as passing objects to each other or avoiding collisions. Experiments across a variety of multi-agent environments, including heterogeneous robot teams with different abilities (lifting, pushing, or throwing), show that incorporating spatial intention maps improves performance for different mobile manipulation tasks while significantly enhancing cooperative behaviors.
Spatial Action Maps for Mobile Manipulation
Apr 20, 2020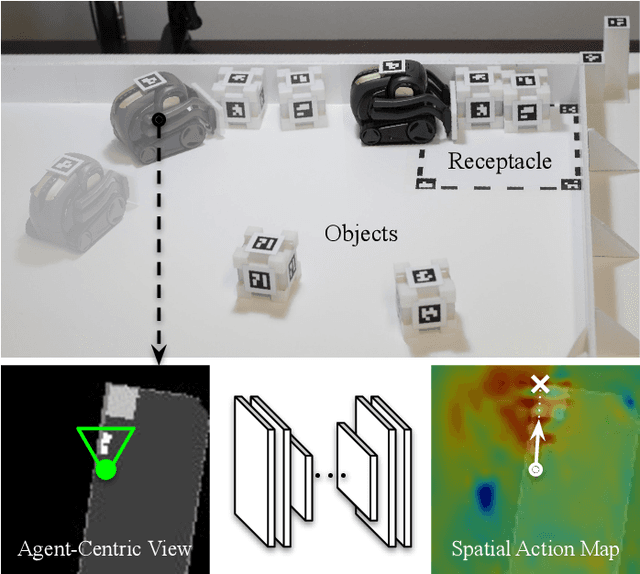


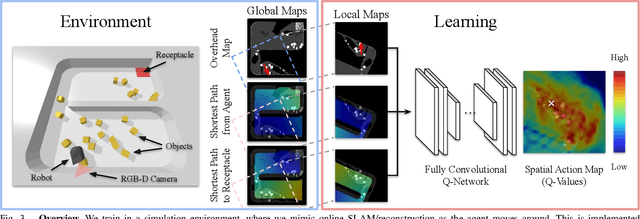
This paper proposes a new action representation for learning to perform complex mobile manipulation tasks. In a typical deep Q-learning setup, a convolutional neural network (ConvNet) is trained to map from an image representing the current state (e.g., a birds-eye view of a SLAM reconstruction of the scene) to predicted Q-values for a small set of steering command actions (step forward, turn right, turn left, etc.). Instead, we propose an action representation in the same domain as the state: "spatial action maps." In our proposal, the set of possible actions is represented by pixels of an image, where each pixel represents a trajectory to the corresponding scene location along a shortest path through obstacles of the partially reconstructed scene. A significant advantage of this approach is that the spatial position of each state-action value prediction represents a local milestone (local end-point) for the agent's policy, which may be easily recognizable in local visual patterns of the state image. A second advantage is that atomic actions can perform long-range plans (follow the shortest path to a point on the other side of the scene), and thus it is simpler to learn complex behaviors with a deep Q-network. A third advantage is that we can use a fully convolutional network (FCN) with skip connections to learn the mapping from state images to pixel-aligned action images efficiently. During experiments with a robot that learns to push objects to a goal location, we find that policies learned with this proposed action representation achieve significantly better performance than traditional alternatives.
A Generalized Algorithm for Multi-Objective Reinforcement Learning and Policy Adaptation
Aug 21, 2019
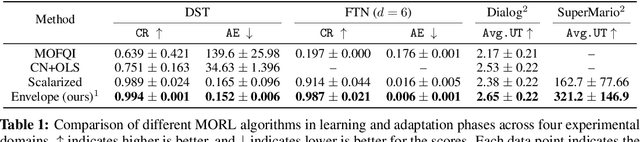
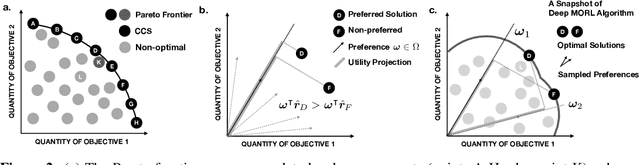

We introduce a new algorithm for multi-objective reinforcement learning (MORL) with linear preferences, with the goal of enabling few-shot adaptation to new tasks. In MORL, the aim is to learn policies over multiple competing objectives whose relative importance (preferences) is unknown to the agent. While this alleviates dependence on scalar reward design, the expected return of a policy can change significantly with varying preferences, making it challenging to learn a single model to produce optimal policies under different preference conditions. We propose a generalized version of the Bellman equation to learn a single parametric representation for optimal policies over the space of all possible preferences. After this initial learning phase, our agent can quickly adapt to any given preference, or automatically infer an underlying preference with very few samples. Experiments across four different domains demonstrate the effectiveness of our approach.
Learning to Infer and Execute 3D Shape Programs
Jan 09, 2019

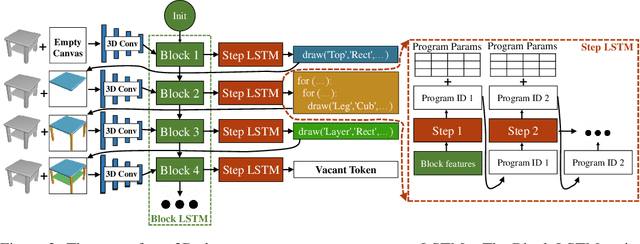
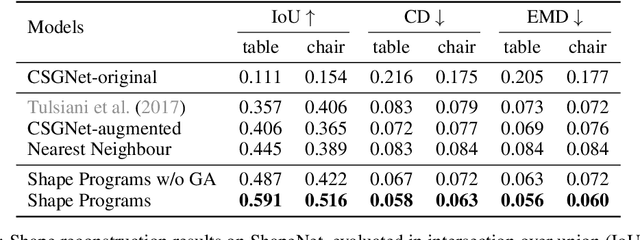
Human perception of 3D shapes goes beyond reconstructing them as a set of points or a composition of geometric primitives: we also effortlessly understand higher-level shape structure such as the repetition and reflective symmetry of object parts. In contrast, recent advances in 3D shape sensing focus more on low-level geometry but less on these higher-level relationships. In this paper, we propose 3D shape programs, integrating bottom-up recognition systems with top-down, symbolic program structure to capture both low-level geometry and high-level structural priors for 3D shapes. Because there are no annotations of shape programs for real shapes, we develop neural modules that not only learn to infer 3D shape programs from raw, unannotated shapes, but also to execute these programs for shape reconstruction. After initial bootstrapping, our end-to-end differentiable model learns 3D shape programs by reconstructing shapes in a self-supervised manner. Experiments demonstrate that our model accurately infers and executes 3D shape programs for highly complex shapes from various categories. It can also be integrated with an image-to-shape module to infer 3D shape programs directly from an RGB image, leading to 3D shape reconstructions that are both more accurate and more physically plausible.
3D Shape Perception from Monocular Vision, Touch, and Shape Priors
Aug 09, 2018
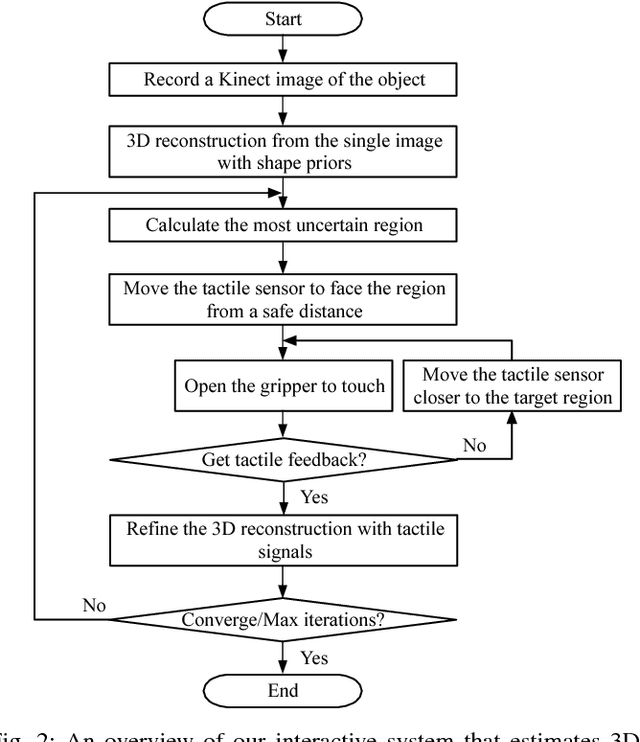
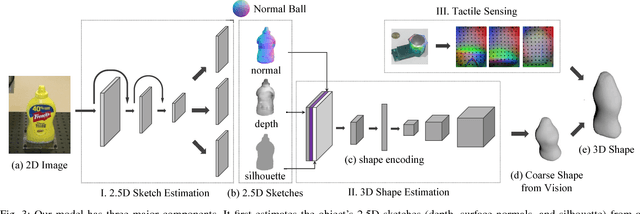

Perceiving accurate 3D object shape is important for robots to interact with the physical world. Current research along this direction has been primarily relying on visual observations. Vision, however useful, has inherent limitations due to occlusions and the 2D-3D ambiguities, especially for perception with a monocular camera. In contrast, touch gets precise local shape information, though its efficiency for reconstructing the entire shape could be low. In this paper, we propose a novel paradigm that efficiently perceives accurate 3D object shape by incorporating visual and tactile observations, as well as prior knowledge of common object shapes learned from large-scale shape repositories. We use vision first, applying neural networks with learned shape priors to predict an object's 3D shape from a single-view color image. We then use tactile sensing to refine the shape; the robot actively touches the object regions where the visual prediction has high uncertainty. Our method efficiently builds the 3D shape of common objects from a color image and a small number of tactile explorations (around 10). Our setup is easy to apply and has potentials to help robots better perform grasping or manipulation tasks on real-world objects.
Pix3D: Dataset and Methods for Single-Image 3D Shape Modeling
Apr 12, 2018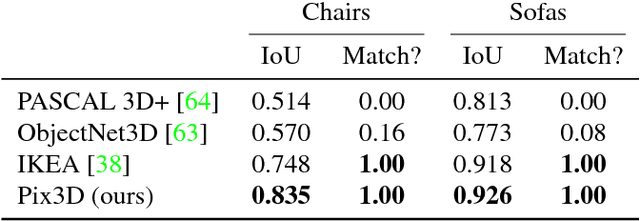
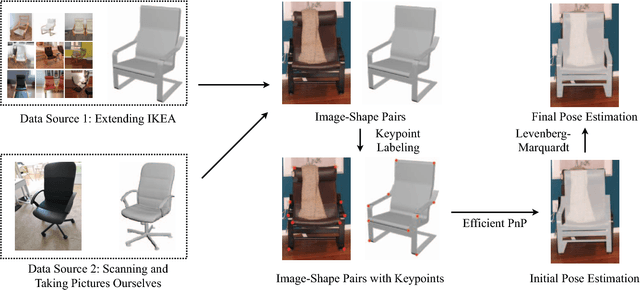
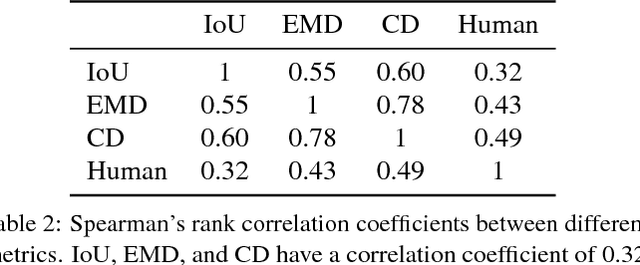

We study 3D shape modeling from a single image and make contributions to it in three aspects. First, we present Pix3D, a large-scale benchmark of diverse image-shape pairs with pixel-level 2D-3D alignment. Pix3D has wide applications in shape-related tasks including reconstruction, retrieval, viewpoint estimation, etc. Building such a large-scale dataset, however, is highly challenging; existing datasets either contain only synthetic data, or lack precise alignment between 2D images and 3D shapes, or only have a small number of images. Second, we calibrate the evaluation criteria for 3D shape reconstruction through behavioral studies, and use them to objectively and systematically benchmark cutting-edge reconstruction algorithms on Pix3D. Third, we design a novel model that simultaneously performs 3D reconstruction and pose estimation; our multi-task learning approach achieves state-of-the-art performance on both tasks.
MarrNet: 3D Shape Reconstruction via 2.5D Sketches
Nov 08, 2017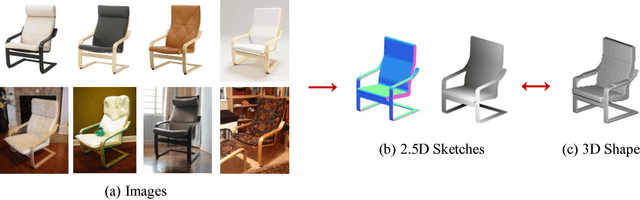
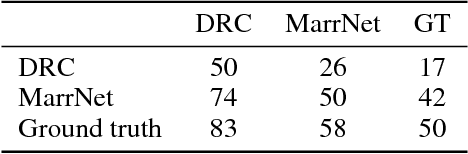
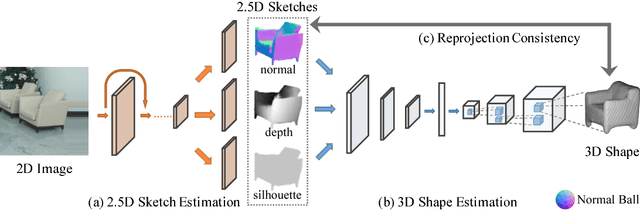
3D object reconstruction from a single image is a highly under-determined problem, requiring strong prior knowledge of plausible 3D shapes. This introduces challenges for learning-based approaches, as 3D object annotations are scarce in real images. Previous work chose to train on synthetic data with ground truth 3D information, but suffered from domain adaptation when tested on real data. In this work, we propose MarrNet, an end-to-end trainable model that sequentially estimates 2.5D sketches and 3D object shape. Our disentangled, two-step formulation has three advantages. First, compared to full 3D shape, 2.5D sketches are much easier to be recovered from a 2D image; models that recover 2.5D sketches are also more likely to transfer from synthetic to real data. Second, for 3D reconstruction from 2.5D sketches, systems can learn purely from synthetic data. This is because we can easily render realistic 2.5D sketches without modeling object appearance variations in real images, including lighting, texture, etc. This further relieves the domain adaptation problem. Third, we derive differentiable projective functions from 3D shape to 2.5D sketches; the framework is therefore end-to-end trainable on real images, requiring no human annotations. Our model achieves state-of-the-art performance on 3D shape reconstruction.