 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeC2AL: Cohort-Contrastive Auxiliary Learning for Large-scale Recommendation Systems
Oct 02, 2025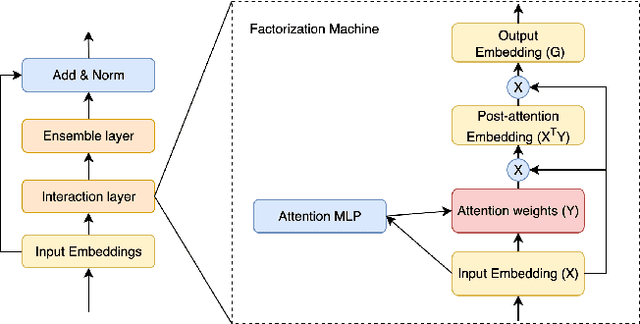
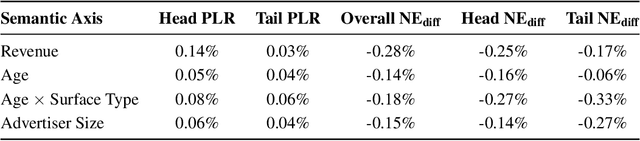
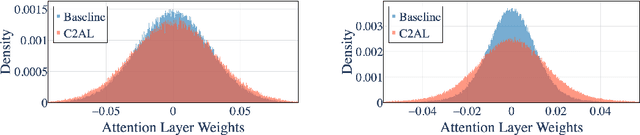

Training large-scale recommendation models under a single global objective implicitly assumes homogeneity across user populations. However, real-world data are composites of heterogeneous cohorts with distinct conditional distributions. As models increase in scale and complexity and as more data is used for training, they become dominated by central distribution patterns, neglecting head and tail regions. This imbalance limits the model's learning ability and can result in inactive attention weights or dead neurons. In this paper, we reveal how the attention mechanism can play a key role in factorization machines for shared embedding selection, and propose to address this challenge by analyzing the substructures in the dataset and exposing those with strong distributional contrast through auxiliary learning. Unlike previous research, which heuristically applies weighted labels or multi-task heads to mitigate such biases, we leverage partially conflicting auxiliary labels to regularize the shared representation. This approach customizes the learning process of attention layers to preserve mutual information with minority cohorts while improving global performance. We evaluated C2AL on massive production datasets with billions of data points each for six SOTA models. Experiments show that the factorization machine is able to capture fine-grained user-ad interactions using the proposed method, achieving up to a 0.16% reduction in normalized entropy overall and delivering gains exceeding 0.30% on targeted minority cohorts.
Towards end-to-end pulsed eddy current classification and regression with CNN
Feb 22, 2019
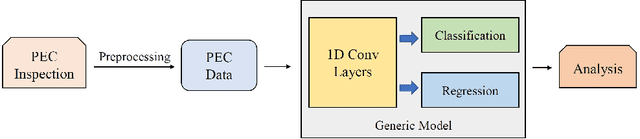
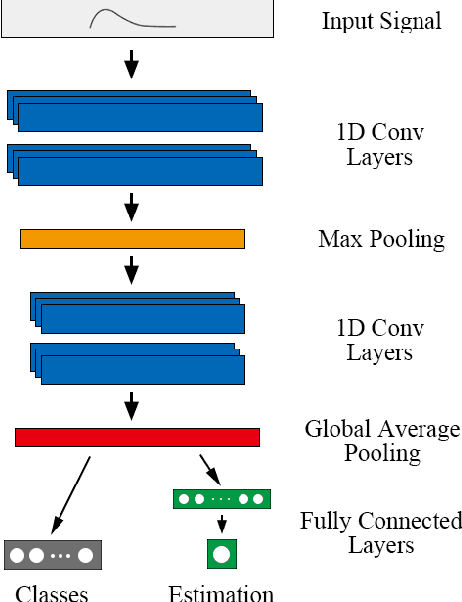
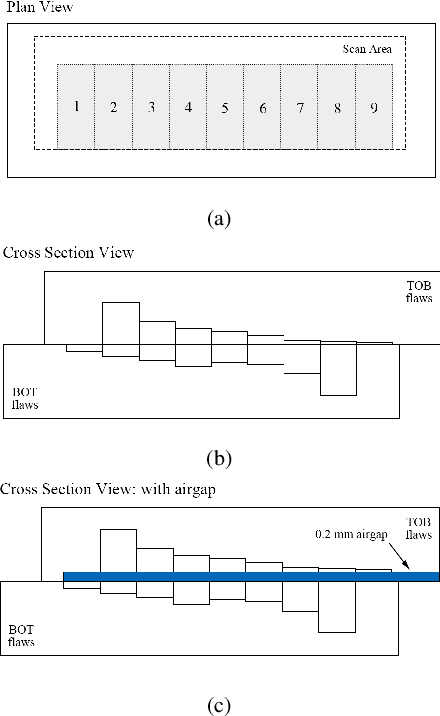
Pulsed eddy current (PEC) is an effective electromagnetic non-destructive inspection (NDI) technique for metal materials, which has already been widely adopted in detecting cracking and corrosion in some multi-layer structures. Automatically inspecting the defects in these structures would be conducive to further analysis and treatment of them. In this paper, we propose an effective end-to-end model using convolutional neural networks (CNN) to learn effective features from PEC data. Specifically, we construct a multi-task generic model, based on 1D CNN, to predict both the class and depth of flaws simultaneously. Extensive experiments demonstrate our model is capable of handling both classification and regression tasks on PEC data. Our proposed model obtains higher accuracy and lower error compared to other standard methods.
Learning to Reconstruct Shapes from Unseen Classes
Dec 28, 2018
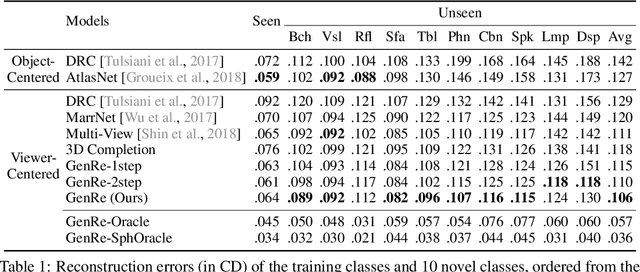


From a single image, humans are able to perceive the full 3D shape of an object by exploiting learned shape priors from everyday life. Contemporary single-image 3D reconstruction algorithms aim to solve this task in a similar fashion, but often end up with priors that are highly biased by training classes. Here we present an algorithm, Generalizable Reconstruction (GenRe), designed to capture more generic, class-agnostic shape priors. We achieve this with an inference network and training procedure that combine 2.5D representations of visible surfaces (depth and silhouette), spherical shape representations of both visible and non-visible surfaces, and 3D voxel-based representations, in a principled manner that exploits the causal structure of how 3D shapes give rise to 2D images. Experiments demonstrate that GenRe performs well on single-view shape reconstruction, and generalizes to diverse novel objects from categories not seen during training.
Visual Object Networks: Image Generation with Disentangled 3D Representation
Dec 06, 2018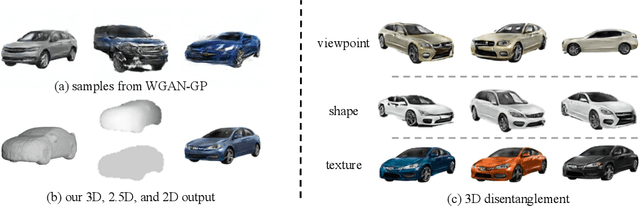
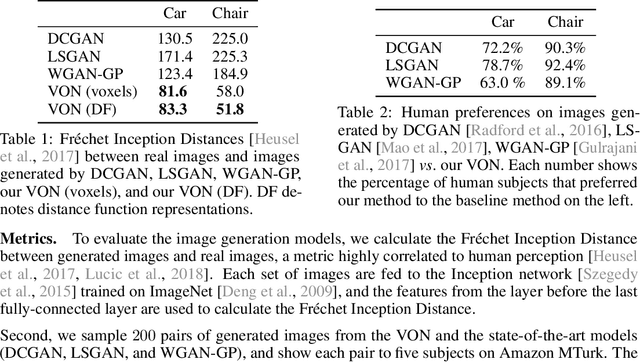
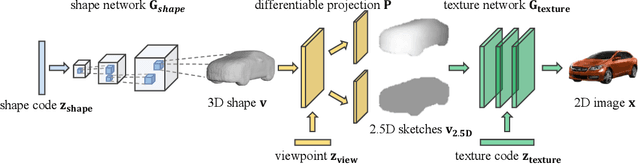

Recent progress in deep generative models has led to tremendous breakthroughs in image generation. However, while existing models can synthesize photorealistic images, they lack an understanding of our underlying 3D world. We present a new generative model, Visual Object Networks (VON), synthesizing natural images of objects with a disentangled 3D representation. Inspired by classic graphics rendering pipelines, we unravel our image formation process into three conditionally independent factors---shape, viewpoint, and texture---and present an end-to-end adversarial learning framework that jointly models 3D shapes and 2D images. Our model first learns to synthesize 3D shapes that are indistinguishable from real shapes. It then renders the object's 2.5D sketches (i.e., silhouette and depth map) from its shape under a sampled viewpoint. Finally, it learns to add realistic texture to these 2.5D sketches to generate natural images. The VON not only generates images that are more realistic than state-of-the-art 2D image synthesis methods, but also enables many 3D operations such as changing the viewpoint of a generated image, editing of shape and texture, linear interpolation in texture and shape space, and transferring appearance across different objects and viewpoints.
Learning Shape Priors for Single-View 3D Completion and Reconstruction
Sep 13, 2018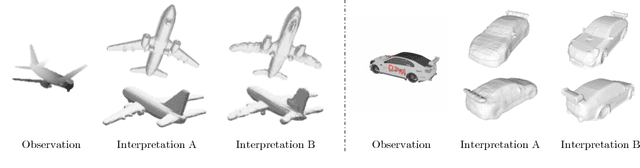


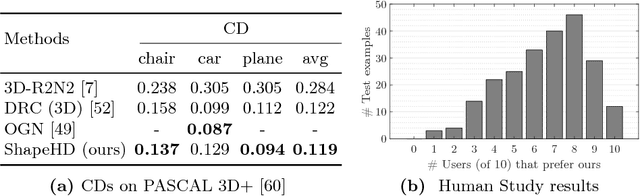
The problem of single-view 3D shape completion or reconstruction is challenging, because among the many possible shapes that explain an observation, most are implausible and do not correspond to natural objects. Recent research in the field has tackled this problem by exploiting the expressiveness of deep convolutional networks. In fact, there is another level of ambiguity that is often overlooked: among plausible shapes, there are still multiple shapes that fit the 2D image equally well; i.e., the ground truth shape is non-deterministic given a single-view input. Existing fully supervised approaches fail to address this issue, and often produce blurry mean shapes with smooth surfaces but no fine details. In this paper, we propose ShapeHD, pushing the limit of single-view shape completion and reconstruction by integrating deep generative models with adversarially learned shape priors. The learned priors serve as a regularizer, penalizing the model only if its output is unrealistic, not if it deviates from the ground truth. Our design thus overcomes both levels of ambiguity aforementioned. Experiments demonstrate that ShapeHD outperforms state of the art by a large margin in both shape completion and shape reconstruction on multiple real datasets.
Seeing Tree Structure from Vibration
Sep 13, 2018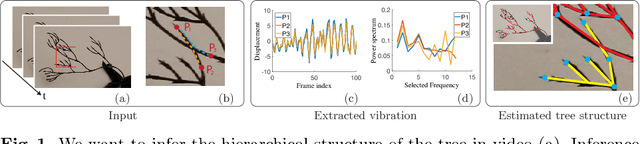
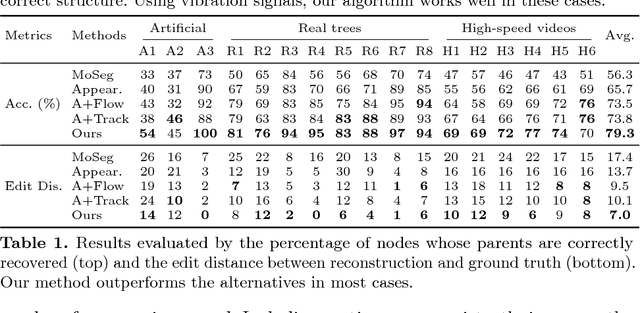
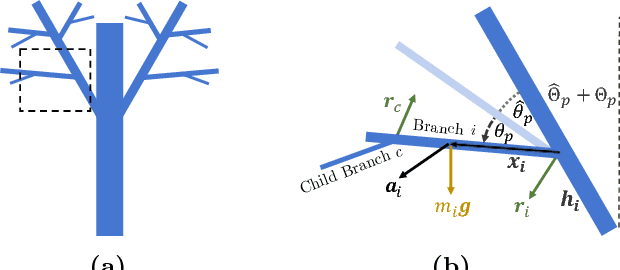
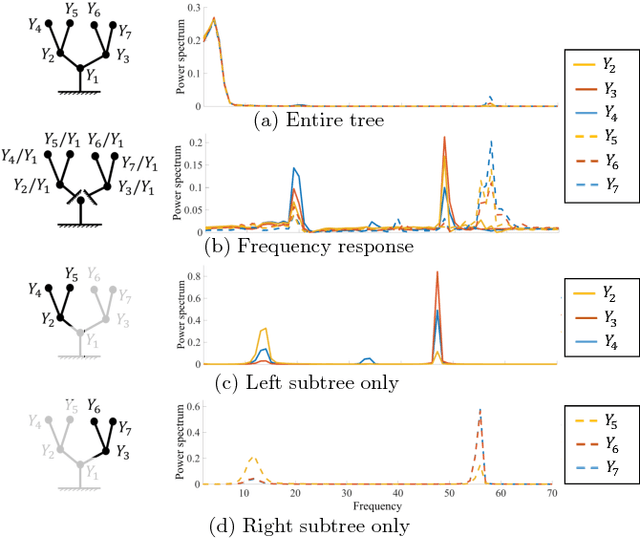
Humans recognize object structure from both their appearance and motion; often, motion helps to resolve ambiguities in object structure that arise when we observe object appearance only. There are particular scenarios, however, where neither appearance nor spatial-temporal motion signals are informative: occluding twigs may look connected and have almost identical movements, though they belong to different, possibly disconnected branches. We propose to tackle this problem through spectrum analysis of motion signals, because vibrations of disconnected branches, though visually similar, often have distinctive natural frequencies. We propose a novel formulation of tree structure based on a physics-based link model, and validate its effectiveness by theoretical analysis, numerical simulation, and empirical experiments. With this formulation, we use nonparametric Bayesian inference to reconstruct tree structure from both spectral vibration signals and appearance cues. Our model performs well in recognizing hierarchical tree structure from real-world videos of trees and vessels.
Pix3D: Dataset and Methods for Single-Image 3D Shape Modeling
Apr 12, 2018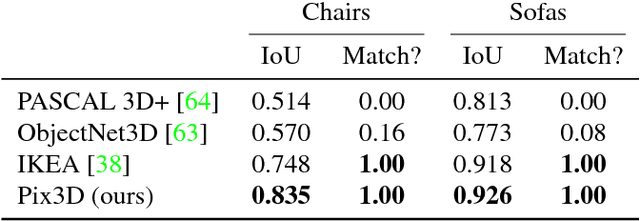
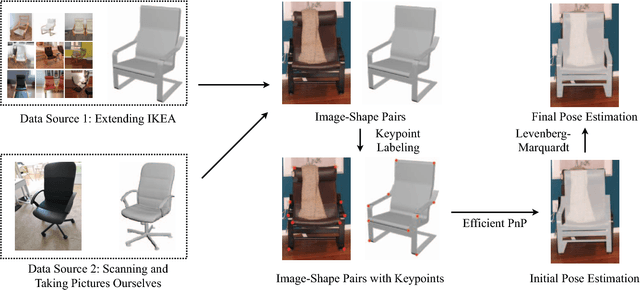
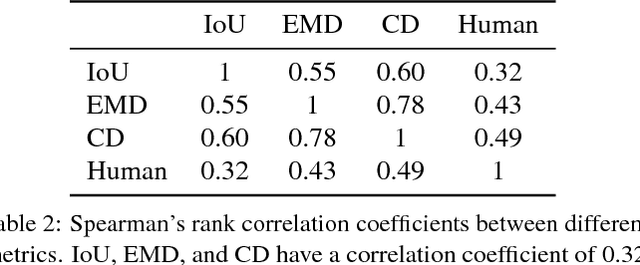

We study 3D shape modeling from a single image and make contributions to it in three aspects. First, we present Pix3D, a large-scale benchmark of diverse image-shape pairs with pixel-level 2D-3D alignment. Pix3D has wide applications in shape-related tasks including reconstruction, retrieval, viewpoint estimation, etc. Building such a large-scale dataset, however, is highly challenging; existing datasets either contain only synthetic data, or lack precise alignment between 2D images and 3D shapes, or only have a small number of images. Second, we calibrate the evaluation criteria for 3D shape reconstruction through behavioral studies, and use them to objectively and systematically benchmark cutting-edge reconstruction algorithms on Pix3D. Third, we design a novel model that simultaneously performs 3D reconstruction and pose estimation; our multi-task learning approach achieves state-of-the-art performance on both tasks.
Learning a Probabilistic Latent Space of Object Shapes via 3D Generative-Adversarial Modeling
Jan 04, 2017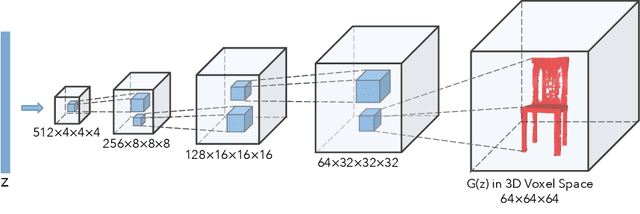


We study the problem of 3D object generation. We propose a novel framework, namely 3D Generative Adversarial Network (3D-GAN), which generates 3D objects from a probabilistic space by leveraging recent advances in volumetric convolutional networks and generative adversarial nets. The benefits of our model are three-fold: first, the use of an adversarial criterion, instead of traditional heuristic criteria, enables the generator to capture object structure implicitly and to synthesize high-quality 3D objects; second, the generator establishes a mapping from a low-dimensional probabilistic space to the space of 3D objects, so that we can sample objects without a reference image or CAD models, and explore the 3D object manifold; third, the adversarial discriminator provides a powerful 3D shape descriptor which, learned without supervision, has wide applications in 3D object recognition. Experiments demonstrate that our method generates high-quality 3D objects, and our unsupervisedly learned features achieve impressive performance on 3D object recognition, comparable with those of supervised learning methods.
A Comparative Evaluation of Approximate Probabilistic Simulation and Deep Neural Networks as Accounts of Human Physical Scene Understanding
Oct 04, 2016
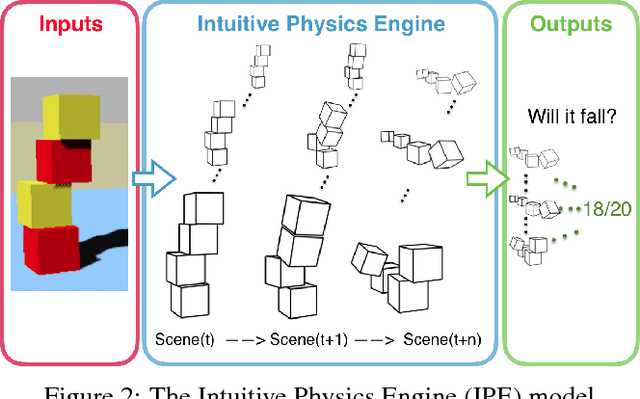
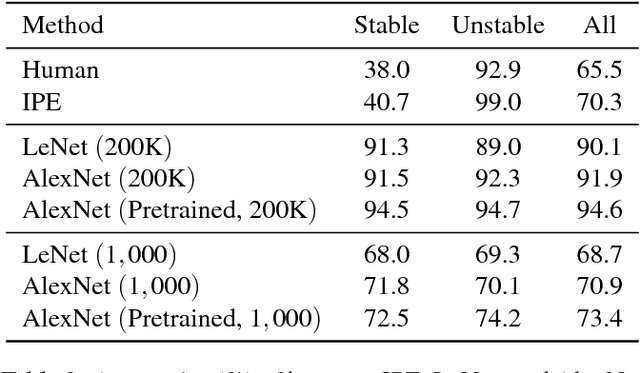
Humans demonstrate remarkable abilities to predict physical events in complex scenes. Two classes of models for physical scene understanding have recently been proposed: "Intuitive Physics Engines", or IPEs, which posit that people make predictions by running approximate probabilistic simulations in causal mental models similar in nature to video-game physics engines, and memory-based models, which make judgments based on analogies to stored experiences of previously encountered scenes and physical outcomes. Versions of the latter have recently been instantiated in convolutional neural network (CNN) architectures. Here we report four experiments that, to our knowledge, are the first rigorous comparisons of simulation-based and CNN-based models, where both approaches are concretely instantiated in algorithms that can run on raw image inputs and produce as outputs physical judgments such as whether a stack of blocks will fall. Both approaches can achieve super-human accuracy levels and can quantitatively predict human judgments to a similar degree, but only the simulation-based models generalize to novel situations in ways that people do, and are qualitatively consistent with systematic perceptual illusions and judgment asymmetries that people show.