 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparative Evaluation of Approximate Probabilistic Simulation and Deep Neural Networks as Accounts of Human Physical Scene Understanding
Oct 04, 2016
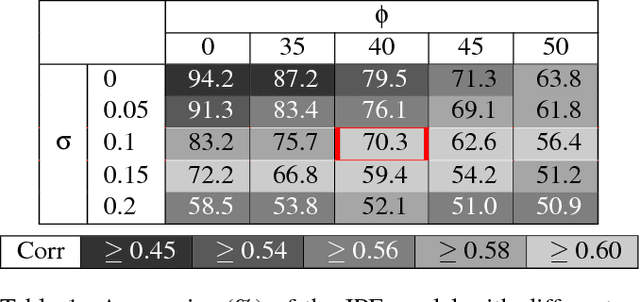
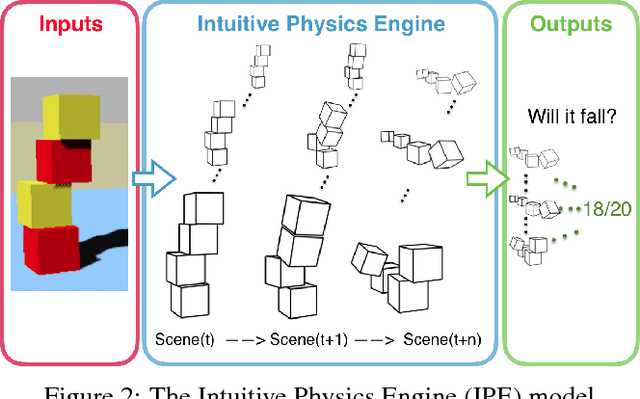
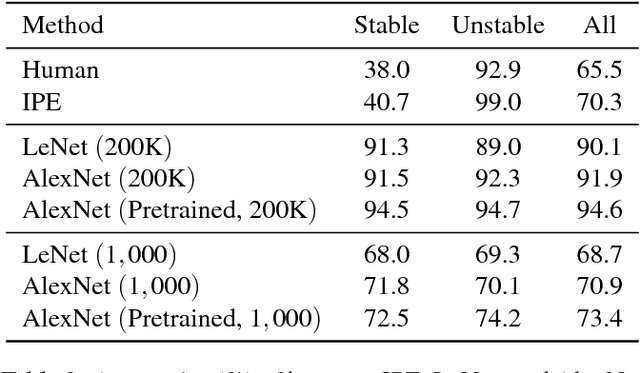
Humans demonstrate remarkable abilities to predict physical events in complex scenes. Two classes of models for physical scene understanding have recently been proposed: "Intuitive Physics Engines", or IPEs, which posit that people make predictions by running approximate probabilistic simulations in causal mental models similar in nature to video-game physics engines, and memory-based models, which make judgments based on analogies to stored experiences of previously encountered scenes and physical outcomes. Versions of the latter have recently been instantiated in convolutional neural network (CNN) architectures. Here we report four experiments that, to our knowledge, are the first rigorous comparisons of simulation-based and CNN-based models, where both approaches are concretely instantiated in algorithms that can run on raw image inputs and produce as outputs physical judgments such as whether a stack of blocks will fall. Both approaches can achieve super-human accuracy levels and can quantitatively predict human judgments to a similar degree, but only the simulation-based models generalize to novel situations in ways that people do, and are qualitatively consistent with systematic perceptual illusions and judgment asymmetries that people show.
Human and Sheep Facial Landmarks Localisation by Triplet Interpolated Features
Sep 16, 2015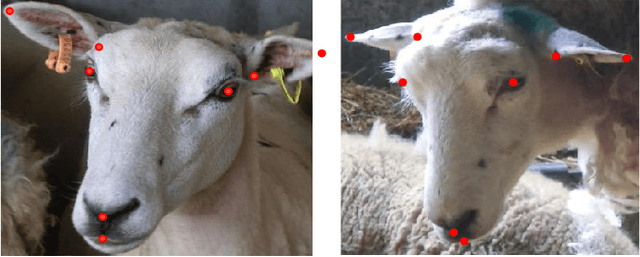

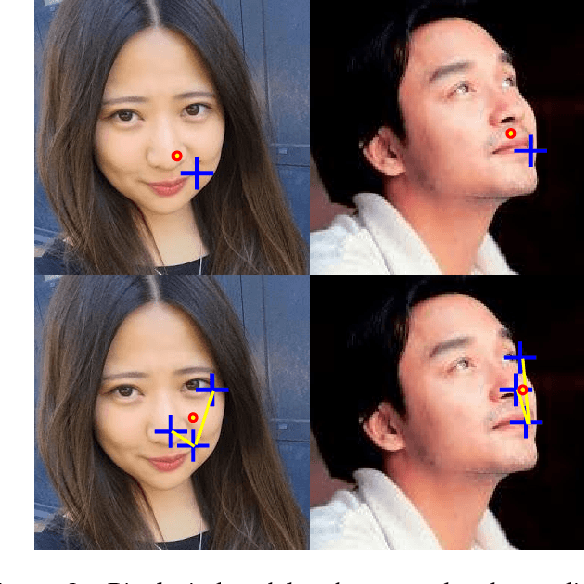
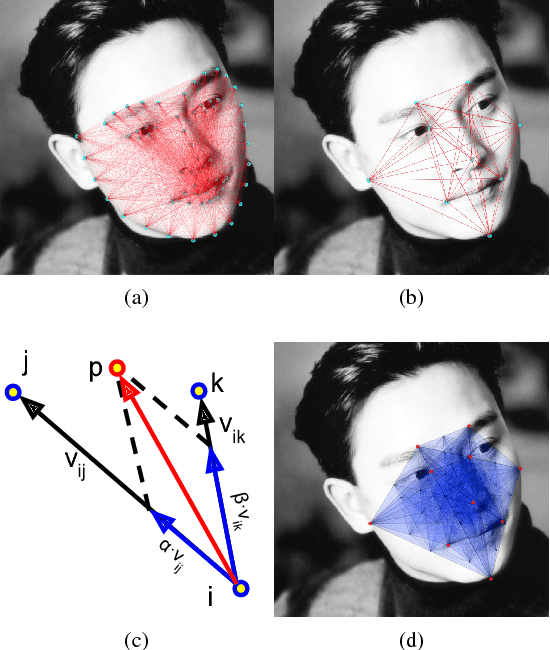
In this paper we present a method for localisation of facial landmarks on human and sheep. We introduce a new feature extraction scheme called triplet-interpolated feature used at each iteration of the cascaded shape regression framework. It is able to extract features from similar semantic location given an estimated shape, even when head pose variations are large and the facial landmarks are very sparsely distributed. Furthermore, we study the impact of training data imbalance on model performance and propose a training sample augmentation scheme that produces more initialisations for training samples from the minority. More specifically, the augmentation number for a training sample is made to be negatively correlated to the value of the fitted probability density function at the sample's position. We evaluate the proposed scheme on both human and sheep facial landmarks localisation. On the benchmark 300w human face dataset, we demonstrate the benefits of our proposed methods and show very competitive performance when comparing to other methods. On a newly created sheep face dataset, we get very good performance despite the fact that we only have a limited number of training samples and a set of sparse landmarks are annotated.