 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHet-node2vec: second order random walk sampling for heterogeneous multigraphs embedding
Jan 05, 2021

We introduce a set of algorithms (Het-node2vec) that extend the original node2vec node-neighborhood sampling method to heterogeneous multigraphs, i.e. networks characterized by multiple types of nodes and edges. The resulting random walk samples capture both the structural characteristics of the graph and the semantics of the different types of nodes and edges. The proposed algorithms can focus their attention on specific node or edge types, allowing accurate representations also for underrepresented types of nodes/edges that are of interest for the prediction problem under investigation. These rich and well-focused representations can boost unsupervised and supervised learning on heterogeneous graphs.
Merlin: Enabling Machine Learning-Ready HPC Ensembles
Dec 05, 2019
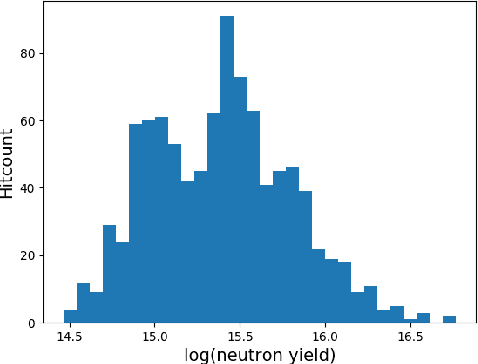
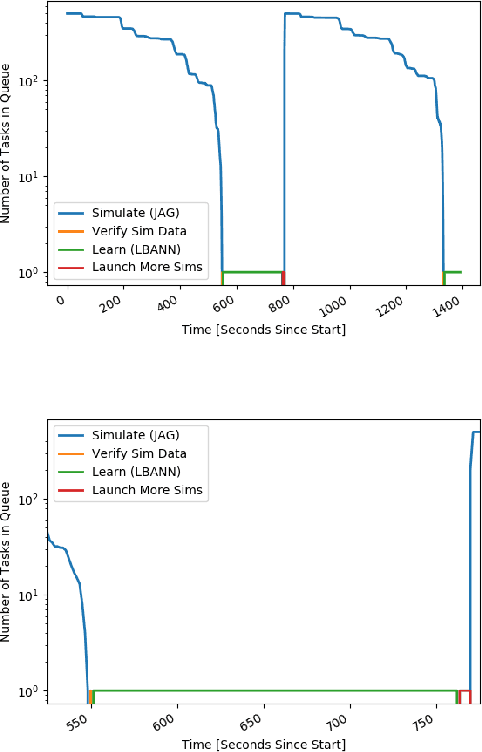
With the growing complexity of computational and experimental facilities, many scientific researchers are turning to machine learning (ML) techniques to analyze large scale ensemble data. With complexities such as multi-component workflows, heterogeneous machine architectures, parallel file systems, and batch scheduling, care must be taken to facilitate this analysis in a high performance computing (HPC) environment. In this paper, we present Merlin, a workflow framework to enable large ML-friendly ensembles of scientific HPC simulations. By augmenting traditional HPC with distributed compute technologies, Merlin aims to lower the barrier for scientific subject matter experts to incorporate ML into their analysis. In addition to its design and some examples, we describe how Merlin was deployed on the Sierra Supercomputer at Lawrence Livermore National Laboratory to create an unprecedented benchmark inertial confinement fusion dataset of approximately 100 million individual simulations and over 24 terabytes of multi-modal physics-based scalar, vector and hyperspectral image data.
Parallelizing Training of Deep Generative Models on Massive Scientific Datasets
Oct 05, 2019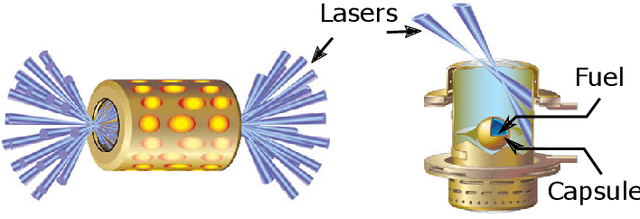
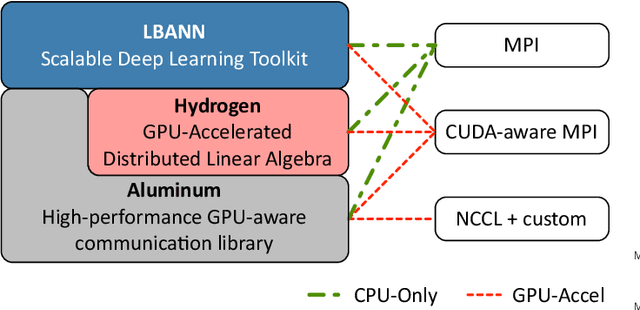
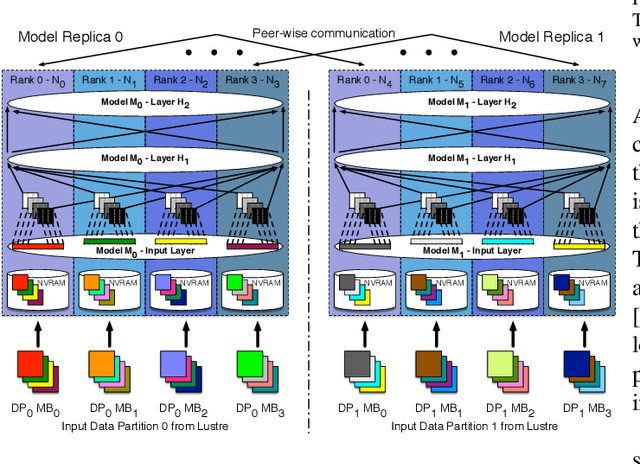
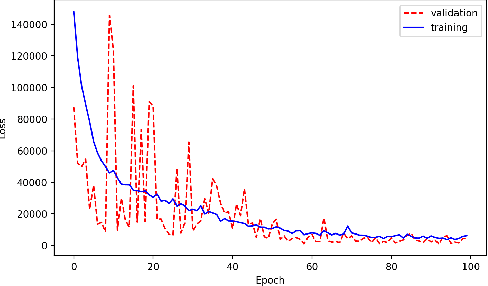
Training deep neural networks on large scientific data is a challenging task that requires enormous compute power, especially if no pre-trained models exist to initialize the process. We present a novel tournament method to train traditional as well as generative adversarial networks built on LBANN, a scalable deep learning framework optimized for HPC systems. LBANN combines multiple levels of parallelism and exploits some of the worlds largest supercomputers. We demonstrate our framework by creating a complex predictive model based on multi-variate data from high-energy-density physics containing hundreds of millions of images and hundreds of millions of scalar values derived from tens of millions of simulations of inertial confinement fusion. Our approach combines an HPC workflow and extends LBANN with optimized data ingestion and the new tournament-style training algorithm to produce a scalable neural network architecture using a CORAL-class supercomputer. Experimental results show that 64 trainers (1024 GPUs) achieve a speedup of 70.2 over a single trainer (16 GPUs) baseline, and an effective 109% parallel efficiency.
GazeDirector: Fully Articulated Eye Gaze Redirection in Video
Apr 27, 2017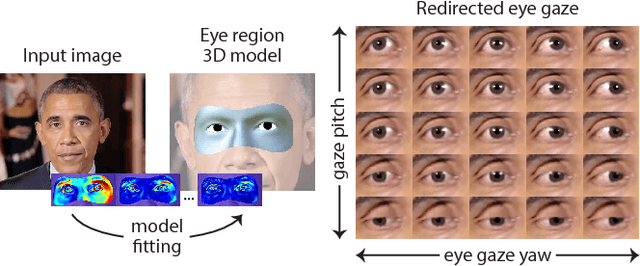

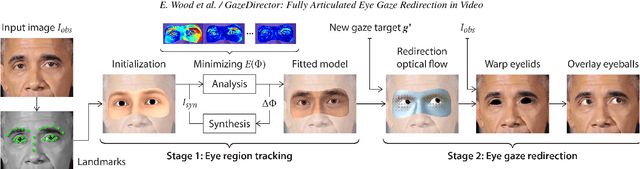
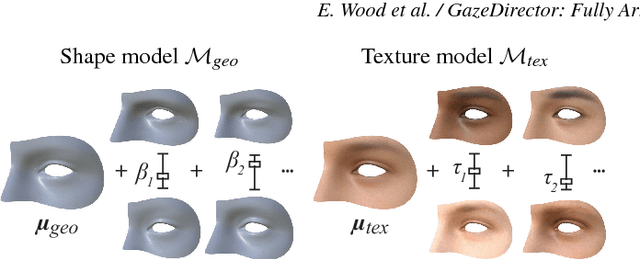
We present GazeDirector, a new approach for eye gaze redirection that uses model-fitting. Our method first tracks the eyes by fitting a multi-part eye region model to video frames using analysis-by-synthesis, thereby recovering eye region shape, texture, pose, and gaze simultaneously. It then redirects gaze by 1) warping the eyelids from the original image using a model-derived flow field, and 2) rendering and compositing synthesized 3D eyeballs onto the output image in a photorealistic manner. GazeDirector allows us to change where people are looking without person-specific training data, and with full articulation, i.e. we can precisely specify new gaze directions in 3D. Quantitatively, we evaluate both model-fitting and gaze synthesis, with experiments for gaze estimation and redirection on the Columbia gaze dataset. Qualitatively, we compare GazeDirector against recent work on gaze redirection, showing better results especially for large redirection angles. Finally, we demonstrate gaze redirection on YouTube videos by introducing new 3D gaze targets and by manipulating visual behavior.
An Empirical Study of Recent Face Alignment Methods
Nov 16, 2015


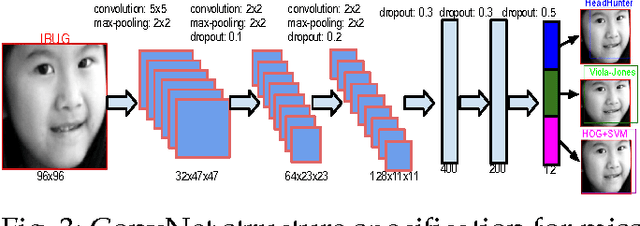
The problem of face alignment has been intensively studied in the past years. A large number of novel methods have been proposed and reported very good performance on benchmark dataset such as 300W. However, the differences in the experimental setting and evaluation metric, missing details in the description of the methods make it hard to reproduce the results reported and evaluate the relative merits. For instance, most recent face alignment methods are built on top of face detection but from different face detectors. In this paper, we carry out a rigorous evaluation of these methods by making the following contributions: 1) we proposes a new evaluation metric for face alignment on a set of images, i.e., area under error distribution curve within a threshold, AUC$_\alpha$, given the fact that the traditional evaluation measure (mean error) is very sensitive to big alignment error. 2) we extend the 300W database with more practical face detections to make fair comparison possible. 3) we carry out face alignment sensitivity analysis w.r.t. face detection, on both synthetic and real data, using both off-the-shelf and re-retrained models. 4) we study factors that are particularly important to achieve good performance and provide suggestions for practical applications. Most of the conclusions drawn from our comparative analysis cannot be inferred from the original publications.
Human and Sheep Facial Landmarks Localisation by Triplet Interpolated Features
Sep 16, 2015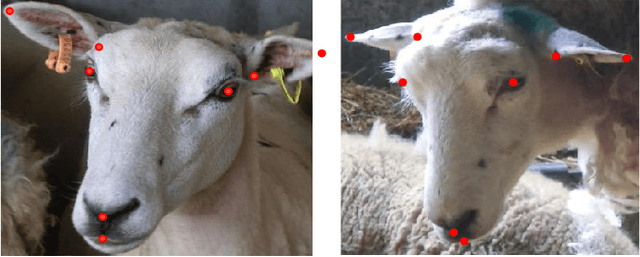

In this paper we present a method for localisation of facial landmarks on human and sheep. We introduce a new feature extraction scheme called triplet-interpolated feature used at each iteration of the cascaded shape regression framework. It is able to extract features from similar semantic location given an estimated shape, even when head pose variations are large and the facial landmarks are very sparsely distributed. Furthermore, we study the impact of training data imbalance on model performance and propose a training sample augmentation scheme that produces more initialisations for training samples from the minority. More specifically, the augmentation number for a training sample is made to be negatively correlated to the value of the fitted probability density function at the sample's position. We evaluate the proposed scheme on both human and sheep facial landmarks localisation. On the benchmark 300w human face dataset, we demonstrate the benefits of our proposed methods and show very competitive performance when comparing to other methods. On a newly created sheep face dataset, we get very good performance despite the fact that we only have a limited number of training samples and a set of sparse landmarks are annotated.
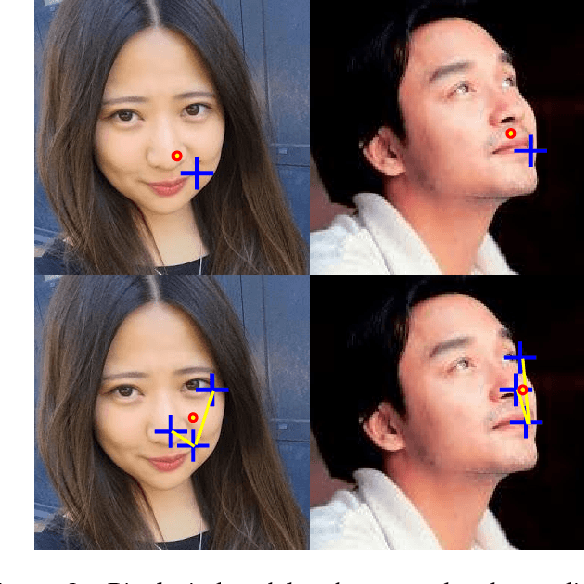
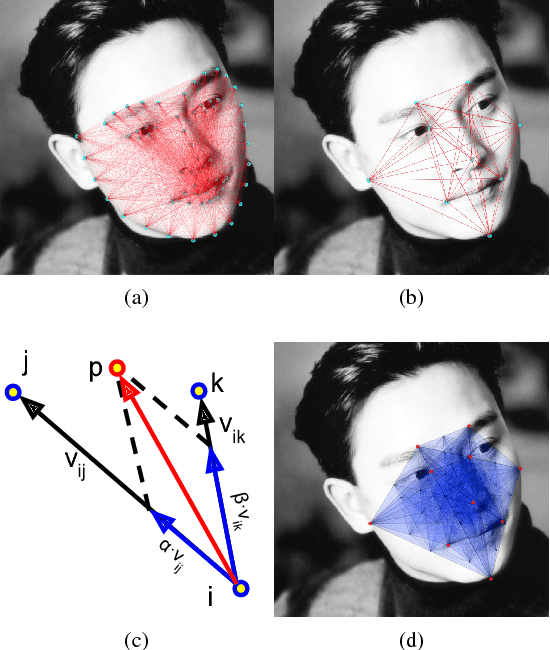
Face Alignment Assisted by Head Pose Estimation
Jul 18, 2015

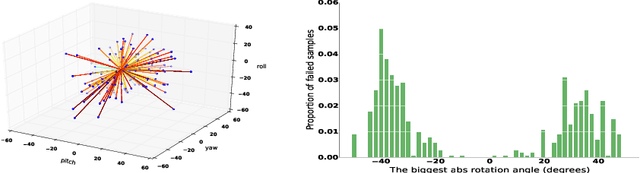
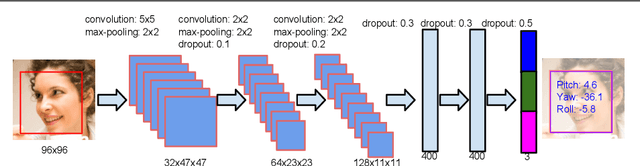
In this paper we propose a supervised initialization scheme for cascaded face alignment based on explicit head pose estimation. We first investigate the failure cases of most state of the art face alignment approaches and observe that these failures often share one common global property, i.e. the head pose variation is usually large. Inspired by this, we propose a deep convolutional network model for reliable and accurate head pose estimation. Instead of using a mean face shape, or randomly selected shapes for cascaded face alignment initialisation, we propose two schemes for generating initialisation: the first one relies on projecting a mean 3D face shape (represented by 3D facial landmarks) onto 2D image under the estimated head pose; the second one searches nearest neighbour shapes from the training set according to head pose distance. By doing so, the initialisation gets closer to the actual shape, which enhances the possibility of convergence and in turn improves the face alignment performance. We demonstrate the proposed method on the benchmark 300W dataset and show very competitive performance in both head pose estimation and face alignment.
Rendering of Eyes for Eye-Shape Registration and Gaze Estimation
May 21, 2015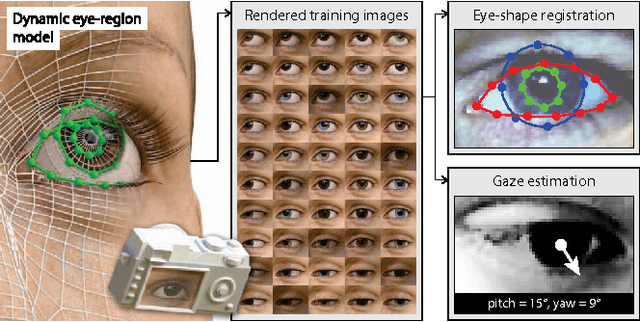


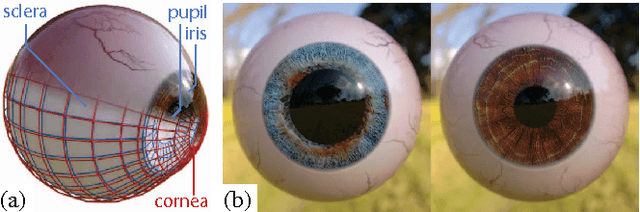
Images of the eye are key in several computer vision problems, such as shape registration and gaze estimation. Recent large-scale supervised methods for these problems require time-consuming data collection and manual annotation, which can be unreliable. We propose synthesizing perfectly labelled photo-realistic training data in a fraction of the time. We used computer graphics techniques to build a collection of dynamic eye-region models from head scan geometry. These were randomly posed to synthesize close-up eye images for a wide range of head poses, gaze directions, and illumination conditions. We used our model's controllability to verify the importance of realistic illumination and shape variations in eye-region training data. Finally, we demonstrate the benefits of our synthesized training data (SynthesEyes) by out-performing state-of-the-art methods for eye-shape registration as well as cross-dataset appearance-based gaze estimation in the wild.
The state of play of ASC-Inclusion: An Integrated Internet-Based Environment for Social Inclusion of Children with Autism Spectrum Conditions
Mar 24, 2014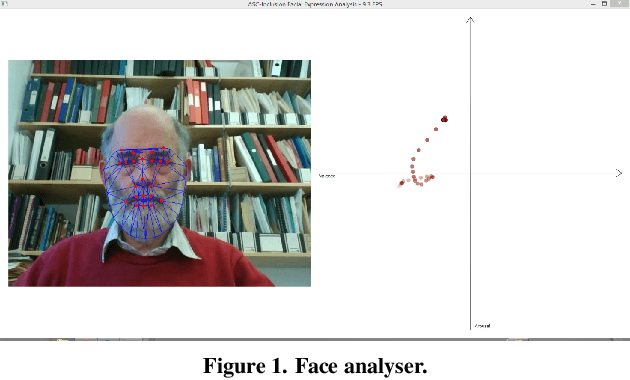
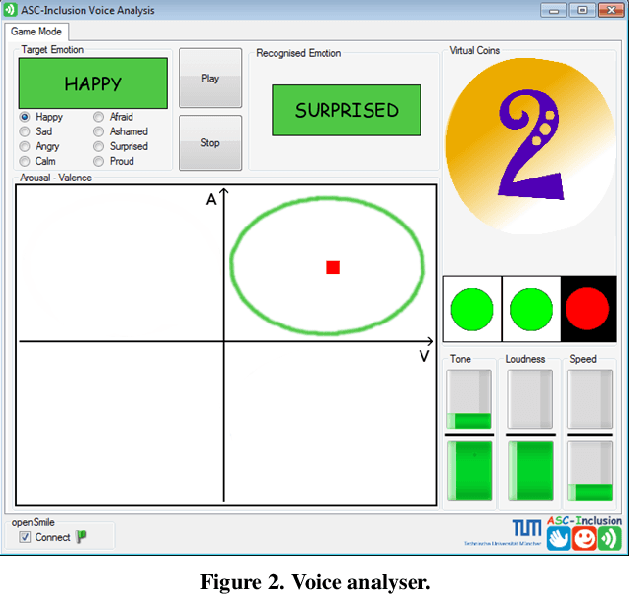

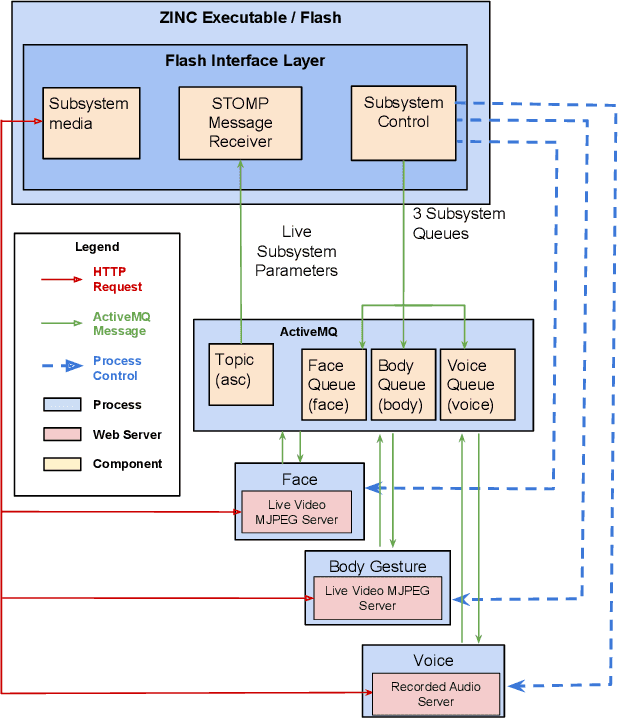
Individuals with Autism Spectrum Conditions (ASC) have marked difficulties using verbal and non-verbal communication for social interaction. The running ASC-Inclusion project aims to help children with ASC by allowing them to learn how emotions can be expressed and recognised via playing games in a virtual world. The platform includes analysis of users' gestures, facial, and vocal expressions using standard microphone and web-cam or a depth sensor, training through games, text communication with peers, animation, video and audio clips. We present the state of play in realising such a serious game platform and provide results for the different modalities.