 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Would You Trust a Robot? A Study on Trust and Theory of Mind in Human-Robot Interactions
Jan 26, 2021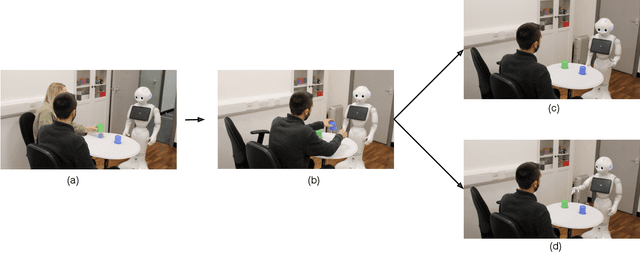


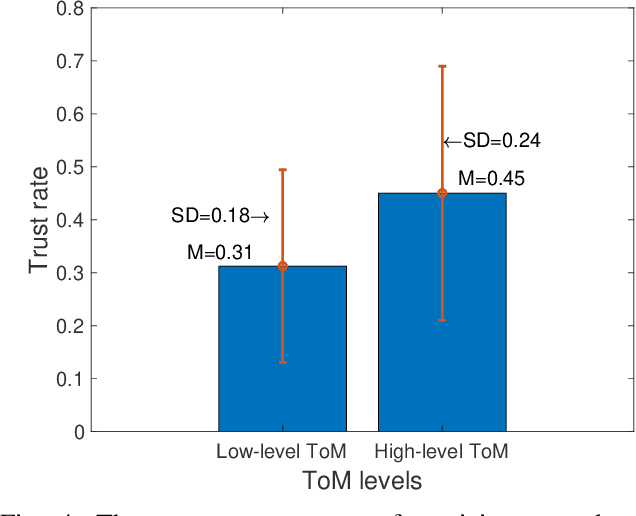
Trust is a critical issue in Human Robot Interactions as it is the core of human desire to accept and use a non human agent. Theory of Mind has been defined as the ability to understand the beliefs and intentions of others that may differ from one's own. Evidences in psychology and HRI suggest that trust and Theory of Mind are interconnected and interdependent concepts, as the decision to trust another agent must depend on our own representation of this entity's actions, beliefs and intentions. However, very few works take Theory of Mind of the robot into consideration while studying trust in HRI. In this paper, we investigated whether the exposure to the Theory of Mind abilities of a robot could affect humans' trust towards the robot. To this end, participants played a Price Game with a humanoid robot that was presented having either low level Theory of Mind or high level Theory of Mind. Specifically, the participants were asked to accept the price evaluations on common objects presented by the robot. The willingness of the participants to change their own price judgement of the objects (i.e., accept the price the robot suggested) was used as the main measurement of the trust towards the robot. Our experimental results showed that robots possessing a high level of Theory of Mind abilities were trusted more than the robots presented with low level Theory of Mind skills.
LUVLi Face Alignment: Estimating Landmarks' Location, Uncertainty, and Visibility Likelihood
Apr 06, 2020
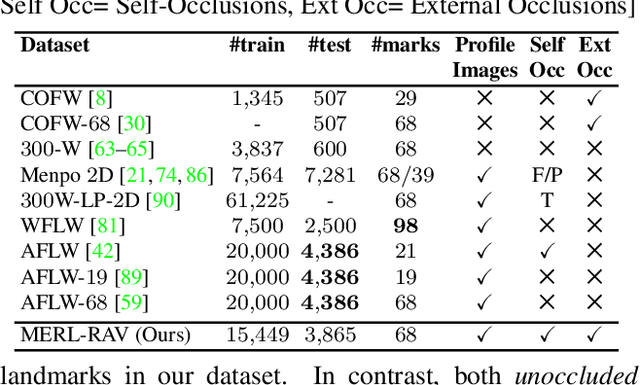
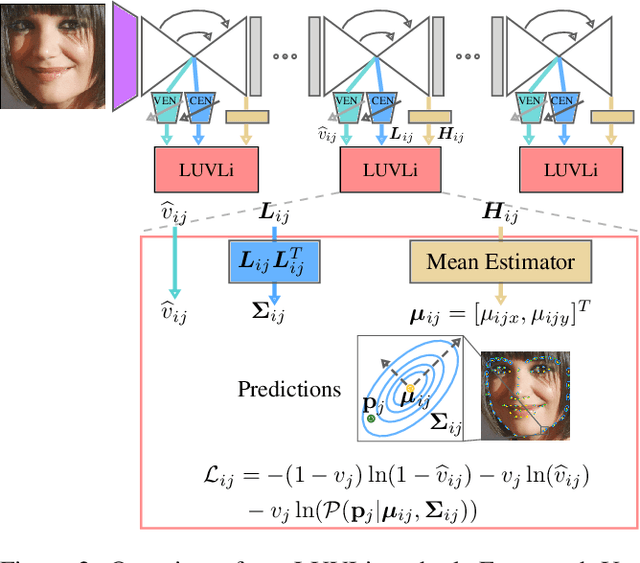

Modern face alignment methods have become quite accurate at predicting the locations of facial landmarks, but they do not typically estimate the uncertainty of their predicted locations nor predict whether landmarks are visible. In this paper, we present a novel framework for jointly predicting landmark locations, associated uncertainties of these predicted locations, and landmark visibilities. We model these as mixed random variables and estimate them using a deep network trained with our proposed Location, Uncertainty, and Visibility Likelihood (LUVLi) loss. In addition, we release an entirely new labeling of a large face alignment dataset with over 19,000 face images in a full range of head poses. Each face is manually labeled with the ground-truth locations of 68 landmarks, with the additional information of whether each landmark is unoccluded, self-occluded (due to extreme head poses), or externally occluded. Not only does our joint estimation yield accurate estimates of the uncertainty of predicted landmark locations, but it also yields state-of-the-art estimates for the landmark locations themselves on multiple standard face alignment datasets. Our method's estimates of the uncertainty of predicted landmark locations could be used to automatically identify input images on which face alignment fails, which can be critical for downstream tasks.
iCLAP: Shape Recognition by Combining Proprioception and Touch Sensing
Jun 19, 2018


For humans, both the proprioception and touch sensing are highly utilized when performing haptic perception. However, most approaches in robotics use only either proprioceptive data or touch data in haptic object recognition. In this paper, we present a novel method named Iterative Closest Labeled Point (iCLAP) to link the kinesthetic cues and tactile patterns fundamentally and also introduce its extensions to recognize object shapes. In the training phase, the iCLAP first clusters the features of tactile readings into a codebook and assigns these features with distinct label numbers. A 4D point cloud of the object is then formed by taking the label numbers of the tactile features as an additional dimension to the 3D sensor positions; hence, the two sensing modalities are merged to achieve a synthesized perception of the touched object. Furthermore, we developed and validated hybrid fusion strategies, product based and weighted sum based, to combine decisions obtained from iCLAP and single sensing modalities. Extensive experimentation demonstrates a dramatic improvement of object recognition using the proposed methods and it shows great potential to enhance robot perception ability.
Localizing the Object Contact through Matching Tactile Features with Visual Map
Aug 15, 2017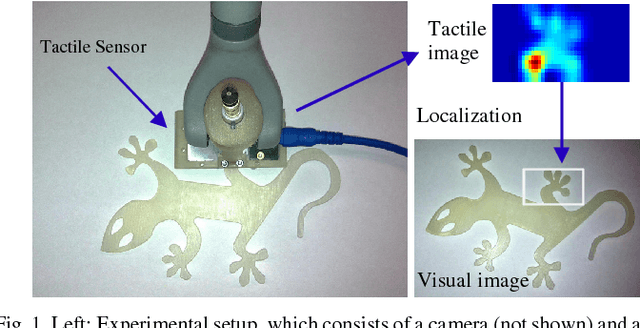
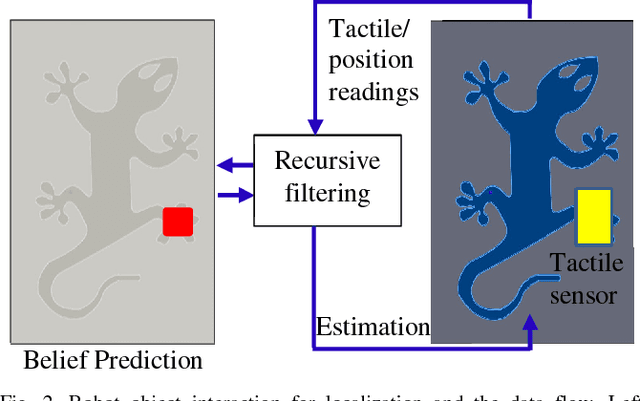
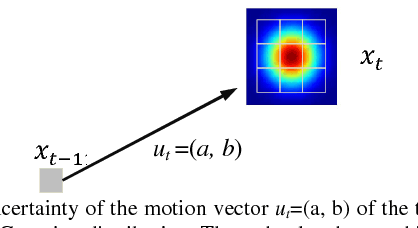
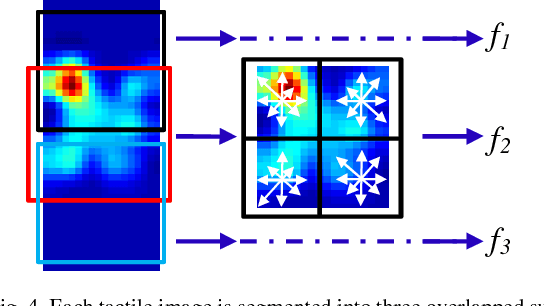
This paper presents a novel framework for integration of vision and tactile sensing by localizing tactile readings in a visual object map. Intuitively, there are some correspondences, e.g., prominent features, between visual and tactile object identification. To apply it in robotics, we propose to localize tactile readings in visual images by sharing same sets of feature descriptors through two sensing modalities. It is then treated as a probabilistic estimation problem solved in a framework of recursive Bayesian filtering. Feature-based measurement model and Gaussian based motion model are thus built. In our tests, a tactile array sensor is utilized to generate tactile images during interaction with objects and the results have proven the feasibility of our proposed framework.
* 6 pages, 8 figures, ICRA 2015
Iterative Closest Labeled Point for Tactile Object Shape Recognition
Aug 15, 2017



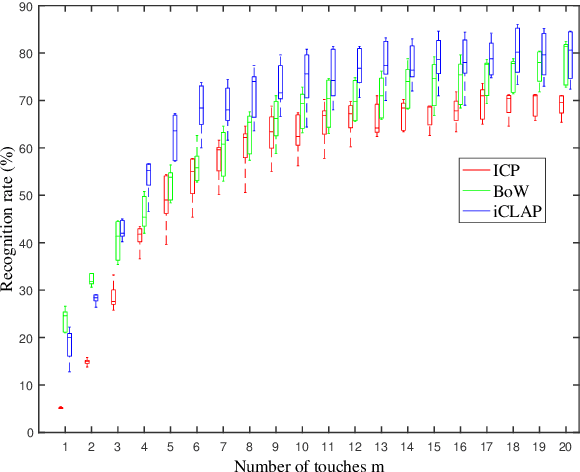
Tactile data and kinesthetic cues are two important sensing sources in robot object recognition and are complementary to each other. In this paper, we propose a novel algorithm named Iterative Closest Labeled Point (iCLAP) to recognize objects using both tactile and kinesthetic information.The iCLAP first assigns different local tactile features with distinct label numbers. The label numbers of the tactile features together with their associated 3D positions form a 4D point cloud of the object. In this manner, the two sensing modalities are merged to form a synthesized perception of the touched object. To recognize an object, the partial 4D point cloud obtained from a number of touches iteratively matches with all the reference cloud models to identify the best fit. An extensive evaluation study with 20 real objects shows that our proposed iCLAP approach outperforms those using either of the separate sensing modalities, with a substantial recognition rate improvement of up to 18%.
Face Alignment Assisted by Head Pose Estimation
Jul 18, 2015

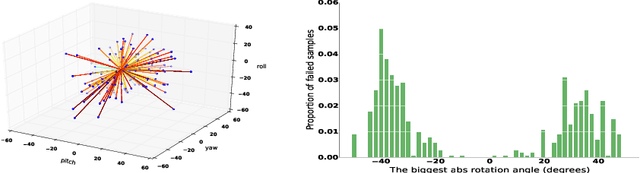
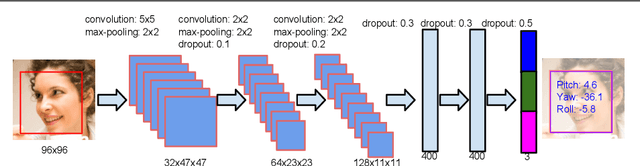
In this paper we propose a supervised initialization scheme for cascaded face alignment based on explicit head pose estimation. We first investigate the failure cases of most state of the art face alignment approaches and observe that these failures often share one common global property, i.e. the head pose variation is usually large. Inspired by this, we propose a deep convolutional network model for reliable and accurate head pose estimation. Instead of using a mean face shape, or randomly selected shapes for cascaded face alignment initialisation, we propose two schemes for generating initialisation: the first one relies on projecting a mean 3D face shape (represented by 3D facial landmarks) onto 2D image under the estimated head pose; the second one searches nearest neighbour shapes from the training set according to head pose distance. By doing so, the initialisation gets closer to the actual shape, which enhances the possibility of convergence and in turn improves the face alignment performance. We demonstrate the proposed method on the benchmark 300W dataset and show very competitive performance in both head pose estimation and face alignment.