 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSELMA: A Speech-Enabled Language Model for Virtual Assistant Interactions
Jan 31, 2025In this work, we present and evaluate SELMA, a Speech-Enabled Language Model for virtual Assistant interactions that integrates audio and text as inputs to a Large Language Model (LLM). SELMA is designed to handle three primary and two auxiliary tasks related to interactions with virtual assistants simultaneously within a single end-to-end model. We employ low-rank adaptation modules for parameter-efficient training of both the audio encoder and the LLM. Additionally, we implement a feature pooling strategy enabling the system to recognize global patterns and improve accuracy on tasks less reliant on individual sequence elements. Experimental results on Voice Trigger (VT) detection, Device-Directed Speech Detection (DDSD), and Automatic Speech Recognition (ASR), demonstrate that our approach both simplifies the typical input processing pipeline of virtual assistants significantly and also improves performance compared to dedicated models for each individual task. SELMA yields relative Equal-Error Rate improvements of 64% on the VT detection task, and 22% on DDSD, while also achieving word error rates close to the baseline.
A Multimodal Approach to Device-Directed Speech Detection with Large Language Models
Mar 26, 2024Interactions with virtual assistants typically start with a predefined trigger phrase followed by the user command. To make interactions with the assistant more intuitive, we explore whether it is feasible to drop the requirement that users must begin each command with a trigger phrase. We explore this task in three ways: First, we train classifiers using only acoustic information obtained from the audio waveform. Second, we take the decoder outputs of an automatic speech recognition (ASR) system, such as 1-best hypotheses, as input features to a large language model (LLM). Finally, we explore a multimodal system that combines acoustic and lexical features, as well as ASR decoder signals in an LLM. Using multimodal information yields relative equal-error-rate improvements over text-only and audio-only models of up to 39% and 61%. Increasing the size of the LLM and training with low-rank adaption leads to further relative EER reductions of up to 18% on our dataset.
Multimodal Data and Resource Efficient Device-Directed Speech Detection with Large Foundation Models
Dec 06, 2023Interactions with virtual assistants typically start with a trigger phrase followed by a command. In this work, we explore the possibility of making these interactions more natural by eliminating the need for a trigger phrase. Our goal is to determine whether a user addressed the virtual assistant based on signals obtained from the streaming audio recorded by the device microphone. We address this task by combining 1-best hypotheses and decoder signals from an automatic speech recognition system with acoustic representations from an audio encoder as input features to a large language model (LLM). In particular, we are interested in data and resource efficient systems that require only a small amount of training data and can operate in scenarios with only a single frozen LLM available on a device. For this reason, our model is trained on 80k or less examples of multimodal data using a combination of low-rank adaptation and prefix tuning. We compare the proposed system to unimodal baselines and show that the multimodal approach achieves lower equal-error-rates (EERs), while using only a fraction of the training data. We also show that low-dimensional specialized audio representations lead to lower EERs than high-dimensional general audio representations.
Improving Voice Trigger Detection with Metric Learning
Apr 05, 2022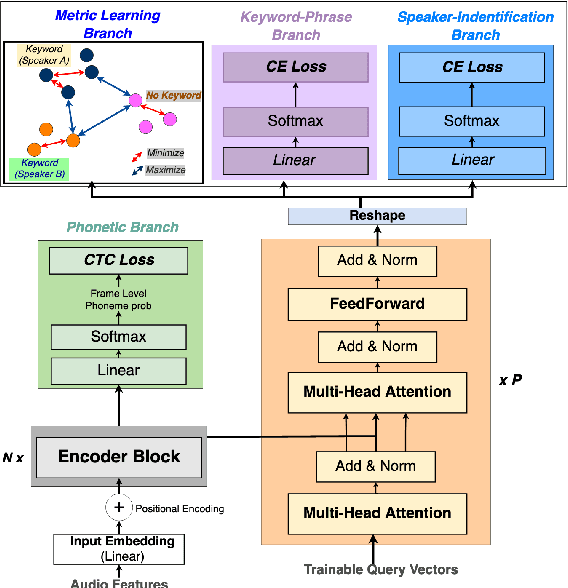

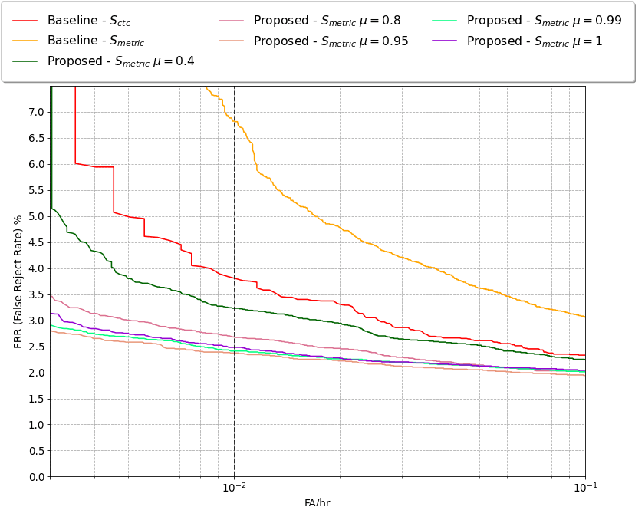
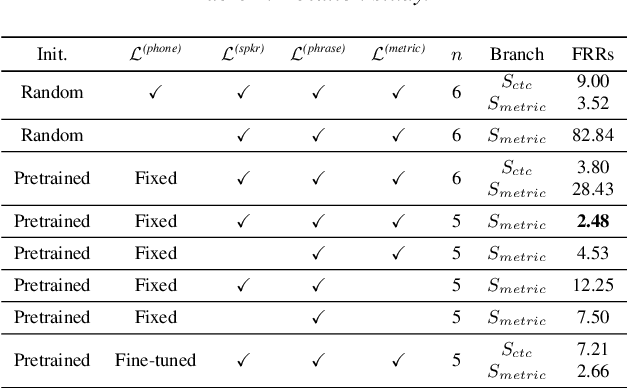
Voice trigger detection is an important task, which enables activating a voice assistant when a target user speaks a keyword phrase. A detector is typically trained on speech data independent of speaker information and used for the voice trigger detection task. However, such a speaker independent voice trigger detector typically suffers from performance degradation on speech from underrepresented groups, such as accented speakers. In this work, we propose a novel voice trigger detector that can use a small number of utterances from a target speaker to improve detection accuracy. Our proposed model employs an encoder-decoder architecture. While the encoder performs speaker independent voice trigger detection, similar to the conventional detector, the decoder predicts a personalized embedding for each utterance. A personalized voice trigger score is then obtained as a similarity score between the embeddings of enrollment utterances and a test utterance. The personalized embedding allows adapting to target speaker's speech when computing the voice trigger score, hence improving voice trigger detection accuracy. Experimental results show that the proposed approach achieves a 38% relative reduction in a false rejection rate (FRR) compared to a baseline speaker independent voice trigger model.
Device-Directed Speech Detection: Regularization via Distillation for Weakly-Supervised Models
Mar 30, 2022


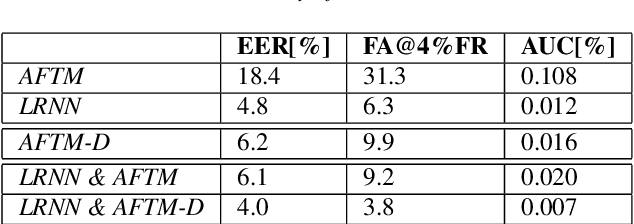
We address the problem of detecting speech directed to a device that does not contain a specific wake-word. Specifically, we focus on audio coming from a touch-based invocation. Mitigating virtual assistants (VAs) activation due to accidental button presses is critical for user experience. While the majority of approaches to false trigger mitigation (FTM) are designed to detect the presence of a target keyword, inferring user intent in absence of keyword is difficult. This also poses a challenge when creating the training/evaluation data for such systems due to inherent ambiguity in the user's data. To this end, we propose a novel FTM approach that uses weakly-labeled training data obtained with a newly introduced data sampling strategy. While this sampling strategy reduces data annotation efforts, the data labels are noisy as the data are not annotated manually. We use these data to train an acoustics-only model for the FTM task by regularizing its loss function via knowledge distillation from an ASR-based (LatticeRNN) model. This improves the model decisions, resulting in 66% gain in accuracy, as measured by equal-error-rate (EER), over the base acoustics-only model. We also show that the ensemble of the LatticeRNN and acoustic-distilled models brings further accuracy improvement of 20%.
CALM: Contrastive Aligned Audio-Language Multirate and Multimodal Representations
Feb 08, 2022Deriving multimodal representations of audio and lexical inputs is a central problem in Natural Language Understanding (NLU). In this paper, we present Contrastive Aligned Audio-Language Multirate and Multimodal Representations (CALM), an approach for learning multimodal representations using contrastive and multirate information inherent in audio and lexical inputs. The proposed model aligns acoustic and lexical information in the input embedding space of a pretrained language-only contextual embedding model. By aligning audio representations to pretrained language representations and utilizing contrastive information between acoustic inputs, CALM is able to bootstrap audio embedding competitive with existing audio representation models in only a few hours of training time. Operationally, audio spectrograms are processed using linearized patches through a Spectral Transformer (SpecTran) which is trained using a Contrastive Audio-Language Pretraining objective to align audio and language from similar queries. Subsequently, the derived acoustic and lexical tokens representations are input into a multimodal transformer to incorporate utterance level context and derive the proposed CALM representations. We show that these pretrained embeddings can subsequently be used in multimodal supervised tasks and demonstrate the benefits of the proposed pretraining steps in terms of the alignment of the two embedding spaces and the multirate nature of the pretraining. Our system shows 10-25\% improvement over existing emotion recognition systems including state-of-the-art three-modality systems under various evaluation objectives.
Whispered and Lombard Neural Speech Synthesis
Jan 13, 2021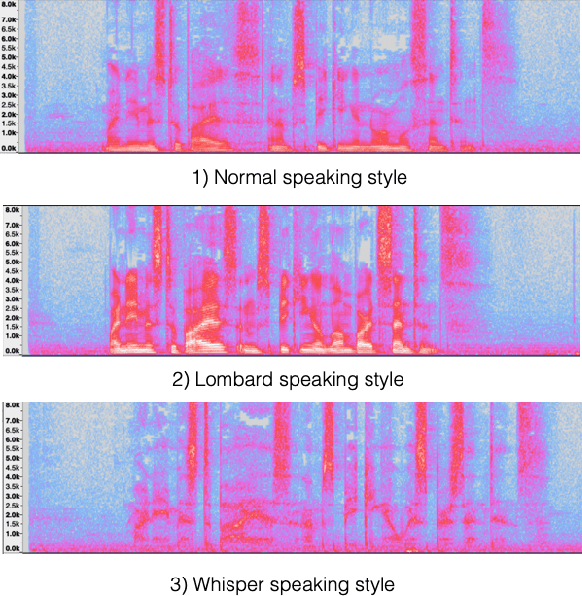

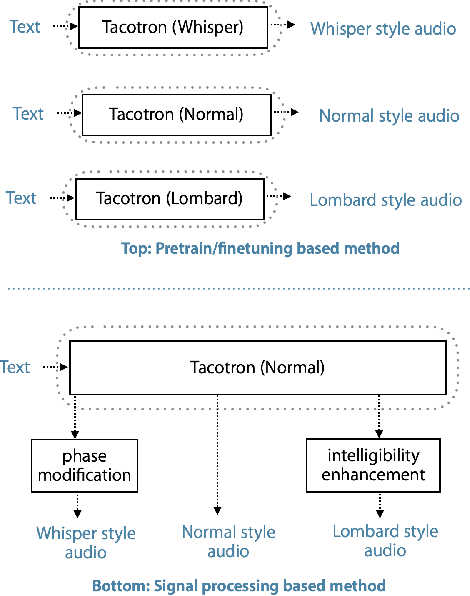
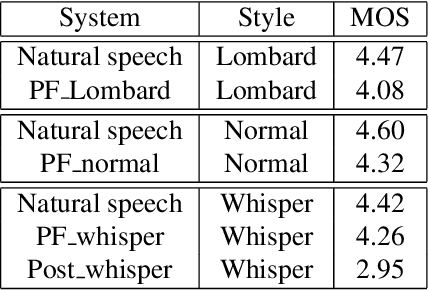
It is desirable for a text-to-speech system to take into account the environment where synthetic speech is presented, and provide appropriate context-dependent output to the user. In this paper, we present and compare various approaches for generating different speaking styles, namely, normal, Lombard, and whisper speech, using only limited data. The following systems are proposed and assessed: 1) Pre-training and fine-tuning a model for each style. 2) Lombard and whisper speech conversion through a signal processing based approach. 3) Multi-style generation using a single model based on a speaker verification model. Our mean opinion score and AB preference listening tests show that 1) we can generate high quality speech through the pre-training/fine-tuning approach for all speaking styles. 2) Although our speaker verification (SV) model is not explicitly trained to discriminate different speaking styles, and no Lombard and whisper voice is used for pre-training this system, the SV model can be used as a style encoder for generating different style embeddings as input for the Tacotron system. We also show that the resulting synthetic Lombard speech has a significant positive impact on intelligibility gain.
Progressive Voice Trigger Detection: Accuracy vs Latency
Oct 29, 2020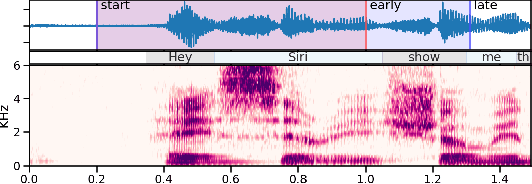
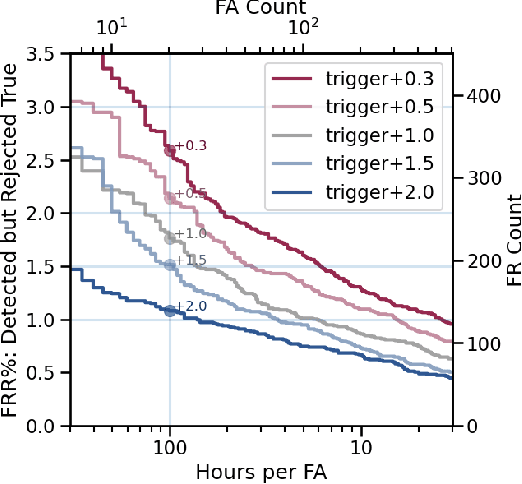
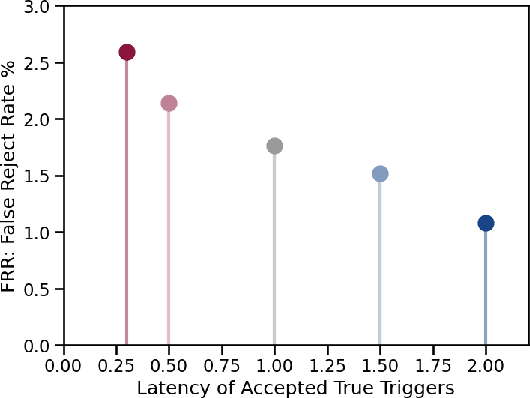
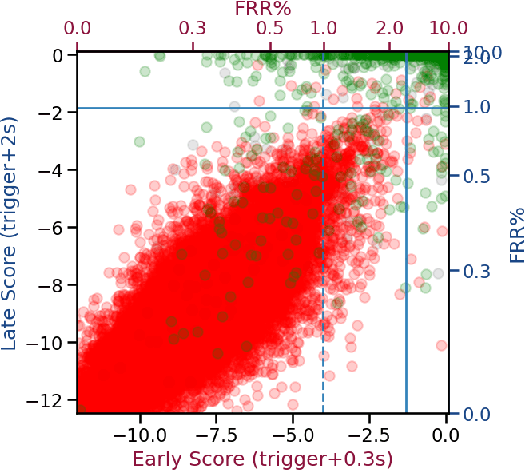
We present an architecture for voice trigger detection for virtual assistants. The main idea in this work is to exploit information in words that immediately follow the trigger phrase. We first demonstrate that by including more audio context after a detected trigger phrase, we can indeed get a more accurate decision. However, waiting to listen to more audio each time incurs a latency increase. Progressive Voice Trigger Detection allows us to trade-off latency and accuracy by accepting clear trigger candidates quickly, but waiting for more context to decide whether to accept more marginal examples. Using a two-stage architecture, we show that by delaying the decision for just 3% of detected true triggers in the test set, we are able to obtain a relative improvement of 66% in false rejection rate, while incurring only a negligible increase in latency.
Knowledge Transfer for Efficient On-device False Trigger Mitigation
Oct 20, 2020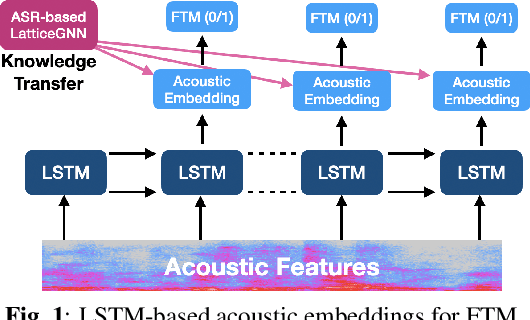

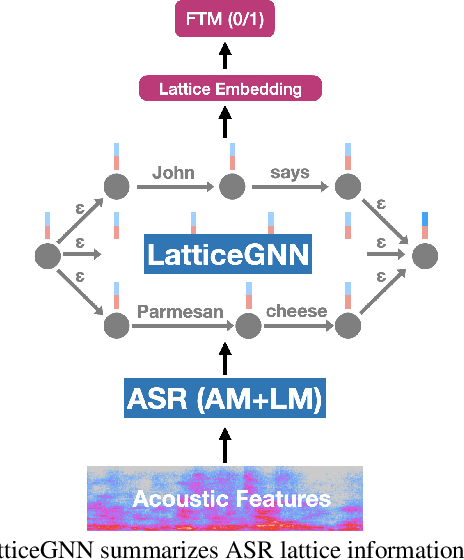
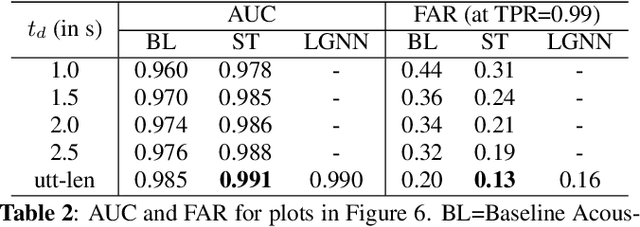
In this paper, we address the task of determining whether a given utterance is directed towards a voice-enabled smart-assistant device or not. An undirected utterance is termed as a "false trigger" and false trigger mitigation (FTM) is essential for designing a privacy-centric non-intrusive smart assistant. The directedness of an utterance can be identified by running automatic speech recognition (ASR) on it and determining the user intent by analyzing the ASR transcript. But in case of a false trigger, transcribing the audio using ASR itself is strongly undesirable. To alleviate this issue, we propose an LSTM-based FTM architecture which determines the user intent from acoustic features directly without explicitly generating ASR transcripts from the audio. The proposed models are small footprint and can be run on-device with limited computational resources. During training, the model parameters are optimized using a knowledge transfer approach where a more accurate self-attention graph neural network model serves as the teacher. Given the whole audio snippets, our approach mitigates 87% of false triggers at 99% true positive rate (TPR), and in a streaming audio scenario, the system listens to only 1.69s of the false trigger audio before rejecting it while achieving the same TPR.
Self-supervised Learning of Visual Speech Features with Audiovisual Speech Enhancement
May 06, 2020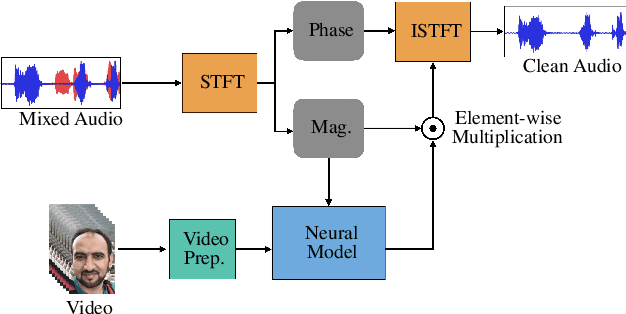
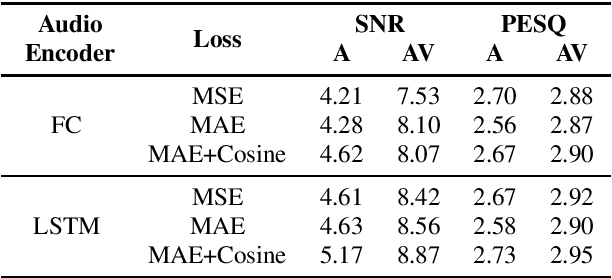
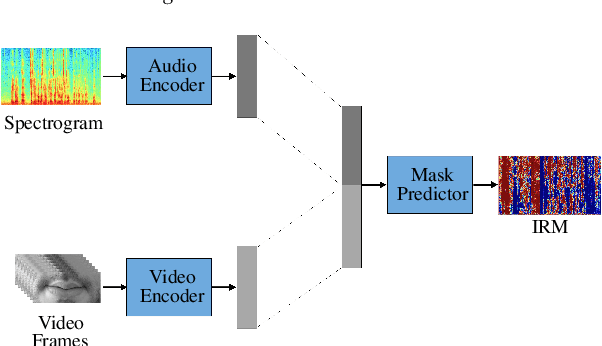
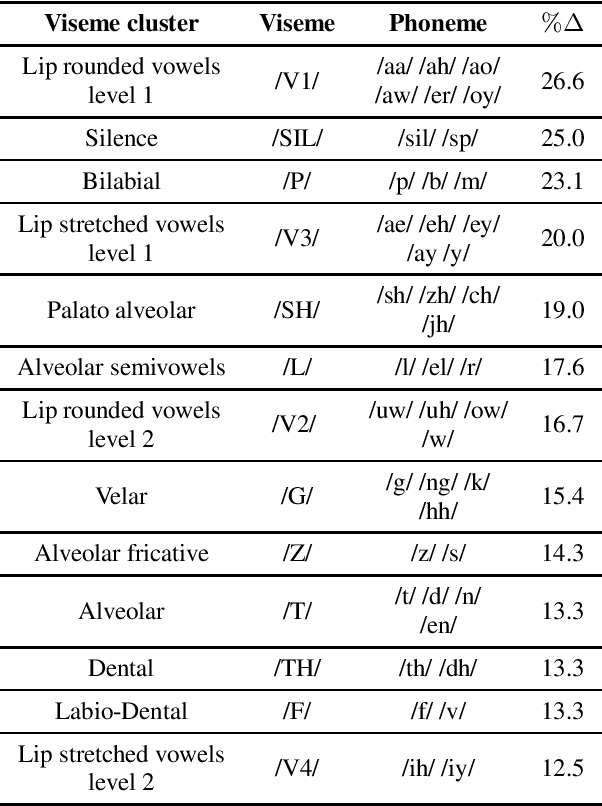
We present an introspection of an audiovisual speech enhancement model. In particular, we focus on interpreting how a neural audiovisual speech enhancement model uses visual cues to improve the quality of the target speech signal. We show that visual features provide not only high-level information about speech activity, i.e. speech vs. no speech, but also fine-grained visual information about the place of articulation. An interesting byproduct of this finding is that the learned visual embeddings can be used as features for other visual speech applications. We demonstrate the effectiveness of the learned visual representations for classifying visemes (the visual analogy to phonemes). Our results provide insight into important aspects of audiovisual speech enhancement and demonstrate how such models can be used for self-supervision tasks for visual speech applications.