 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudiovisual Speech Synthesis using Tacotron2
Aug 03, 2020



Audiovisual speech synthesis is the problem of synthesizing a talking face while maximizing the coherency of the acoustic and visual speech. In this paper, we propose and compare two audiovisual speech synthesis systems for 3D face models. The first system is the AVTacotron2, which is an end-to-end text-to-audiovisual speech synthesizer based on the Tacotron2 architecture. AVTacotron2 converts a sequence of phonemes representing the sentence to synthesize into a sequence of acoustic features and the corresponding controllers of a face model. The output acoustic features are used to condition a WaveRNN to reconstruct the speech waveform, and the output facial controllers are used to generate the corresponding video of the talking face. The second audiovisual speech synthesis system is modular, where acoustic speech is synthesized from text using the traditional Tacotron2. The reconstructed acoustic speech signal is then used to drive the facial controls of the face model using an independently trained audio-to-facial-animation neural network. We further condition both the end-to-end and modular approaches on emotion embeddings that encode the required prosody to generate emotional audiovisual speech. We analyze the performance of the two systems and compare them to the ground truth videos using subjective evaluation tests. The end-to-end and modular systems are able to synthesize close to human-like audiovisual speech with mean opinion scores (MOS) of 4.1 and 3.9, respectively, compared to a MOS of 4.1 for the ground truth generated from professionally recorded videos. While the end-to-end system gives a better overall quality, the modular approach is more flexible and the quality of acoustic speech and visual speech synthesis is almost independent of each other.
Self-supervised Learning of Visual Speech Features with Audiovisual Speech Enhancement
May 06, 2020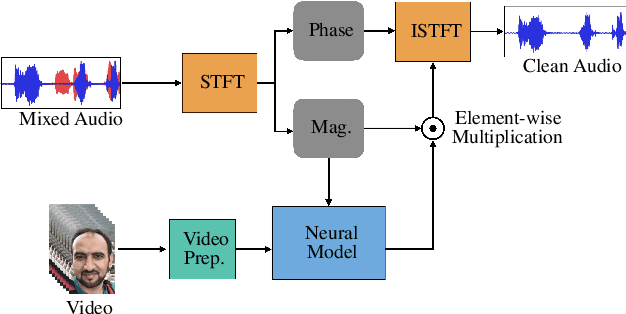
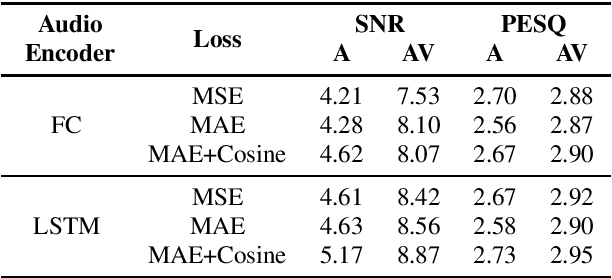
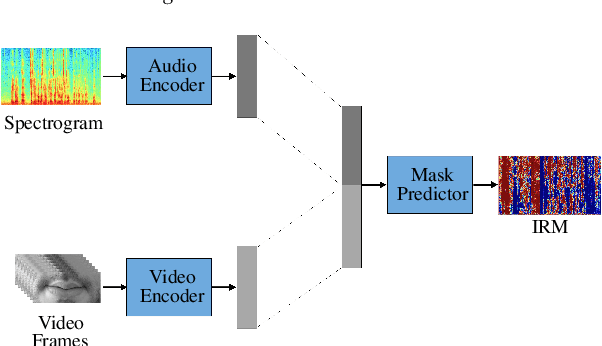
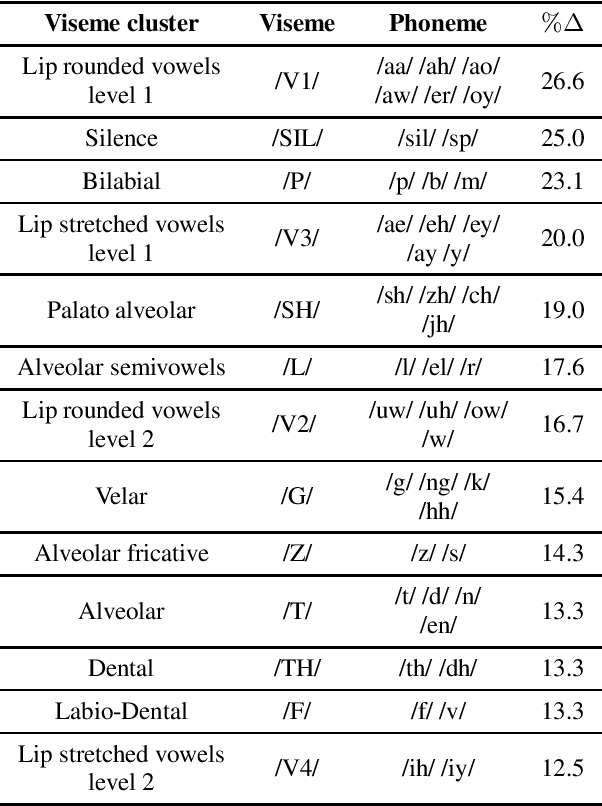
We present an introspection of an audiovisual speech enhancement model. In particular, we focus on interpreting how a neural audiovisual speech enhancement model uses visual cues to improve the quality of the target speech signal. We show that visual features provide not only high-level information about speech activity, i.e. speech vs. no speech, but also fine-grained visual information about the place of articulation. An interesting byproduct of this finding is that the learned visual embeddings can be used as features for other visual speech applications. We demonstrate the effectiveness of the learned visual representations for classifying visemes (the visual analogy to phonemes). Our results provide insight into important aspects of audiovisual speech enhancement and demonstrate how such models can be used for self-supervision tasks for visual speech applications.