 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Review of Agricultural Parcel and Boundary Delineation from Remote Sensing Images: Recent Progress and Future Perspectives
Aug 20, 2025
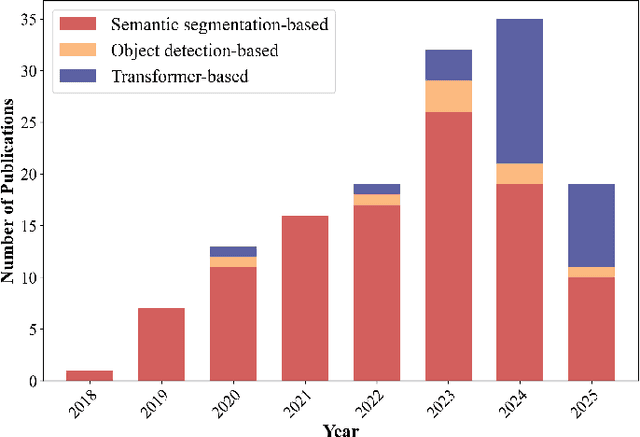


Powered by advances in multiple remote sensing sensors, the production of high spatial resolution images provides great potential to achieve cost-efficient and high-accuracy agricultural inventory and analysis in an automated way. Lots of studies that aim at providing an inventory of the level of each agricultural parcel have generated many methods for Agricultural Parcel and Boundary Delineation (APBD). This review covers APBD methods for detecting and delineating agricultural parcels and systematically reviews the past and present of APBD-related research applied to remote sensing images. With the goal to provide a clear knowledge map of existing APBD efforts, we conduct a comprehensive review of recent APBD papers to build a meta-data analysis, including the algorithm, the study site, the crop type, the sensor type, the evaluation method, etc. We categorize the methods into three classes: (1) traditional image processing methods (including pixel-based, edge-based and region-based); (2) traditional machine learning methods (such as random forest, decision tree); and (3) deep learning-based methods. With deep learning-oriented approaches contributing to a majority, we further discuss deep learning-based methods like semantic segmentation-based, object detection-based and Transformer-based methods. In addition, we discuss five APBD-related issues to further comprehend the APBD domain using remote sensing data, such as multi-sensor data in APBD task, comparisons between single-task learning and multi-task learning in the APBD domain, comparisons among different algorithms and different APBD tasks, etc. Finally, this review proposes some APBD-related applications and a few exciting prospects and potential hot topics in future APBD research. We hope this review help researchers who involved in APBD domain to keep track of its development and tendency.
Cognitive Visual Commonsense Reasoning Using Dynamic Working Memory
Jul 10, 2021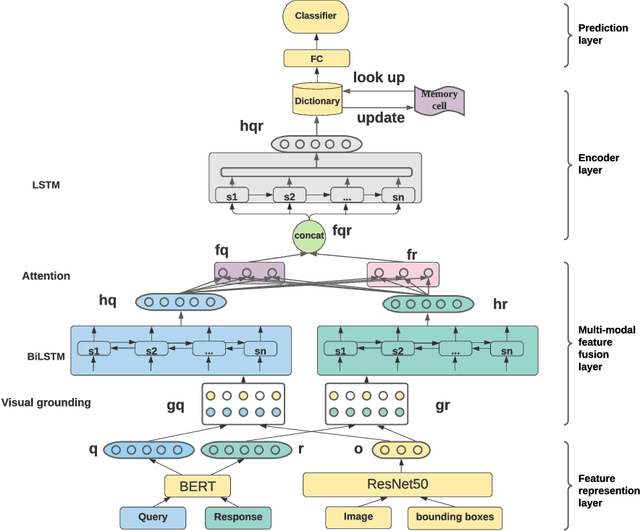
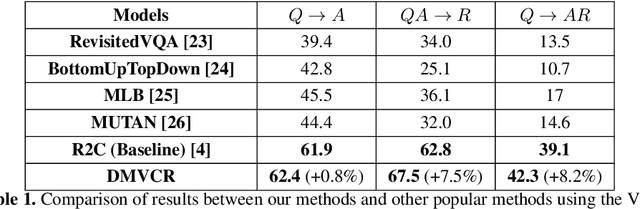
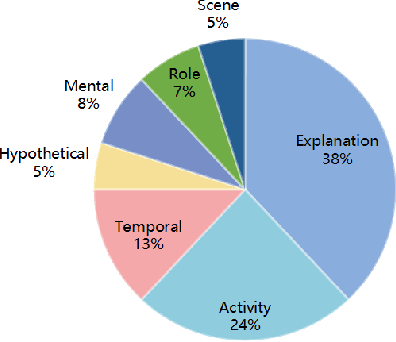

Visual Commonsense Reasoning (VCR) predicts an answer with corresponding rationale, given a question-image input. VCR is a recently introduced visual scene understanding task with a wide range of applications, including visual question answering, automated vehicle systems, and clinical decision support. Previous approaches to solving the VCR task generally rely on pre-training or exploiting memory with long dependency relationship encoded models. However, these approaches suffer from a lack of generalizability and prior knowledge. In this paper we propose a dynamic working memory based cognitive VCR network, which stores accumulated commonsense between sentences to provide prior knowledge for inference. Extensive experiments show that the proposed model yields significant improvements over existing methods on the benchmark VCR dataset. Moreover, the proposed model provides intuitive interpretation into visual commonsense reasoning. A Python implementation of our mechanism is publicly available at https://github.com/tanjatang/DMVCR
Whispered and Lombard Neural Speech Synthesis
Jan 13, 2021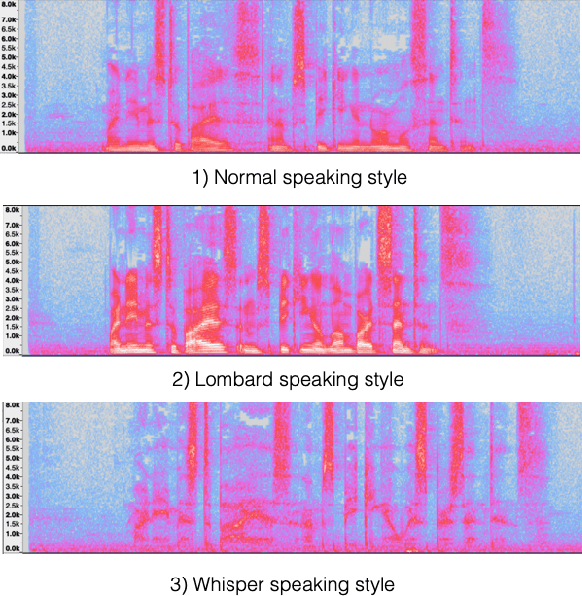

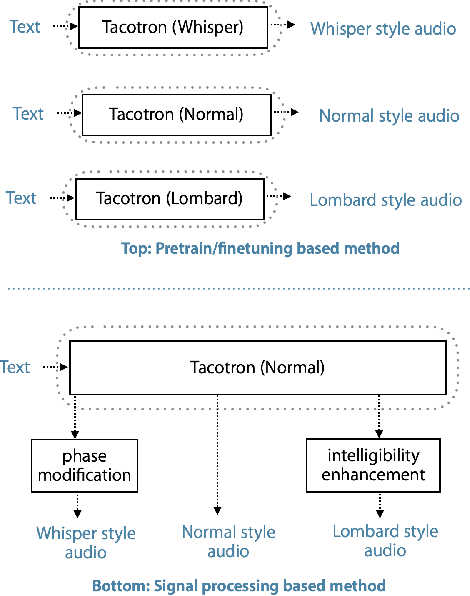
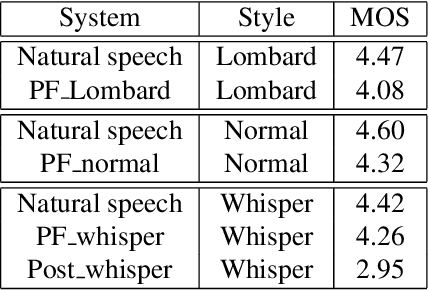
It is desirable for a text-to-speech system to take into account the environment where synthetic speech is presented, and provide appropriate context-dependent output to the user. In this paper, we present and compare various approaches for generating different speaking styles, namely, normal, Lombard, and whisper speech, using only limited data. The following systems are proposed and assessed: 1) Pre-training and fine-tuning a model for each style. 2) Lombard and whisper speech conversion through a signal processing based approach. 3) Multi-style generation using a single model based on a speaker verification model. Our mean opinion score and AB preference listening tests show that 1) we can generate high quality speech through the pre-training/fine-tuning approach for all speaking styles. 2) Although our speaker verification (SV) model is not explicitly trained to discriminate different speaking styles, and no Lombard and whisper voice is used for pre-training this system, the SV model can be used as a style encoder for generating different style embeddings as input for the Tacotron system. We also show that the resulting synthetic Lombard speech has a significant positive impact on intelligibility gain.
Track Facial Points in Unconstrained Videos
Sep 09, 2016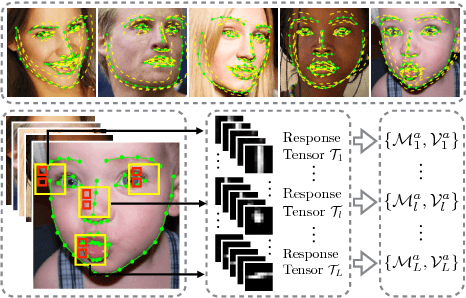

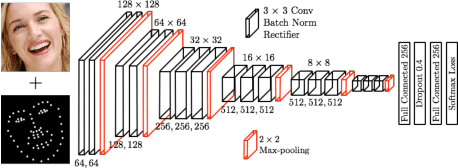

Tracking Facial Points in unconstrained videos is challenging due to the non-rigid deformation that changes over time. In this paper, we propose to exploit incremental learning for person-specific alignment in wild conditions. Our approach takes advantage of part-based representation and cascade regression for robust and efficient alignment on each frame. Unlike existing methods that usually rely on models trained offline, we incrementally update the representation subspace and the cascade of regressors in a unified framework to achieve personalized modeling on the fly. To alleviate the drifting issue, the fitting results are evaluated using a deep neural network, where well-aligned faces are picked out to incrementally update the representation and fitting models. Both image and video datasets are employed to valid the proposed method. The results demonstrate the superior performance of our approach compared with existing approaches in terms of fitting accuracy and efficiency.