 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompact Neural TTS Voices for Accessibility
Jan 28, 2025



Contemporary text-to-speech solutions for accessibility applications can typically be classified into two categories: (i) device-based statistical parametric speech synthesis (SPSS) or unit selection (USEL) and (ii) cloud-based neural TTS. SPSS and USEL offer low latency and low disk footprint at the expense of naturalness and audio quality. Cloud-based neural TTS systems provide significantly better audio quality and naturalness but regress in terms of latency and responsiveness, rendering these impractical for real-world applications. More recently, neural TTS models were made deployable to run on handheld devices. Nevertheless, latency remains higher than SPSS and USEL, while disk footprint prohibits pre-installation for multiple voices at once. In this work, we describe a high-quality compact neural TTS system achieving latency on the order of 15 ms with low disk footprint. The proposed solution is capable of running on low-power devices.
Vocal effort modeling in neural TTS for improving the intelligibility of synthetic speech in noise
Mar 29, 2022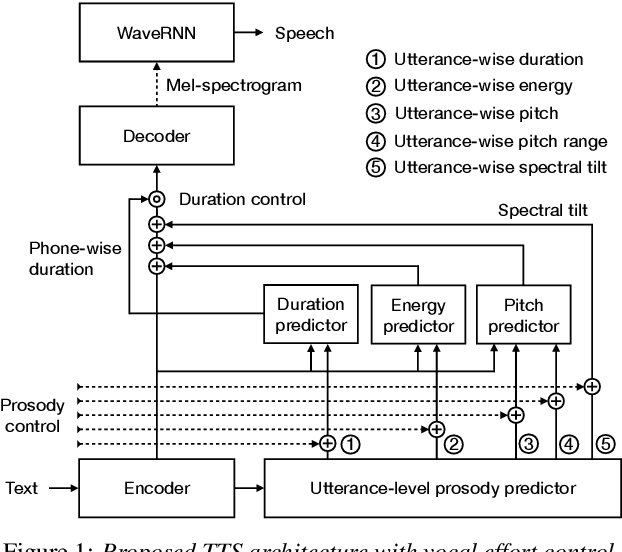
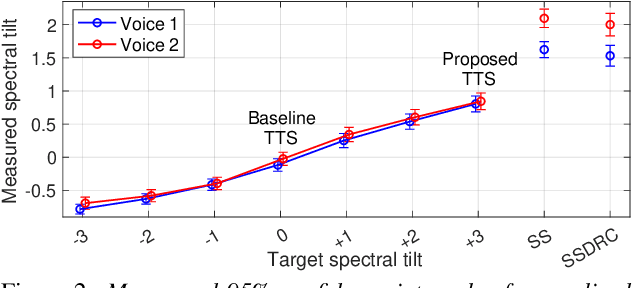
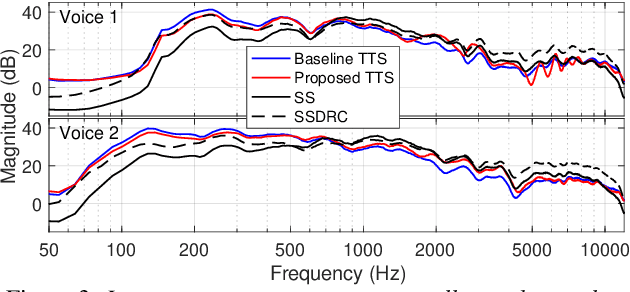
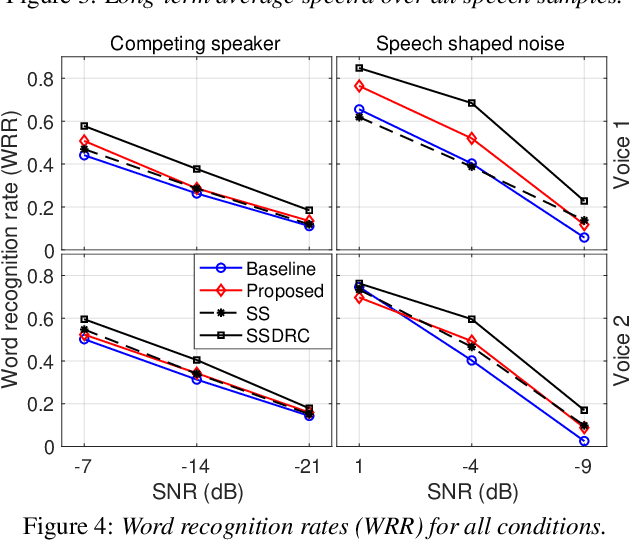
We present a neural text-to-speech (TTS) method that models natural vocal effort variation to improve the intelligibility of synthetic speech in the presence of noise. The method consists of first measuring the spectral tilt of unlabeled conventional speech data, and then conditioning a neural TTS model with normalized spectral tilt among other prosodic factors. Changing the spectral tilt parameter and keeping other prosodic factors unchanged enables effective vocal effort control at synthesis time independent of other prosodic factors. By extrapolation of the spectral tilt values beyond what has been seen in the original data, we can generate speech with high vocal effort levels, thus improving the intelligibility of speech in the presence of masking noise. We evaluate the intelligibility and quality of normal speech and speech with increased vocal effort in the presence of various masking noise conditions, and compare these to well-known speech intelligibility-enhancing algorithms. The evaluations show that the proposed method can improve the intelligibility of synthetic speech with little loss in speech quality.
Whispered and Lombard Neural Speech Synthesis
Jan 13, 2021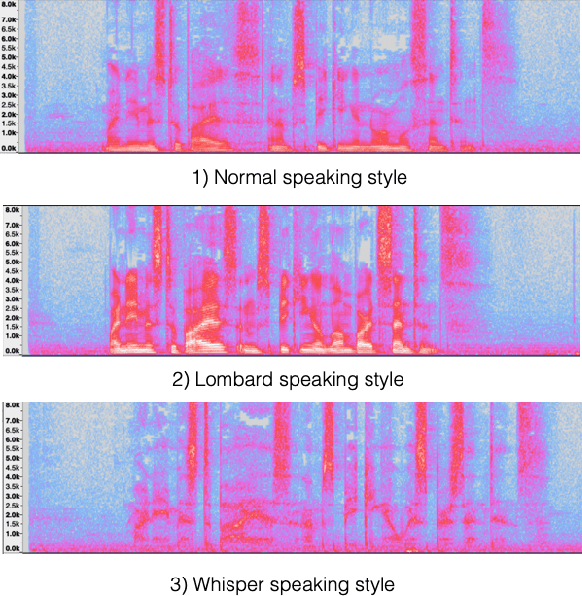

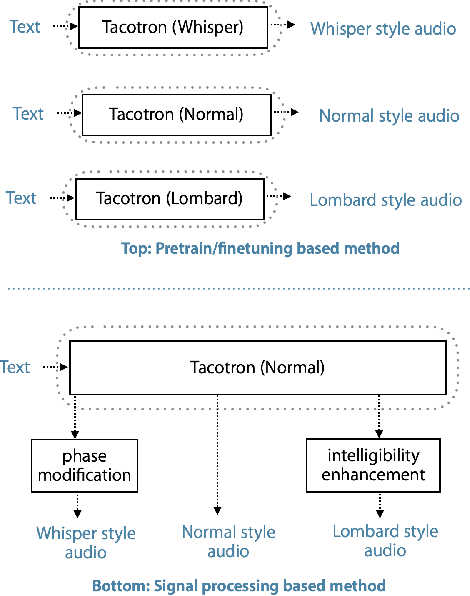
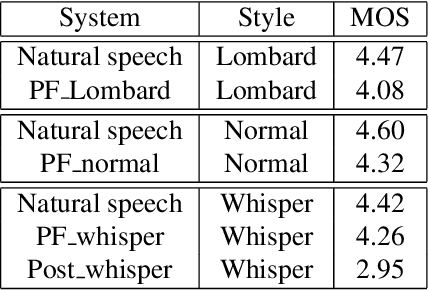
It is desirable for a text-to-speech system to take into account the environment where synthetic speech is presented, and provide appropriate context-dependent output to the user. In this paper, we present and compare various approaches for generating different speaking styles, namely, normal, Lombard, and whisper speech, using only limited data. The following systems are proposed and assessed: 1) Pre-training and fine-tuning a model for each style. 2) Lombard and whisper speech conversion through a signal processing based approach. 3) Multi-style generation using a single model based on a speaker verification model. Our mean opinion score and AB preference listening tests show that 1) we can generate high quality speech through the pre-training/fine-tuning approach for all speaking styles. 2) Although our speaker verification (SV) model is not explicitly trained to discriminate different speaking styles, and no Lombard and whisper voice is used for pre-training this system, the SV model can be used as a style encoder for generating different style embeddings as input for the Tacotron system. We also show that the resulting synthetic Lombard speech has a significant positive impact on intelligibility gain.