 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompact Neural TTS Voices for Accessibility
Jan 28, 2025



Contemporary text-to-speech solutions for accessibility applications can typically be classified into two categories: (i) device-based statistical parametric speech synthesis (SPSS) or unit selection (USEL) and (ii) cloud-based neural TTS. SPSS and USEL offer low latency and low disk footprint at the expense of naturalness and audio quality. Cloud-based neural TTS systems provide significantly better audio quality and naturalness but regress in terms of latency and responsiveness, rendering these impractical for real-world applications. More recently, neural TTS models were made deployable to run on handheld devices. Nevertheless, latency remains higher than SPSS and USEL, while disk footprint prohibits pre-installation for multiple voices at once. In this work, we describe a high-quality compact neural TTS system achieving latency on the order of 15 ms with low disk footprint. The proposed solution is capable of running on low-power devices.
Combining speakers of multiple languages to improve quality of neural voices
Aug 17, 2021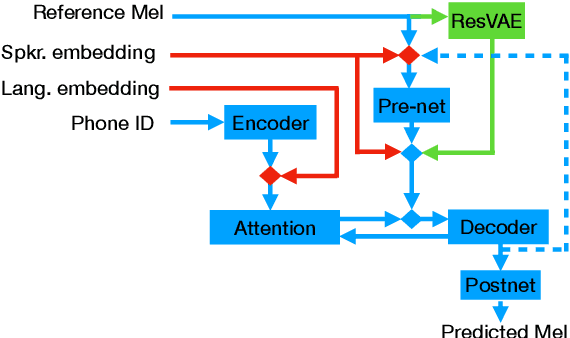

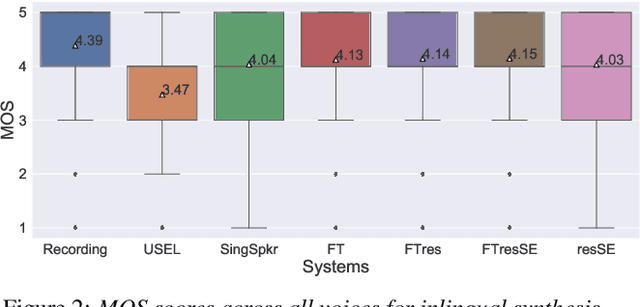
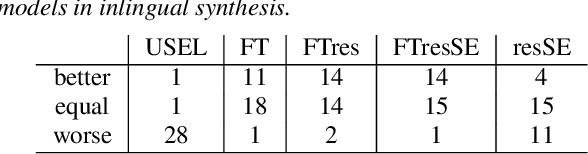
In this work, we explore multiple architectures and training procedures for developing a multi-speaker and multi-lingual neural TTS system with the goals of a) improving the quality when the available data in the target language is limited and b) enabling cross-lingual synthesis. We report results from a large experiment using 30 speakers in 8 different languages across 15 different locales. The system is trained on the same amount of data per speaker. Compared to a single-speaker model, when the suggested system is fine tuned to a speaker, it produces significantly better quality in most of the cases while it only uses less than $40\%$ of the speaker's data used to build the single-speaker model. In cross-lingual synthesis, on average, the generated quality is within $80\%$ of native single-speaker models, in terms of Mean Opinion Score.
Generating Multilingual Voices Using Speaker Space Translation Based on Bilingual Speaker Data
Apr 10, 2020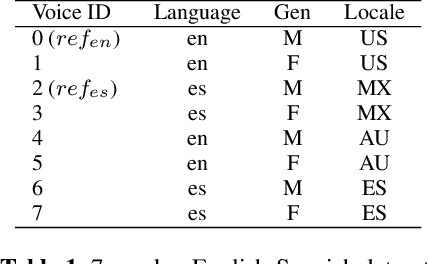
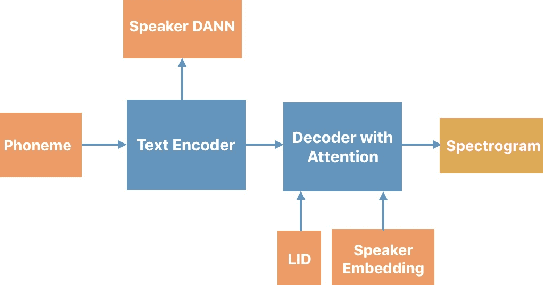

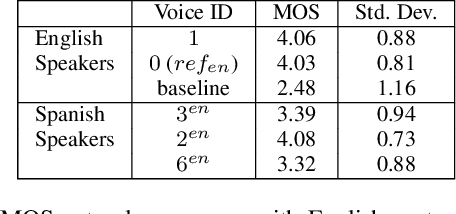
We present progress towards bilingual Text-to-Speech which is able to transform a monolingual voice to speak a second language while preserving speaker voice quality. We demonstrate that a bilingual speaker embedding space contains a separate distribution for each language and that a simple transform in speaker space generated by the speaker embedding can be used to control the degree of accent of a synthetic voice in a language. The same transform can be applied even to monolingual speakers. In our experiments speaker data from an English-Spanish (Mexican) bilingual speaker was used, and the goal was to enable English speakers to speak Spanish and Spanish speakers to speak English. We found that the simple transform was sufficient to convert a voice from one language to the other with a high degree of naturalness. In one case the transformed voice outperformed a native language voice in listening tests. Experiments further indicated that the transform preserved many of the characteristics of the original voice. The degree of accent present can be controlled and naturalness is relatively consistent across a range of accent values.
Scalable Multilingual Frontend for TTS
Apr 10, 2020

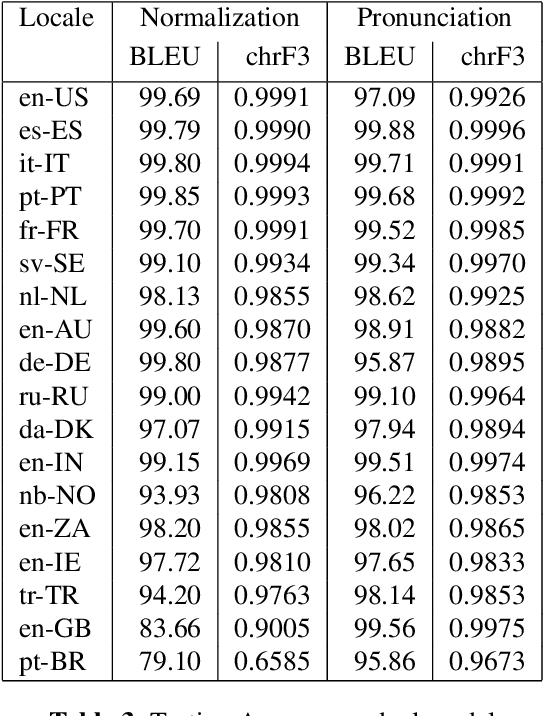
This paper describes progress towards making a Neural Text-to-Speech (TTS) Frontend that works for many languages and can be easily extended to new languages. We take a Machine Translation (MT) inspired approach to constructing the frontend, and model both text normalization and pronunciation on a sentence level by building and using sequence-to-sequence (S2S) models. We experimented with training normalization and pronunciation as separate S2S models and with training a single S2S model combining both functions. For our language-independent approach to pronunciation we do not use a lexicon. Instead all pronunciations, including context-based pronunciations, are captured in the S2S model. We also present a language-independent chunking and splicing technique that allows us to process arbitrary-length sentences. Models for 18 languages were trained and evaluated. Many of the accuracy measurements are above 99%. We also evaluated the models in the context of end-to-end synthesis against our current production system.