 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Multilingual Voices Using Speaker Space Translation Based on Bilingual Speaker Data
Paper and Code
Apr 10, 2020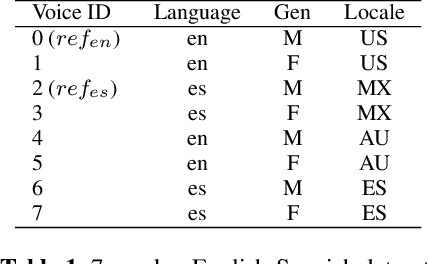
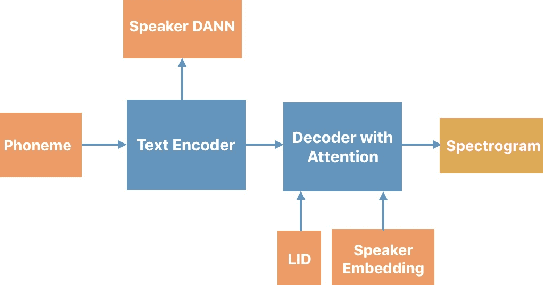

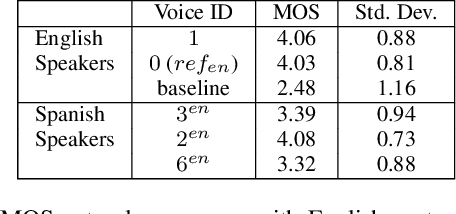
We present progress towards bilingual Text-to-Speech which is able to transform a monolingual voice to speak a second language while preserving speaker voice quality. We demonstrate that a bilingual speaker embedding space contains a separate distribution for each language and that a simple transform in speaker space generated by the speaker embedding can be used to control the degree of accent of a synthetic voice in a language. The same transform can be applied even to monolingual speakers. In our experiments speaker data from an English-Spanish (Mexican) bilingual speaker was used, and the goal was to enable English speakers to speak Spanish and Spanish speakers to speak English. We found that the simple transform was sufficient to convert a voice from one language to the other with a high degree of naturalness. In one case the transformed voice outperformed a native language voice in listening tests. Experiments further indicated that the transform preserved many of the characteristics of the original voice. The degree of accent present can be controlled and naturalness is relatively consistent across a range of accent values.