 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech is More Than Words: Do Speech-to-Text Translation Systems Leverage Prosody?
Oct 31, 2024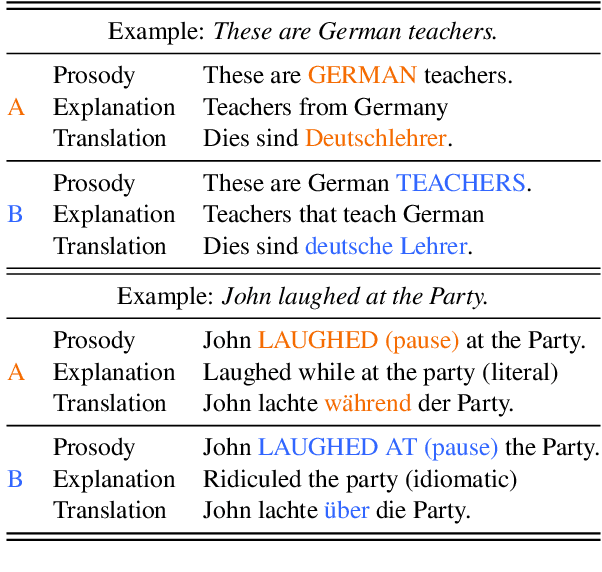
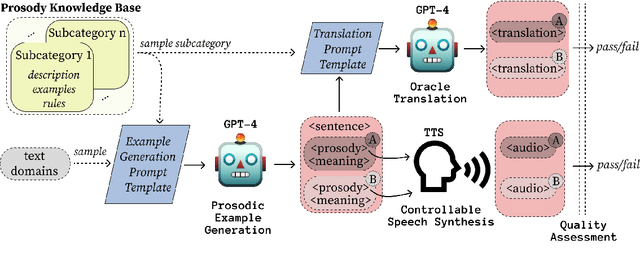

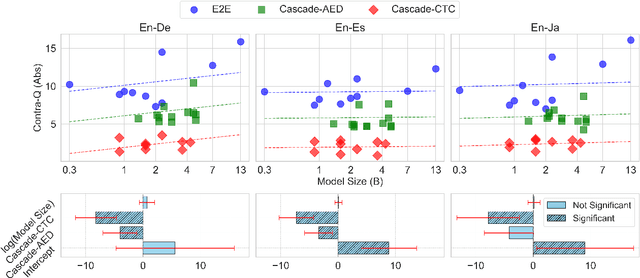
The prosody of a spoken utterance, including features like stress, intonation and rhythm, can significantly affect the underlying semantics, and as a consequence can also affect its textual translation. Nevertheless, prosody is rarely studied within the context of speech-to-text translation (S2TT) systems. In particular, end-to-end (E2E) systems have been proposed as well-suited for prosody-aware translation because they have direct access to the speech signal when making translation decisions, but the understanding of whether this is successful in practice is still limited. A main challenge is the difficulty of evaluating prosody awareness in translation. To address this challenge, we introduce an evaluation methodology and a focused benchmark (named ContraProST) aimed at capturing a wide range of prosodic phenomena. Our methodology uses large language models and controllable text-to-speech (TTS) to generate contrastive examples. Through experiments in translating English speech into German, Spanish, and Japanese, we find that (a) S2TT models possess some internal representation of prosody, but the prosody signal is often not strong enough to affect the translations, (b) E2E systems outperform cascades of speech recognition and text translation systems, confirming their theoretical advantage in this regard, and (c) certain cascaded systems also capture prosodic information in the translation, but only to a lesser extent that depends on the particulars of the transcript's surface form.
Scalable Multilingual Frontend for TTS
Apr 10, 2020

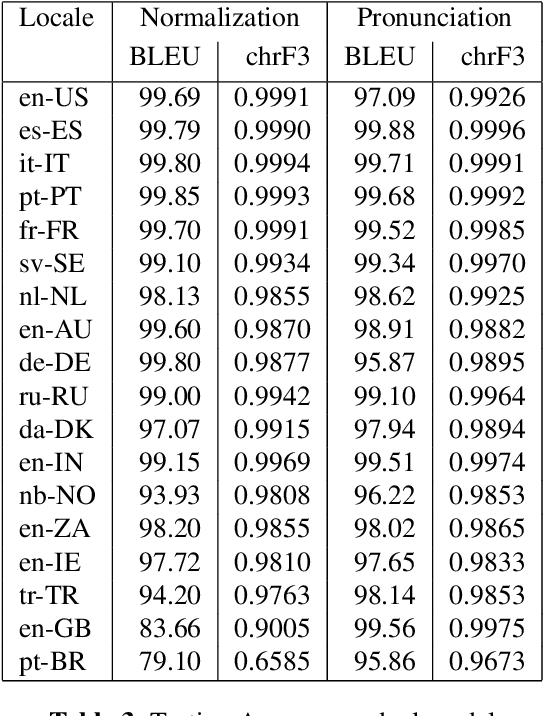
This paper describes progress towards making a Neural Text-to-Speech (TTS) Frontend that works for many languages and can be easily extended to new languages. We take a Machine Translation (MT) inspired approach to constructing the frontend, and model both text normalization and pronunciation on a sentence level by building and using sequence-to-sequence (S2S) models. We experimented with training normalization and pronunciation as separate S2S models and with training a single S2S model combining both functions. For our language-independent approach to pronunciation we do not use a lexicon. Instead all pronunciations, including context-based pronunciations, are captured in the S2S model. We also present a language-independent chunking and splicing technique that allows us to process arbitrary-length sentences. Models for 18 languages were trained and evaluated. Many of the accuracy measurements are above 99%. We also evaluated the models in the context of end-to-end synthesis against our current production system.
Extraction of Templates from Phrases Using Sequence Binary Decision Diagrams
Jan 28, 2020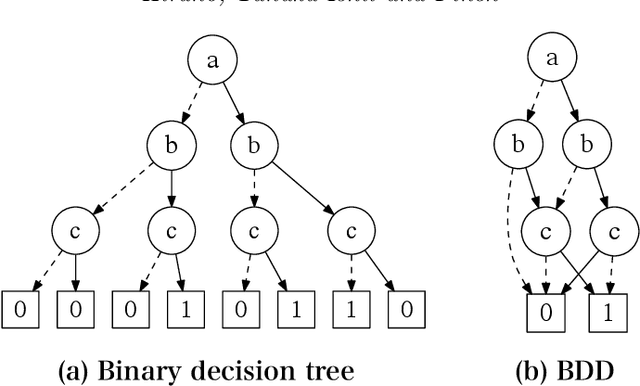


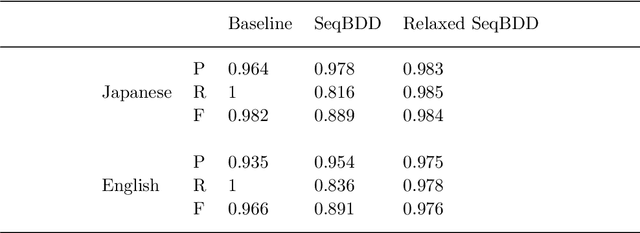
The extraction of templates such as ``regard X as Y'' from a set of related phrases requires the identification of their internal structures. This paper presents an unsupervised approach for extracting templates on-the-fly from only tagged text by using a novel relaxed variant of the Sequence Binary Decision Diagram (SeqBDD). A SeqBDD can compress a set of sequences into a graphical structure equivalent to a minimal DFA, but more compact and better suited to the task of template extraction. The main contribution of this paper is a relaxed form of the SeqBDD construction algorithm that enables it to form general representations from a small amount of data. The process of compression of shared structures in the text during Relaxed SeqBDD construction, naturally induces the templates we wish to extract. Experiments show that the method is capable of high-quality extraction on tasks based on verb+preposition templates from corpora and phrasal templates from short messages from social media.
Findings of the Third Workshop on Neural Generation and Translation
Oct 30, 2019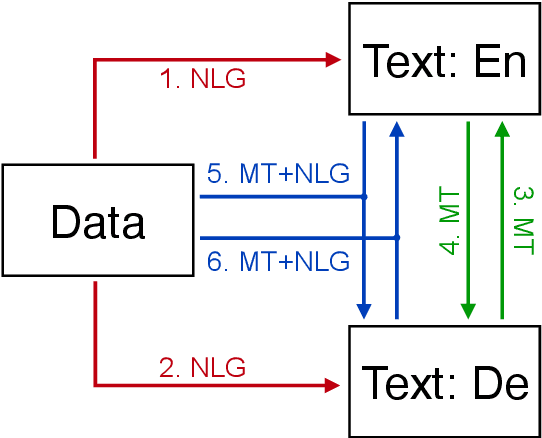
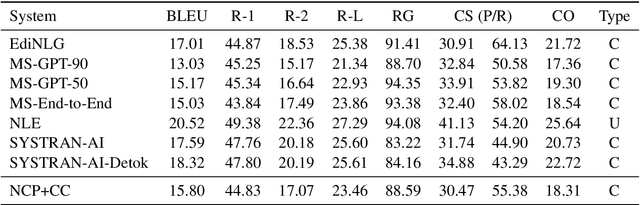
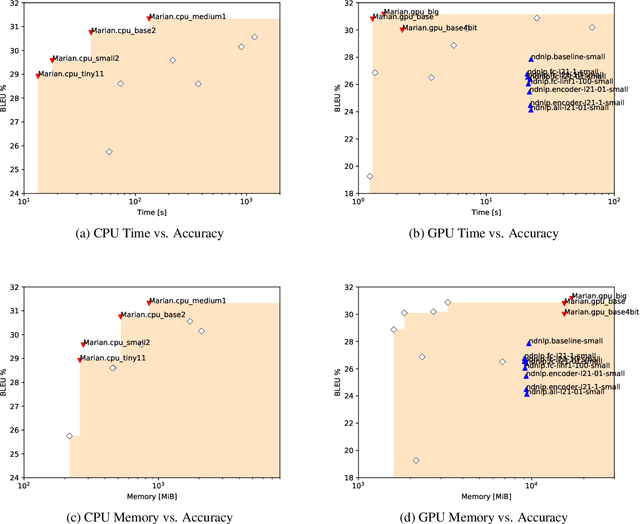
This document describes the findings of the Third Workshop on Neural Generation and Translation, held in concert with the annual conference of the Empirical Methods in Natural Language Processing (EMNLP 2019). First, we summarize the research trends of papers presented in the proceedings. Second, we describe the results of the two shared tasks 1) efficient neural machine translation (NMT) where participants were tasked with creating NMT systems that are both accurate and efficient, and 2) document-level generation and translation (DGT) where participants were tasked with developing systems that generate summaries from structured data, potentially with assistance from text in another language.
Findings of the Second Workshop on Neural Machine Translation and Generation
Jun 18, 2018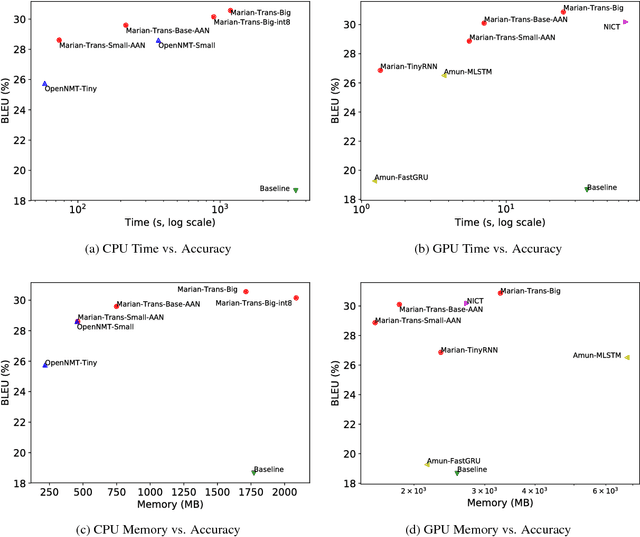
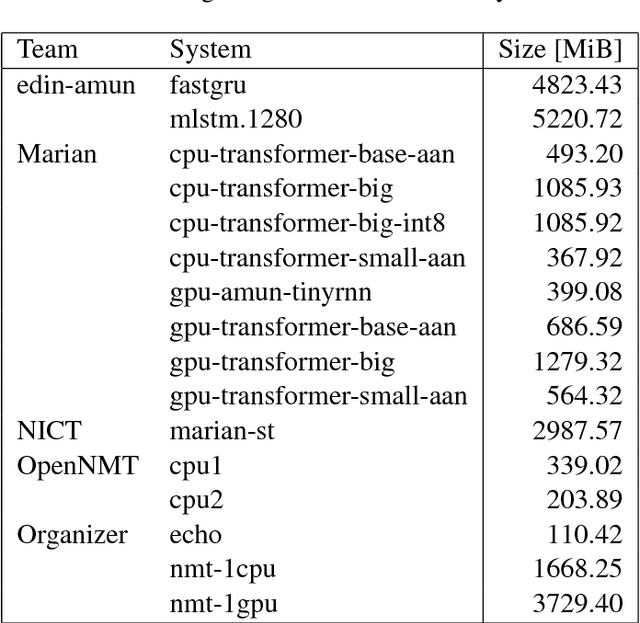
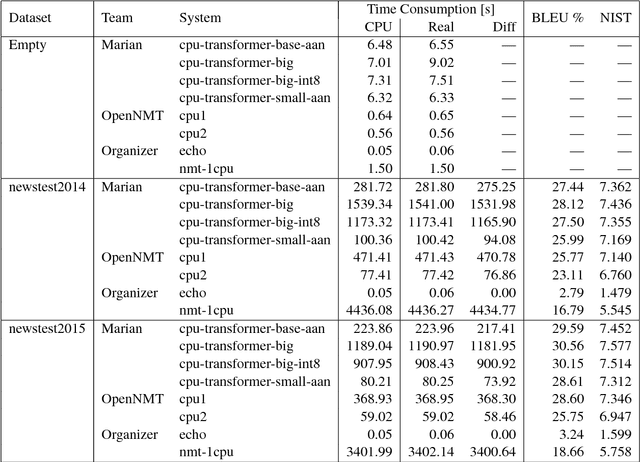
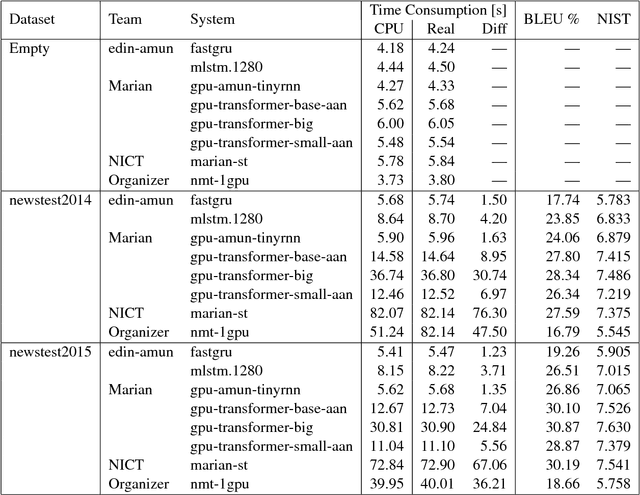
This document describes the findings of the Second Workshop on Neural Machine Translation and Generation, held in concert with the annual conference of the Association for Computational Linguistics (ACL 2018). First, we summarize the research trends of papers presented in the proceedings, and note that there is particular interest in linguistic structure, domain adaptation, data augmentation, handling inadequate resources, and analysis of models. Second, we describe the results of the workshop's shared task on efficient neural machine translation, where participants were tasked with creating MT systems that are both accurate and efficient.
Neural Machine Translation with Supervised Attention
Sep 14, 2016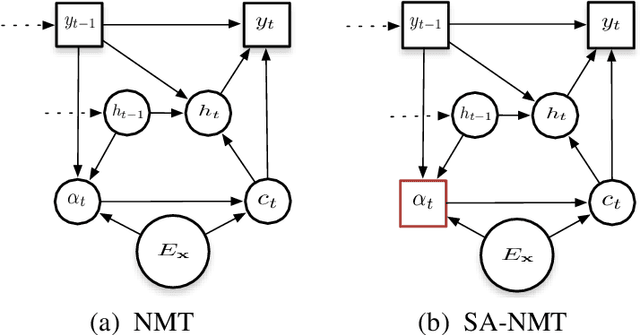


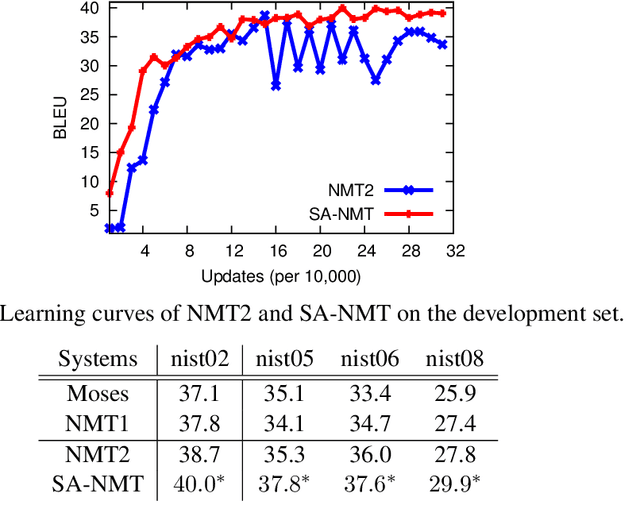
The attention mechanisim is appealing for neural machine translation, since it is able to dynam- ically encode a source sentence by generating a alignment between a target word and source words. Unfortunately, it has been proved to be worse than conventional alignment models in aligment accuracy. In this paper, we analyze and explain this issue from the point view of re- ordering, and propose a supervised attention which is learned with guidance from conventional alignment models. Experiments on two Chinese-to-English translation tasks show that the super- vised attention mechanism yields better alignments leading to substantial gains over the standard attention based NMT.