 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtificial intelligence is creating a new global linguistic hierarchy
Feb 12, 2026Artificial intelligence (AI) has the potential to transform healthcare, education, governance and socioeconomic equity, but its benefits remain concentrated in a small number of languages (Bender, 2019; Blasi et al., 2022; Joshi et al., 2020; Ranathunga and de Silva, 2022; Young, 2015). Language AI - the technologies that underpin widely-used conversational systems such as ChatGPT - could provide major benefits if available in people's native languages, yet most of the world's 7,000+ linguistic communities currently lack access and face persistent digital marginalization. Here we present a global longitudinal analysis of social, economic and infrastructural conditions across languages to assess systemic inequalities in language AI. We first analyze the existence of AI resources for 6003 languages. We find that despite efforts of the community to broaden the reach of language technologies (Bapna et al., 2022; Costa-Jussà et al., 2022), the dominance of a handful of languages is exacerbating disparities on an unprecedented scale, with divides widening exponentially rather than narrowing. Further, we contrast the longitudinal diffusion of AI with that of earlier IT technologies, revealing a distinctive hype-driven pattern of spread. To translate our findings into practical insights and guide prioritization efforts, we introduce the Language AI Readiness Index (EQUATE), which maps the state of technological, socio-economic, and infrastructural prerequisites for AI deployment across languages. The index highlights communities where capacity exists but remains underutilized, and provides a framework for accelerating more equitable diffusion of language AI. Our work contributes to setting the baseline for a transition towards more sustainable and equitable language technologies.
Information-Theoretic Generative Clustering of Documents
Dec 18, 2024We present {\em generative clustering} (GC) for clustering a set of documents, $\mathrm{X}$, by using texts $\mathrm{Y}$ generated by large language models (LLMs) instead of by clustering the original documents $\mathrm{X}$. Because LLMs provide probability distributions, the similarity between two documents can be rigorously defined in an information-theoretic manner by the KL divergence. We also propose a natural, novel clustering algorithm by using importance sampling. We show that GC achieves the state-of-the-art performance, outperforming any previous clustering method often by a large margin. Furthermore, we show an application to generative document retrieval in which documents are indexed via hierarchical clustering and our method improves the retrieval accuracy.
Correlation Dimension of Natural Language in a Statistical Manifold
May 10, 2024The correlation dimension of natural language is measured by applying the Grassberger-Procaccia algorithm to high-dimensional sequences produced by a large-scale language model. This method, previously studied only in a Euclidean space, is reformulated in a statistical manifold via the Fisher-Rao distance. Language exhibits a multifractal, with global self-similarity and a universal dimension around 6.5, which is smaller than those of simple discrete random sequences and larger than that of a Barab\'asi-Albert process. Long memory is the key to producing self-similarity. Our method is applicable to any probabilistic model of real-world discrete sequences, and we show an application to music data.
* Published at Physical Review Research
Statistical Mechanics of Strahler Number via Random and Natural Language Sentences
Jul 06, 2023The Strahler number was originally proposed to characterize the complexity of river bifurcation and has found various applications. This article proposes computation of the Strahler number's upper and lower limits for natural language sentence tree structures, which are available in a large dataset allowing for statistical mechanics analysis. Through empirical measurements across grammatically annotated data, the Strahler number of natural language sentences is shown to be almost always 3 or 4, similar to the case of river bifurcation as reported by Strahler (1957) and Horton (1945). From the theory behind the number, we show that it is the lower limit of the amount of memory required to process sentences under a particular model. A mathematical analysis of random trees provides a further conjecture on the nature of the Strahler number, revealing that it is not a constant but grows logarithmically. This finding uncovers the statistical basics behind the Strahler number as a characteristic of a general tree structure target.
A Comparison of Two Fluctuation Analyses for Natural Language Clustering Phenomena: Taylor and Ebeling & Neiman Methods
Sep 14, 2020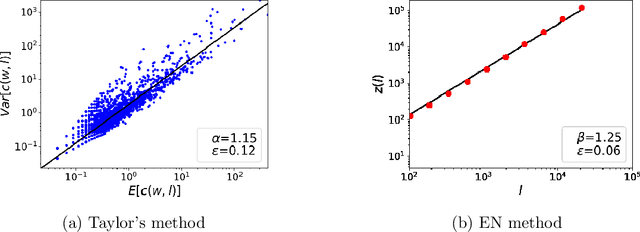
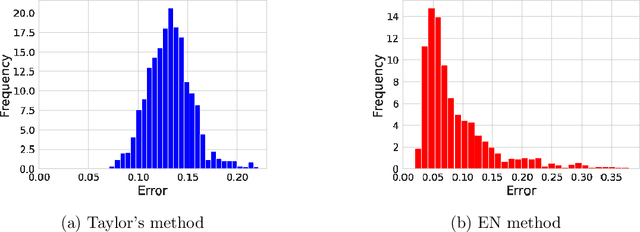
This article considers the fluctuation analysis methods of Taylor and Ebeling & Neiman. While both have been applied to various phenomena in the statistical mechanics domain, their similarities and differences have not been clarified. After considering their analytical aspects, this article presents a large-scale application of these methods to text. It is found that both methods can distinguish real text from independently and identically distributed (i.i.d.) sequences. Furthermore, it is found that the Taylor exponents acquired from words can roughly distinguish text categories; this is also the case for Ebeling and Neiman exponents, but to a lesser extent. Additionally, both methods show some possibility of capturing script kinds.
Extraction of Templates from Phrases Using Sequence Binary Decision Diagrams
Jan 28, 2020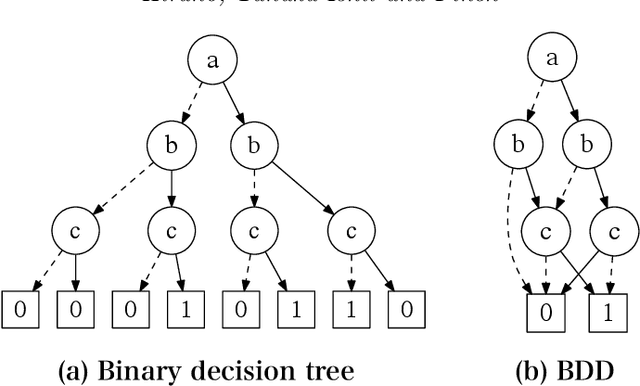


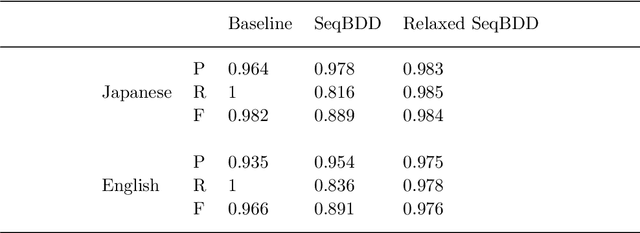
The extraction of templates such as ``regard X as Y'' from a set of related phrases requires the identification of their internal structures. This paper presents an unsupervised approach for extracting templates on-the-fly from only tagged text by using a novel relaxed variant of the Sequence Binary Decision Diagram (SeqBDD). A SeqBDD can compress a set of sequences into a graphical structure equivalent to a minimal DFA, but more compact and better suited to the task of template extraction. The main contribution of this paper is a relaxed form of the SeqBDD construction algorithm that enables it to form general representations from a small amount of data. The process of compression of shared structures in the text during Relaxed SeqBDD construction, naturally induces the templates we wish to extract. Experiments show that the method is capable of high-quality extraction on tasks based on verb+preposition templates from corpora and phrasal templates from short messages from social media.
Evaluating Computational Language Models with Scaling Properties of Natural Language
Jun 22, 2019In this article, we evaluate computational models of natural language with respect to the universal statistical behaviors of natural language. Statistical mechanical analyses have revealed that natural language text is characterized by scaling properties, which quantify the global structure in the vocabulary population and the long memory of a text. We study whether five scaling properties (given by Zipf's law, Heaps' law, Ebeling's method, Taylor's law, and long-range correlation analysis) can serve for evaluation of computational models. Specifically, we test $n$-gram language models, a probabilistic context-free grammar (PCFG), language models based on Simon/Pitman-Yor processes, neural language models, and generative adversarial networks (GANs) for text generation. Our analysis reveals that language models based on recurrent neural networks (RNNs) with a gating mechanism (i.e., long short-term memory, LSTM; a gated recurrent unit, GRU; and quasi-recurrent neural networks, QRNNs) are the only computational models that can reproduce the long memory behavior of natural language. Furthermore, through comparison with recently proposed model-based evaluation methods, we find that the exponent of Taylor's law is a good indicator of model quality.
Word Familiarity and Frequency
Jun 09, 2018
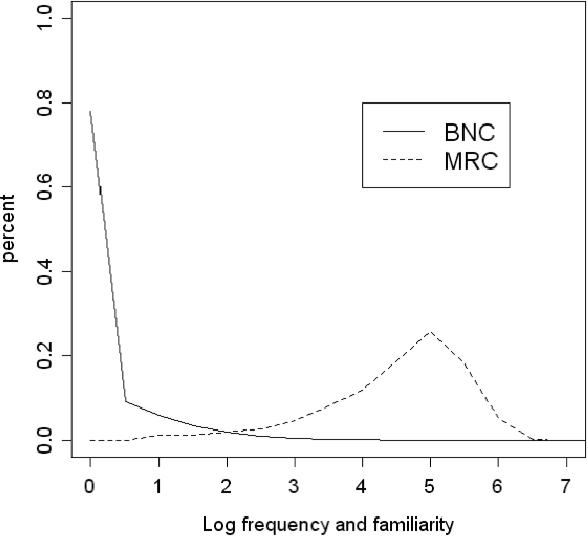

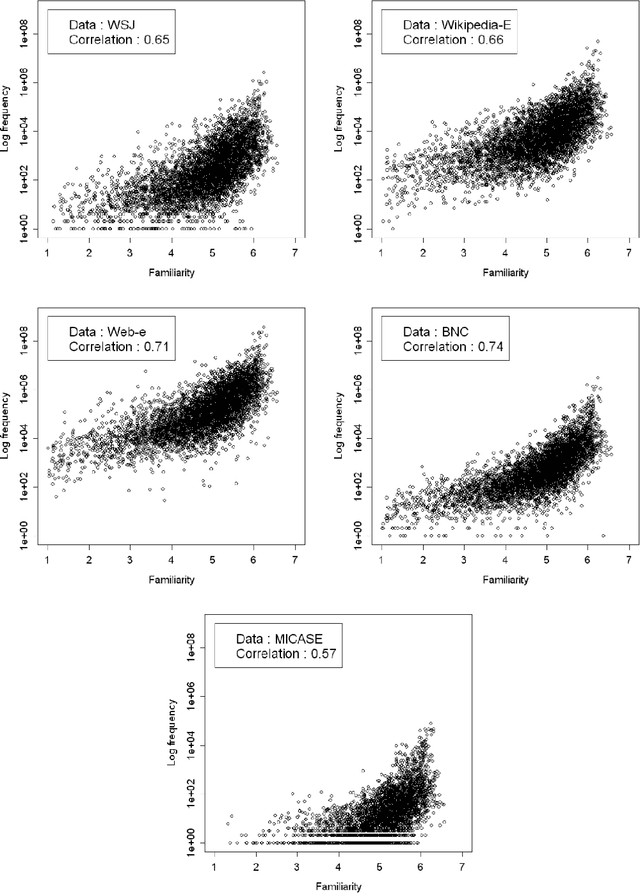
Word frequency is assumed to correlate with word familiarity, but the strength of this correlation has not been thoroughly investigated. In this paper, we report on our analysis of the correlation between a word familiarity rating list obtained through a psycholinguistic experiment and the log-frequency obtained from various corpora of different kinds and sizes (up to the terabyte scale) for English and Japanese. Major findings are threefold: First, for a given corpus, familiarity is necessary for a word to achieve high frequency, but familiar words are not necessarily frequent. Second, correlation increases with the corpus data size. Third, a corpus of spoken language correlates better than one of written language. These findings suggest that cognitive familiarity ratings are correlated to frequency, but more highly to that of spoken rather than written language.
Taylor's law for Human Linguistic Sequences
Jun 07, 2018
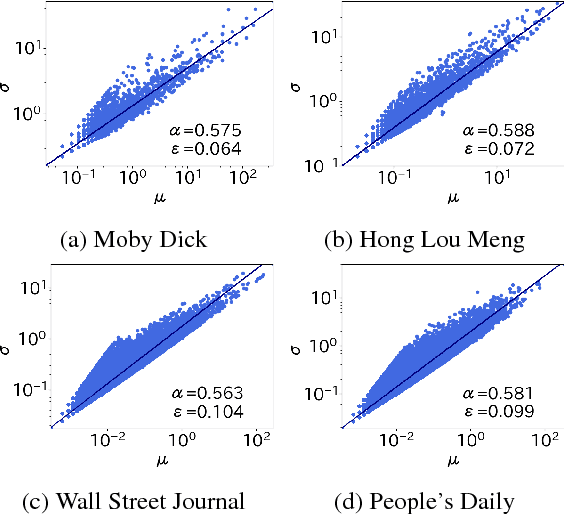

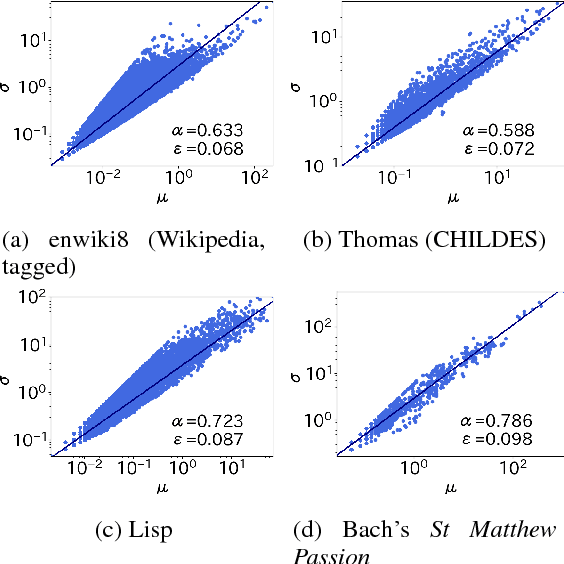
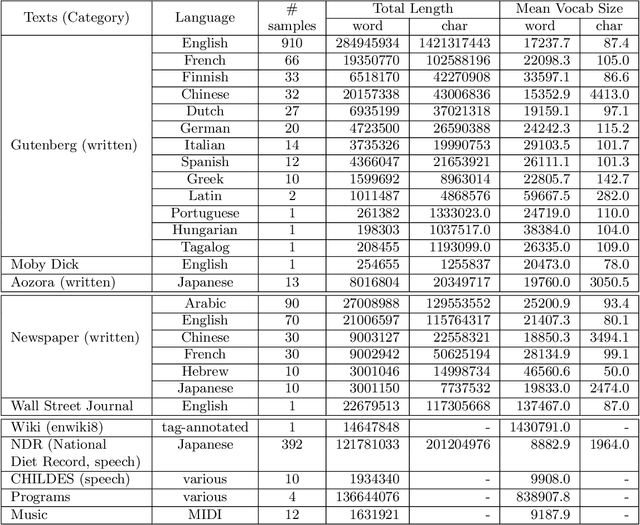
Taylor's law describes the fluctuation characteristics underlying a system in which the variance of an event within a time span grows by a power law with respect to the mean. Although Taylor's law has been applied in many natural and social systems, its application for language has been scarce. This article describes a new quantification of Taylor's law in natural language and reports an analysis of over 1100 texts across 14 languages. The Taylor exponents of written natural language texts were found to exhibit almost the same value. The exponent was also compared for other language-related data, such as the child-directed speech, music, and programming language code. The results show how the Taylor exponent serves to quantify the fundamental structural complexity underlying linguistic time series. The article also shows the applicability of these findings in evaluating language models.
Assessing Language Models with Scaling Properties
Apr 24, 2018
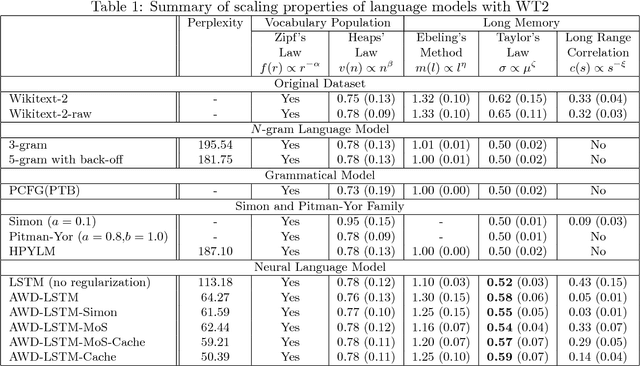
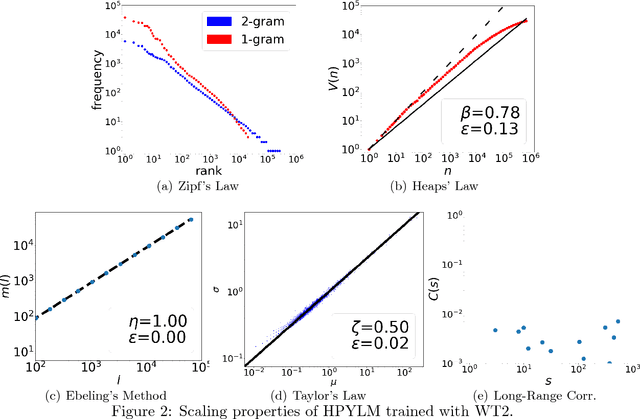
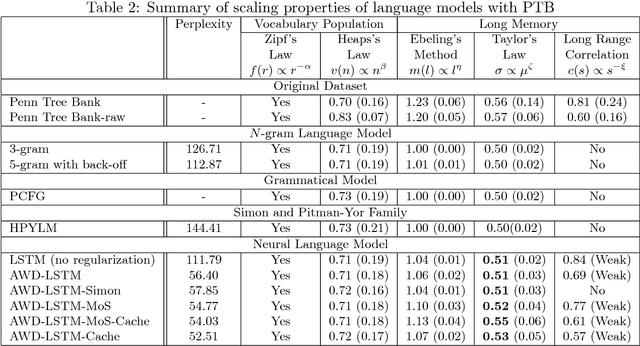
Language models have primarily been evaluated with perplexity. While perplexity quantifies the most comprehensible prediction performance, it does not provide qualitative information on the success or failure of models. Another approach for evaluating language models is thus proposed, using the scaling properties of natural language. Five such tests are considered, with the first two accounting for the vocabulary population and the other three for the long memory of natural language. The following models were evaluated with these tests: n-grams, probabilistic context-free grammar (PCFG), Simon and Pitman-Yor (PY) processes, hierarchical PY, and neural language models. Only the neural language models exhibit the long memory properties of natural language, but to a limited degree. The effectiveness of every test of these models is also discussed.